 501
501 
Содержание
- Архитектура и ключевые компоненты StarRocks
- Модели развертывания StarRocks
- Принцип работы StarRocks: Векторизация и MPP
- Модели данных в StarRocks для аналитики реального времени
- Сценарии использования StarRocks
- Сравнение StarRocks с ClickHouse и DuckDB
- StarRocks vs. ClickHouse
- StarRocks vs. DuckDB
- Итог сравнения
- Взаимодействие со StarRocks: Быстрый старт и запросы
- Быстрый старт с Docker (All-in-One)
- Пример 1: Создание таблицы (Primary Key)
- Пример 2: Загрузка данных (Stream Load)
- Пример 3: Выполнение запросов
- Пример 4: Ускорение запросов (Materialized View)
- Заключение
- Референсные ссылки
StarRocks — это аналитическая СУБД с MPP-архитектурой, которая умеет напрямую работать с данными в озерах (Hive, Iceberg, Delta Lake) без импорта и поддерживает обновления записей, что редкость для OLAP-систем.Ее главное назначение — это питание интерактивных BI-дэшбордов, аналитика, доступная конечным пользователям, и другие сценарии, где скорость ответа критически важна.
Чтобы понять ее место, можно использовать простую аналогию. Если представить ClickHouse как гоночный болид, созданный для чтения данных на огромной скорости, то StarRocks — это такой же болид. Однако он обладает уникальной способностью «менять колеса на полном ходу». Это означает, что StarRocks эффективно обрабатывает не только чтение, но и обновления данных (UPSERT/DELETE) в реальном времени.
Архитектура и ключевые компоненты StarRocks
Архитектура StarRocks отличается элегантной простотой. Она не зависит от внешних компонентов, таких как Zookeeper или HDFS, что упрощает развертывание и обслуживание. Вся система состоит всего из двух типов узлов, которые легко масштабируются горизонтально.
- Фронтенды (Frontend, FE): Это «мозг» всей системы StarRocks. Узлы FE отвечают за управление метаданными, такими как базы данных, таблицы и пользователи. Они принимают SQL-запросы от клиентов, выполняют их парсинг, анализ и планирование. Кроме того, FE используют Cost-Based Optimizer (CBO) для построения наиболее эффективного плана выполнения запроса. Они также координируют выполнение запросов на узлах-бекендах.
- Бекенды (Backend, BE): Это «мускулы» кластера StarRocks. Узлы BE несут ответственность за фактическое хранение данных на локальных дисках. Они также выполняют вычисления, то есть ту часть плана запроса, которую им назначает FE. BE напрямую читают, фильтруют и агрегируют данные.
