 671
671 
Содержание
- Предшественники и их ограничения: Почему Transformer был необходим
- Глубокий разбор архитектуры Transformer
- Positional Encoding (Позиционное кодирование)
- Внутри блоков: Что такое "Нормализация" и "Связи"?
- Блок Декодера: Хитрость с "Маской"
- Принцип работы: "Внимание" (Attention) как вычислительное ядро
- Self-Attention (Само-внимание)
- Multi-Head Attention (Многоголовочное внимание)
- Сценарии использования и "Семейства" моделей Transformer
- Взаимодействие: Применение Transformer на практике
- Преимущества, ограничения и эволюция Transformer
- Заключение
- Референсные ссылки
Transformer (Трансформер) — это архитектура нейронных сетей, основанная на механизме внимания (attention), который позволяет модели выбирать и сопоставлять важные части входных данных между собой, эффективно обрабатывая последовательности (например, текст) параллельно, что делает их основой современных систем обработки естественного языка и генеративных ИИ-моделей. Самый очевидный пример — это машинный перевод, где Transformer берет предложение на одном языке (последовательность 1) и превращает его в предложение на другом языке (последовательность 2).
Фундаментальный прорыв Transformer заключается в том, как он решает две главные проблемы, которые «мучили» все предыдущие модели.
- Проблема длинного контекста. Как модели понять, что слово в конце абзаца связано со словом в самом начале?
- Проблема скорости обучения. Старые модели были ужасно медленными, так как им приходилось обрабатывать слова одно за другим.
Transformer решил обе эти проблемы, полностью отказавшись от старого подхода (рекурсии) и построив всю свою работу на одном мощном механизме — «внимании» (Attention). Вместо того чтобы читать текст по одному слову, Transformer «смотрит» на все слова в предложении одновременно и сам решает, какие из них наиболее важны для понимания смысла каждого конкретного слова.
Предшественники и их ограничения: Почему Transformer был необходим
Чтобы понять, почему Transformer стал революцией, нужно посмотреть, с чем специалистам приходилось работать раньше. Долгое время главной технологией для работы с текстом были рекуррентные нейронные сети (RNN).
Их логика была простой и понятной: они читали предложение так же, как человек — слово за словом, слева направо. Прочитав слово, RNN «запоминал» его и учитывал эту память, когда читал следующее слово. Это было хорошо для коротких фраз. Но как только предложение становилось длиннее, начинались проблемы.
Представьте игру в «испорченный телефон». Первый человек говорит фразу, второй передает ее третьему, и так далее. К десятому участнику исходный смысл полностью теряется. Это в точности то, что происходило в RNN. Когда сеть читала длинный абзац, к концу она уже «забывала», с чего все началось. В науке это называется «проблемой исчезающих градиентов» — сигнал из начала просто не «дотекал» до конца.
Позже появились более продвинутые версии — LSTM (Long Short-Term Memory, Долгая Краткосрочная Память) и GRU. Это были очень умные RNN, у которых были специальные «гейты» (вентили). Они могли решать, какую информацию «забыть», а какую — сохранить и пронести через всю последовательность. Это было огромное улучшение, и они до сих L-пор используются. Но главную проблему они не решили.
Фундаментальный недостаток и RNN, и LSTM — последовательные вычисления. Они обязаны были обрабатывать слова по одному. Нельзя было обработать пятое слово, не обработав до этого четвертое. Это означало, что мы не могли использовать всю мощь современных видеокарт (GPU), которые созданы для того, чтобы делать тысячи вычислений параллельно. Обучение таких моделей на гигантских объемах данных занимало недели или даже месяцы.
Глубокий разбор архитектуры Transformer
Transformer предложил радикальное решение: «Давайте вообще откажемся от последовательной обработки. Давайте посмотрим на все слова сразу и дадим модели самой решать, что с чем связано».
На высоком уровне классический Transformer состоит из двух частей, как бы из двух «башен»:
- Encoder (Энкодер): Его задача — «прочитать» входное предложение (например, на русском) и построить для него богатое смысловое представление. Он не просто запоминает слова, он понимает контекст каждого слова.