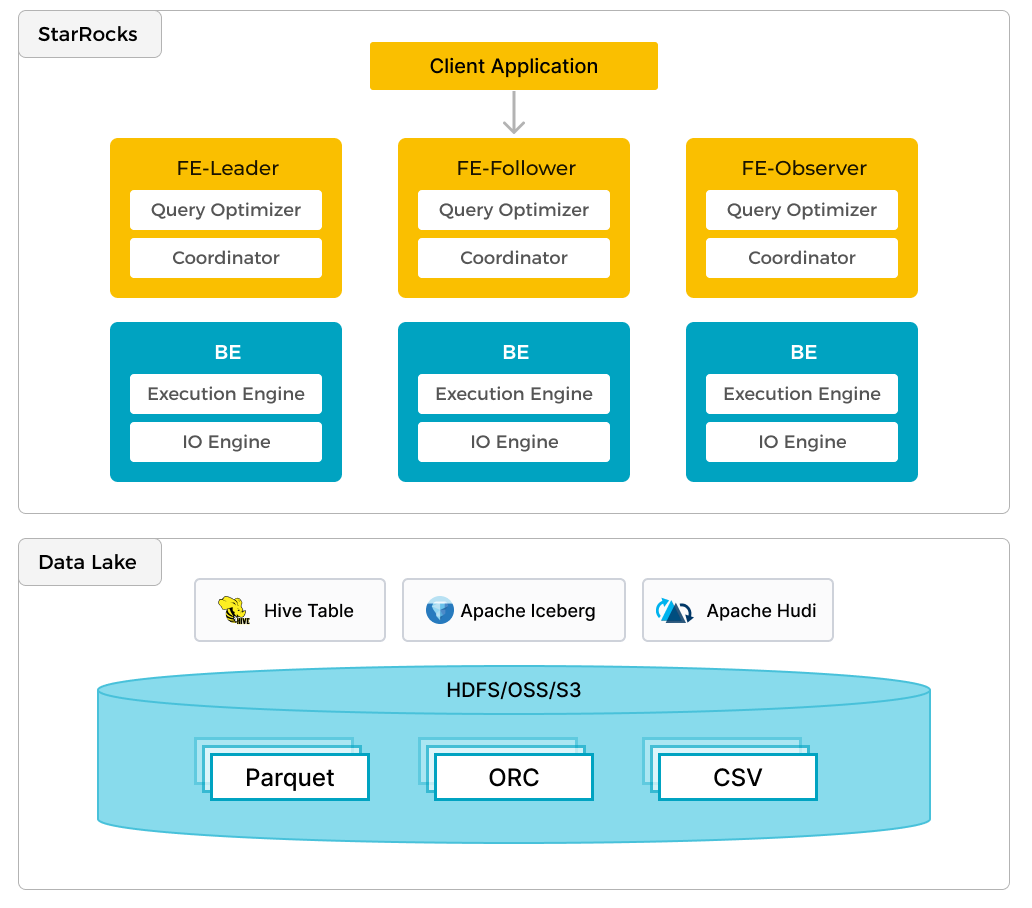
Эта архитектура позволяет StarRocks быть гибкой в развертывании. Система поддерживает две основные модели, которые фундаментально меняют подход к данным.
Модели развертывания StarRocks
StarRocks предлагает два подхода к архитектуре, позволяя пользователям выбирать между максимальной производительностью и эластичностью.
Shared-nothing (Архитектура с разделением ресурсов)
Это классическая MPP-модель, где узлы BE отвечают одновременно и за хранение, и за вычисления. Данные физически хранятся на тех же серверах, которые их обрабатывают. Такой подход минимизирует перемещение данных по сети при выполнении запроса. Он обеспечивает максимальную производительность и идеален для локальных (on-premise) развертываний, где оборудование фиксировано.
Shared-data (Архитектура с разделением вычислений и хранения)
Это современная «облачная» модель, которая становится все более популярной. В этой архитектуре StarRocks использует новый тип узлов — Compute Nodes (CN).
- Хранение выносится во внешнее объектное хранилище (например, Amazon S3, Google Cloud Storage).
- Вычисления производятся на эластичных узлах CN, которые не хранят данные постоянно.
Такое разделение позволяет независимо масштабировать хранение и вычисления. Например, можно добавить вычислительной мощности во время пиковой нагрузки и отключить ее ночью для экономии. Эта модель обеспечивает превосходную эластичность и снижение затрат в облачных средах.
Принцип работы StarRocks: Векторизация и MPP
Высокая скорость StarRocks достигается за счет комбинации двух ключевых технологий: MPP и векторизованного движка выполнения.
MPP (Massively Parallel Processing)
Принцип MPP означает, что StarRocks использует все доступные ресурсы кластера для выполнения одного запроса. Процесс выглядит так:
- Пользователь отправляет сложный SQL-запрос на узел FE.
- FE («мозг») анализирует запрос и разбивает его на множество мелких, независимых фрагментов-задач.
- Затем FE распределяет эти задачи параллельно по всем доступным узлам BE или CN («мускулам»).
- Каждый узел выполняет свою маленькую часть работы над своим фрагментом данных.
- Результаты собираются, агрегируются и возвращаются пользователю.
Таким образом, вместо одного большого процесса, над задачей трудятся десятки или сотни мелких параллельных процессов, что и обеспечивает субсекундный отклик.
Нативный векторизованный движок
Это ядро скорости StarRocks. В отличие от традиционных баз данных, которые обрабатывают данные построчно (кортеж за кортежем), векторизованный движок работает иначе.
- Он обрабатывает данные «пачками» (векторами) в рамках одной колонки.
- Все операции (фильтрация, агрегация) применяются сразу ко всему вектору данных.
- Этот подход максимально эффективно использует современные CPU, особенно SIMD-инструкции (Single Instruction, Multiple Data). Одна инструкция процессора выполняется сразу над несколькими элементами данных.
Это значительно снижает накладные расходы на выполнение цикла и позволяет достичь высочайшей производительности вычислений.
Cost-Based Optimizer (CBO)
Чтобы MPP-движок работал эффективно, ему нужен умный «мозг». CBO в StarRocks — это именно такой компонент. Он анализирует статистику данных (распределение, кардинальность) и оценивает «стоимость» различных вариантов выполнения запроса. Это особенно важно для сложных запросов с множественными JOIN-операциями. CBO выбирает оптимальный порядок соединения таблиц и метод их выполнения (например, Hash Join или Broadcast Join), чтобы минимизировать трафик по сети и нагрузку на CPU.
Модели данных в StarRocks для аналитики реального времени
Одной из самых мощных особенностей StarRocks является гибкость в моделировании данных. Разные задачи требуют разного подхода к хранению, и StarRocks предлагает несколько моделей таблиц. Эти модели определяют, как данные физически хранятся и как система реагирует на дубликаты ключей.
Вот основные модели данных в StarRocks:
- Primary Key Model (Модель с первичным ключом): Это «секретное оружие» StarRocks для аналитики в реальном времени. Эта модель позволяет задать первичный ключ для таблицы. Когда поступают новые данные с тем же первичным ключом, StarRocks автоматически обновляет (UPSERT) существующую запись. Если поступает специальная команда удаления, строка удаляется (DELETE). Это критически важно для сценариев CDC (Change Data Capture), когда нужно синхронизировать данные из транзакционных систем (PostgreSQL, MySQL) в реальном времени. Вместо сложных пакетных ETL-процессов, данные просто «дотекают» и «обновляются» на лету.
- Aggregate Model (Модель с агрегацией): Эта модель идеально подходит для сценариев, где важны пред-агрегированные данные. При загрузке данных строки с одинаковыми ключами (заданными пользователем) автоматически агрегируются. Например, можно настроить таблицу так, чтобы она автоматически суммировала клики или доход по пользователю. Это позволяет хранить уже готовые витрины, что многократно ускоряет выполнение типовых запросов.
- Duplicate Model (Модель с дубликатами): Это самая простая модель. Она просто хранит все поступающие строки как есть, не проверяя их на уникальность. Эта модель идеально подходит для хранения «сырых» данных, таких как логи событий, телеметрия IoT или исторические данные, где важна каждая отдельная запись.
Выбор правильной модели таблицы при проектировании схемы является ключевым фактором для достижения максимальной производительности в StarRocks.
Сценарии использования StarRocks
Благодаря своей гибкой архитектуре и высокой производительности, StarRocks отлично подходит для широкого спектра аналитических задач. Он используется как для внутренних нужд компании, так и для аналитики, доступной внешним клиентам.