- Decoder (Декодер): Его задача — взять это смысловое представление от Энкодера и, используя его, «написать» выходное предложение (например, на английском), тоже слово за словом.
Обе эти «башни» внутри состоят из стопки одинаковых блоков, прямо как конструктор LEGO. Обычно это 6 или 12 блоков, установленных друг на друга.
Positional Encoding (Позиционное кодирование)
Первая проблема, которая возникает, если «смотреть на все слова сразу», — это потеря порядка. Для модели Transformer предложение «Собака укусила человека» и «Человека укусила собака» — это просто мешок одинаковых слов. Она не знает, кто где стоял.
Чтобы решить эту проблему, на входе к каждому слову «приклеивается» специальная метка — Positional Encoding. Это как добавить GPS-координаты к каждому слову. Это не просто номер (1, 2, 3), а хитрый математический вектор (созданный с помощью синусов и косинусов), который дает модели понять не только где слово стоит, но и насколько далеко оно от других слов. Теперь, даже получив все слова разом, модель знает их точный порядок.
Внутри блоков: Что такое «Нормализация» и «Связи»?
Когда мы смотрим на схемы Transformer, мы видим не только «Внимание» и «Feed-Forward», но и два других важных элемента: Residual Connections и Layer Normalization. Для новичка они кажутся скучными, но без них ничего бы не работало.
- Residual Connections (Остаточные связи): Представьте, что вы учите модель чему-то сложному. Легко «перемудрить» и сделать только хуже. Эта связь — простой трюк: мы берем вход блока и добавляем его к выходу. Это как сказать модели: «Вот твой результат, но на всякий случай, вот что было до тебя». Это помогает сигналу (градиенту) беспрепятственно «протекать» через десятки слоев, не «затухая».
- Layer Normalization (Нормализация слоя): В процессе вычислений числа внутри нейросети могут становиться то очень большими, то очень маленькими. Это «сводит модель с ума» и дестабилизирует обучение. Нормализация — это как «привести чувства в порядок». Она берет все числа на выходе слоя и «успокаивает» их, приводя к стандартному диапазону (например, со средним 0). Это делает обучение намного более плавным и предсказуемым.
Блок Декодера: Хитрость с «Маской»
Декодер устроен похоже на Энкодер, но с одним ключевым отличием. Когда мы переводим предложение, мы генерируем его слово за словом. И когда мы генерируем, скажем, третье слово, мы не должны видеть, какими будут четвертое, пятое и т.д. Мы не можем «заглядывать в будущее».
Для этого в Декодере используется Masked Multi-Head Attention (Маскированное внимание). Это обычный механизм внимания, но на него как бы надели «шоры». «Маска» принудительно зануляет всю информацию о словах, которые находятся справа от текущего. Это гарантирует, что при генерации ответа модель опирается только на то, что она уже сказала, а не на будущие слова.
Принцип работы: «Внимание» (Attention) как вычислительное ядро
Итак, мы добрались до самого сердца Transformer. Как он «смотрит» на все слова и решает, что важно? Через механизм Scaled Dot-Product Attention.
Звучит страшно, но интуиция очень простая. Давайте представим «внимание» на аналогии с поиском в YouTube.
Вы хотите найти информацию. У вас есть три компонента:
- Query (Q, Запрос): Это ваша мысль, то, что вы печатаете в строке поиска. Например, «милые котики«.
- Key (K, Ключ): Это заголовки всех видео на платформе. «Смешные котики», «Как построить дом», «Лекция по Transformer».
- Value (V, Значение): Это само видео, которое скрывается за заголовком.
Что делает механизм Attention?
- Шаг 1: Найти релевантность. Он берет ваш Запрос («милые котики») и по очереди сравнивает его с каждым Ключом (заголовком). Он вычисляет «оценку совместимости». «Милые котики» + «Смешные котики» = Оценка 0.9. «Милые котики» + «Как построить дом» = Оценка 0.1.
- Шаг 2: Взвесить. После того как у нас есть оценки, мы их нормализуем (с помощью функции Softmax), чтобы в сумме они давали 1. Это наши «веса» или «коэффициенты внимания». «Милые котики» получат 90% нашего внимания, а «Как построить дом» — 1%.