Ключевые сценарии применения StarRocks включают:
- BI-дэшборды и отчетность в реальном времени:
Это классический сценарий. StarRocks позволяет создавать сложные интерактивные дэшборды (например, в Apache Superset, Metabase или Tableau), которые обновляются в реальном времени и не «тормозят» даже на миллиардах строк. - Аналитика, «смотрящая» на пользователя (Customer-facing analytics):
Когда аналитика встраивается непосредственно в продукт (например, личный кабинет клиента с отчетами). В этом сценарии важна не только скорость, но и высокая одновременная нагрузка (high concurrency). StarRocks спроектирован, чтобы выдерживать тысячи одновременных пользователей, выполняющих аналитические запросы. - Анализ данных IoT, логов и событий:
Способность быстро загружать (инжестировать) триллионы событий из Kafka или Flink и тут же их анализировать делает StarRocks отличным выбором для мониторинга и анализа временных рядов. - Единая платформа для Data Lakehouse (Озеро данных):
StarRocks может выступать в роли единого ядра запросов для всего озера данных. Он умеет выполнять федеративные запросы, то есть читать данные напрямую из открытых форматов (Apache Iceberg, Hive, Delta Lake) в S3 или HDFS, не копируя их. Это позволяет объединять «холодные» данные из озера с «горячими» данными внутри StarRocks в одном SQL-запросе.
Таким образом, StarRocks позиционирует себя как универсальная платформа, закрывающая большинство потребностей современной быстрой аналитики.
Сравнение StarRocks с ClickHouse и DuckDB
Выбор аналитической СУБД — сложная задача. StarRocks, ClickHouse и DuckDB часто упоминаются вместе, так как все они являются звездами современной быстрой аналитики. Однако они созданы для принципиально разных задач.
StarRocks vs. ClickHouse
Это наиболее частое сравнение, так как обе системы являются распределенными, колоночными MPP-базами данных.
Сходства: Обе СУБД невероятно быстры на аналитических (OLAP) запросах. Они используют векторизованное выполнение и колоночное хранение.
Различия:
- Обновление данных: Это главное отличие. StarRocks изначально спроектирован для обновлений в реальном времени с помощью Primary Key Model. Это делает его идеальным для CDC-сценариев. В ClickHouse для этого используется движок ReplacingMergeTree, который работает по схожему принципу, но исторически считается более сложным в настройке и менее производительным именно на операциях обновления.
- JOIN-операции: StarRocks был создан с фокусом на сложные запросы и использует продвинутый Cost-Based Optimizer (CBO) для JOIN-операций. ClickHouse также развивает свой оптимизатор, но StarRocks часто показывает более высокую производительность на «дорогих» запросах с соединением нескольких больших таблиц. Практические тесты это подтверждают: на запросах с двумя и более LEFT JOIN StarRocks может показывать кратное преимущество, порой опережая ClickHouse в 5 и более раз. Это во многом связано с различиями в реализации JOIN-стратегий.
- Архитектура: StarRocks предлагает гибкую «облачную» архитектуру с разделением вычислений и хранения (shared-data). Это делает его более удобным для эластичных развертываний в облаке.
StarRocks vs. DuckDB
Это сравнение часто возникает из-за схожей высокой производительности, но оно не совсем корректно.
- Ключевое различие — Архитектура:
StarRocks — это распределенная серверная СУБД. Это полноценный кластер, который работает как сервис, хранит данные и обслуживает множество клиентских подключений.
DuckDB — это встраиваемая (in-process) библиотека. Она работает внутри другого приложения (например, Python-скрипта или Pandas). У нее нет серверного процесса, и она не предназначена для обслуживания множества пользователей. - Аналогия:
StarRocks — это промышленная электростанция, построенная для обеспечения энергией целого города (компании).
DuckDB — это мощный портативный генератор, который вы используете для питания одного дома (одного ноутбука или приложения). - Производительность:
На небольших данных (до 50-100 миллионов строк), которые помещаются в память одного компьютера, DuckDB может быть феноменально быстр, иногда опережая в простых операциях (вроде COUNT(*)) даже распределенные системы. Однако на сложных JOIN-запросах, как показывают тесты, StarRocks и DuckDB демонстрируют очень близкую и высокую производительность, часто вместе опережая ClickHouse.