- Шаг 3: Получить результат. Мы берем эти веса и умножаем их на Значения (сами видео). 90% от видео «Милые котики» + 1% от видео «Как построить дом» и т.д.
На выходе мы получаем «коктейль» из всех видео, но в нем будет 90% контента про котиков и почти ничего про строительство.
ИИ-агенты для оптимизации бизнес-процессов
Код курса
AGENT
Ближайшая дата курса
18 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
Self-Attention (Само-внимание)
В Transformer этот механизм используется хитро. Он называется Self-Attention (Само-внимание). Здесь предложение «смотрит» само на себя.
Представьте предложение: «Машина не могла въехать в гараж, потому что она была слишком узкой«.
Чтобы понять, к чему относится слово «она«, модель делает вот что:
- Для слова «она» создается Запрос (Query).
- Для каждого слова в предложении («Машина», «не», «могла», «гараж», «она», «узкой») создаются Ключи (Keys) и Значения (Values).
- Модель сравнивает Запрос от «она» с Ключами всех остальных слов.
- Она обнаруживает, что Ключ от слова «гараж» и «узкой» очень совместимы с Запросом от «она«.
- В итоге, при формировании нового, «контекстного» представления для слова «она», модель «подмешает» в него очень много Значения от слова «гараж» и «узкой». (В данном случае, если бы было «широкой», то к «машине»).
Multi-Head Attention (Многоголовочное внимание)
Что, если одного «взгляда» недостаточно? Слово «она» может быть связано со словом «машина» (кто?), но также и со словом «въехать» (что делала?).
Разработчики Transformer придумали Multi-Head Attention (Многоголовочное внимание). Вместо того чтобы делать один «поиск» (один набор Q, K, V), они запускают 8 или 12 «поисков» параллельно.
Это как если бы у вас было 8 ассистентов. Вы даете им одно и то же предложение и просите:
- Ассистент 1: «Найди мне связь между действиями и субъектами».
- Ассистент 2: «Найди мне связь между местоимениями и существительными».
- Ассистент 3: «Найди, какие слова описывают время».
- …и так далее.
Каждая «голова» учится искать свой, особый тип связей в тексте. Затем их результаты собираются вместе, и модель получает невероятно богатое, многогранное понимание контекста, которое было недоступно одному «вниманию».
Сценарии использования и «Семейства» моделей Transformer
Эта гибкая архитектура (Энкодер + Декодер) породила три основных «семейства» моделей, которые мы используем сегодня:
- Encoder-only (Только Энкодер): BERT, RoBERTa.
Эти модели — мастера понимания текста. Их обучают, давая им текст с «пробелами» (пропущенными словами), и их задача — угадать, что там должно было стоять. Так как они «смотрят» на текст сразу в обе стороны (вперед и назад), они идеально подходят для анализа тональности, классификации и поиска ответов на вопросы. - Decoder-only (Только Декодер): GPT (вся серия), LLaMA.
Это мастера генерации текста. Их обучают предсказывать следующее слово в предложении. Это те самые модели, которые лежат в основе ChatGPT. Так как они авторегрессионные (используют «маску», чтобы не видеть будущее), они отлично пишут статьи, код и ведут диалог. - Encoder-Decoder (Полные): T5, BART.
Это классические модели для задач «преобразования» (seq-to-seq). Они хороши там, где нужно что-то «прочитать», а затем «переписать»: машинный перевод и автоматическое суммирование (сокращение) текстов.
Взаимодействие: Применение Transformer на практике
Самое приятное, что сегодня не нужно быть гением математики, чтобы использовать всю эту мощь. Благодаря библиотекам, таким как Hugging Face Transformers, начать работу можно за 10 минут.
Для начала нужно установить библиотеку (обычно через pip):
pip install transformers
Самый простой способ «потрогать» Transformer — использовать pipeline. Это инструмент, который прячет под капот всю сложность. При этом вам возможно придется установить PyTorch или TensorFlow, так как Transformer это только оболочка для токенизации, загрузки моделей и абстракции, но модель должна работать внутри backend.
Нейронные сети на Python
Код курса
PYNN
Ближайшая дата курса
10 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
from transformers import pipeline
# Загружаем готовый pipeline для анализа тональности
# Он сам скачает нужную модель (BERT-подобную)
sentiment_analyzer = pipeline("sentiment-analysis", model="rubert-base-cased-sentiment")
# Подаем ему текст на русском
result = sentiment_analyzer("Я в восторге от этой новой архитектуры!")
print(result)
# Вывод: [{'label': 'positive', 'score': 0.99...}]
result_neg = sentiment_analyzer("Мне не понравилась эта статья, она слишком сложная.")
print(result_neg)
# Вывод: [{'label': 'negative', 'score': 0.97...}]
Пример 1:
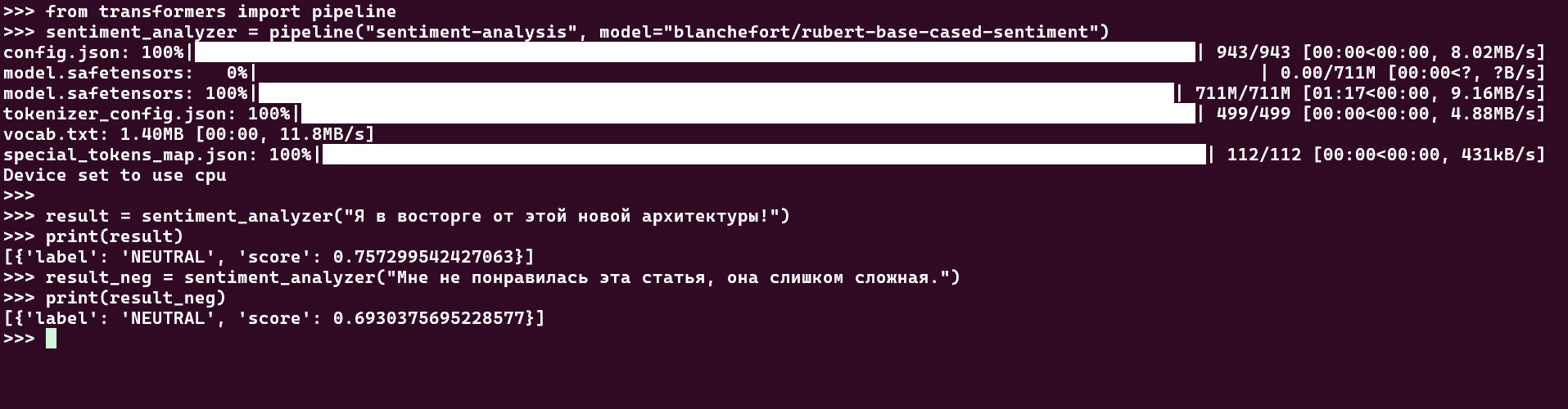
Пример 2: Изменим модель так как модель показывает нейтральные результаты для данного текста на русском
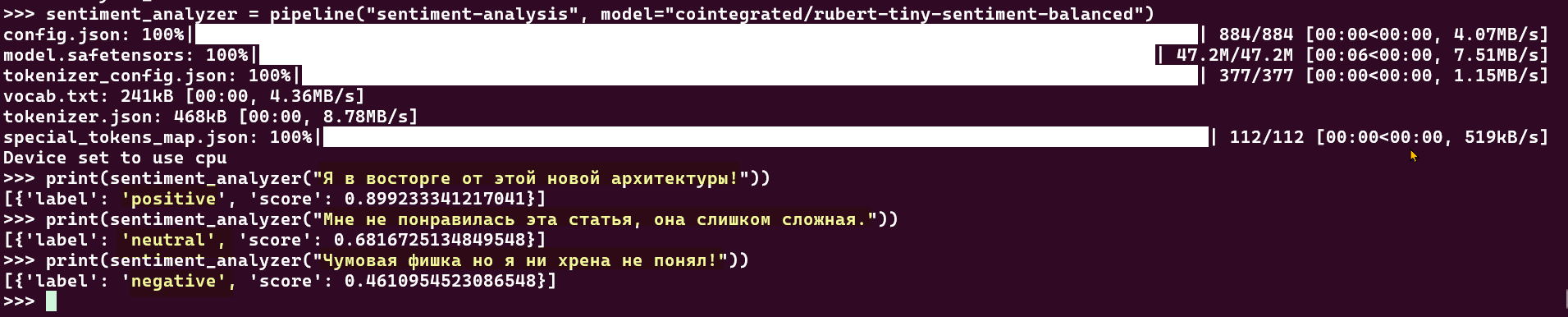
Если хочется чуть больше контроля, можно поработать с моделью напрямую. Процесс всегда состоит из двух шагов:
- Токенизатор (Tokenizer): Он превращает ваш текст в понятные для модели числа (ID токенов).
- Модель (Model): Она принимает эти числа и выполняет вычисления.
from transformers import AutoTokenizer, AutoModelForSequenceClassification # Укажем ту же модель, что и в pipeline model_name = "rubert-base-cased-sentiment" # Шаг 1: Загружаем токенизатор tokenizer = AutoTokenizer.from_pretrained(model_name) # Шаг 2: Загружаем саму модель model = AutoModelForSequenceClassification.from_pretrained(model_name) # Готовим наш текст text = "Я в восторге от этой новой архитектуры!" # Токенизатор превращает текст в ID и добавляет "маски внимания" inputs = tokenizer(text, return_tensors="pt") # Подаем ID в модель outputs = model(**inputs) # Модель выдает "сырые" логиты, которые нужно прогнать через Softmax # ... (здесь чуть сложнее, чем в pipeline, но это и есть контроль) print(outputs.logits)
Преимущества, ограничения и эволюция Transformer
Два главных «супер-качества» Transformer очевидны.
- Параллелизм: В отличие от RNN, Transformer обрабатывает все слова предложения за один «проход». Это идеально ложится на архитектуру GPU и позволяет нам обучать гигантские модели, о которых раньше нельзя было и мечтать.
- Длинные зависимости: Механизм Self-Attention напрямую связывает любые два слова в тексте, независимо от расстояния. Проблема «испорченного телефона» решена.
Но у Transformer есть и своя «ахиллесова пята» — квадратичная сложность (O(n²)). Что это значит «на пальцах»? Механизм внимания, как мы помним, должен сравнить каждое слово с каждым другим словом.
- Если в предложении 10 слов, нужно сделать 10×10 = 100 сравнений.
- Если в предложении 100 слов, нужно 100×100 = 10 000 сравнений.
- Если в документе 1000 слов, нужно 1000×1000 = 1 000 000 сравнений.
Стоимость вычислений (и требуемая память) растет не линейно, а квадратично с длиной последовательности. Это делает стандартный Transformer ужасно неэффективным для обработки длинных текстов, вроде целых книг или научных статей. Модели просто «не хватает» памяти на такую гигантскую «матрицу внимания».
Вся современная разработка в области Transformer — это, по сути, борьба с этой O(n²) проблемой. Появилось целое «семейство» более эффективных Transformer-ов:
- Longformer: Использует «скользящее» окно внимания, глядя только на ближайших соседей.
- Reformer: Использует хитрое хэширование, чтобы находить «похожие» слова и сравнивать только их.
- Linformer: Доказывает, что матрицу внимания можно аппроксимировать (упростить) без большой потери качества, снижая сложность до линейной.
Заключение
Transformer — это не просто очередная модель, а фундаментальный сдвиг в том, как мы подходим к машинному обучению. Он предложил новый вычислительный «кирпичик» — Attention — который оказался настолько мощным и гибким, что его стали применять далеко за пределами NLP. Сегодня Transformer-ы лежат в основе систем компьютерного зрения (Vision Transformer), генерации изображений (DALL-E) и даже в биологии для анализа белков. Он доказал, что иногда для того, чтобы двигаться вперед, нужно полностью отказаться от старых, проверенных методов (как рекурсия) и попробовать что-то совершенно иное.
Референсные ссылки
- Vaswani, A. et al. (2017) ‘Attention Is All You Need’. https://arxiv.org/html/1706.03762v7
- The Illustrated Transformer (2018). https://jalammar.github.io/illustrated-transformer/
- Hugging Face Transformers Documentation (2025). https://huggingface.co/docs/transformers/index
- Lilian Weng (2018) ‘Attention? Attention!’ https://lilianweng.github.io/posts/2018-06-24-attention/