Итог сравнения
| Параметр | StarRocks | ClickHouse | DuckDB |
| Тип | Распределенная СУБД (Сервер) | Распределенная СУБД (Сервер) | Встраиваемая библиотека (In-Process) |
| Масштаб | Горизонтальный (Много узлов) | Горизонтальный (Много узлов) | Вертикальный (Один узел) |
| Обновления (UPSERT) | Отлично (Primary Key Model) | Ограниченно (ReplacingMergeTree) | Да (но в рамках одной машины) |
| JOIN’ы | Очень высокая производительность (CBO) | Высокая (но уступает StarRocks) | Очень высокая (в рамках одной машины) |
| Сценарий | BI, Real-time CDC, Customer-facing | BI, Логи, Телеметрия, Сырые данные | Локальный анализ, Python/Pandas, SQL на файлах |
Выбор прост:
- Нужен мощный аналитический сервер для всей компании с поддержкой real-time обновлений? StarRocks.
- Нужен самый быстрый «склад» для гигантских объемов сырых логов (в основном на добавление)? ClickHouse.
- Нужен «SQL на стероидах» для локального анализа данных на ноутбуке или в Python-скрипте? DuckDB.
Взаимодействие со StarRocks: Быстрый старт и запросы
Одно из преимуществ StarRocks — совместимость с протоколом MySQL. Это означает, что для подключения можно использовать любой стандартный MySQL-клиент, включая CLI или графические интерфейсы, такие как DBeaver.
Быстрый старт с Docker (All-in-One)
Для быстрого тестирования StarRocks проще всего использовать официальный Docker-образ «всё-в-одном». Он запускает и Frontend (FE), и Backend (BE) в одном контейнере.
docker run -p 9030:9030 -p 8030:8030 -p 8040:8040 -itd \ --name starrocks-test \ starrocks/allin1-ubuntu
После запуска контейнера (подождите 10-20 секунд) вы можете подключиться к нему, используя следующие параметры:
- Хост: localhost
- Порт: 9030
- Пользователь: root
- Пароль: (пустой)
Вы можете использовать эти данные в DBeaver (выбрав драйвер MySQL) или подключиться через CLI прямо из Docker:
docker exec -it starrocks-test \ mysql -h 127.0.0.1 -P 9030 -u root --prompt="StarRocks > "
Пример 1: Создание таблицы (Primary Key)
Сначала создадим базу данных и таблицу для данных электронной коммерции, используя Primary Key Model. Ключ order_id гарантирует, что при поступлении новых данных о заказе старые будут атомарно обновлены.
CREATE DATABASE IF NOT EXISTS my_database; USE my_database; CREATE TABLE orders ( order_id BIGINT NOT NULL, order_date DATE NOT NULL, customer_id INT NOT NULL, order_amount DECIMAL(10, 2), order_status VARCHAR(20) ) PRIMARY KEY (order_id) DISTRIBUTED BY HASH(order_id) PROPERTIES ( "replication_num" = "1" );
Практическое применение Big Data аналитики для решения бизнес-задач
Код курса
PRUS
Ближайшая дата курса
20 апреля, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Пример 2: Загрузка данных (Stream Load)
StarRocks поддерживает множество способов загрузки, но Stream Load является одним из самых популярных для real-time сценариев. Он позволяет отправлять данные (CSV или JSON) напрямую в StarRocks через простой HTTP-запрос.
Создадим локально файл new_orders.csv с таким содержимым:
1001,2025-11-13,501,150.75,Pending 1002,2025-11-13,502,89.99,Shipped 1003,2025-11-14,501,45.50,Pending 1001,2025-11-14,501,150.75,Shipped
Теперь загрузим его с помощью cURL:
curl --location-trusted -u 'root:' \ -H "Content-Type: text/csv" \ -H "columns: order_id,order_date,customer_id,order_amount,order_status" \ -H "column_separator: ," \ -H "Expect: 100-continue" \ -T new_orders.csv \ http://localhost:8030/api/my_database/orders/_stream_load

Пример 3: Выполнение запросов
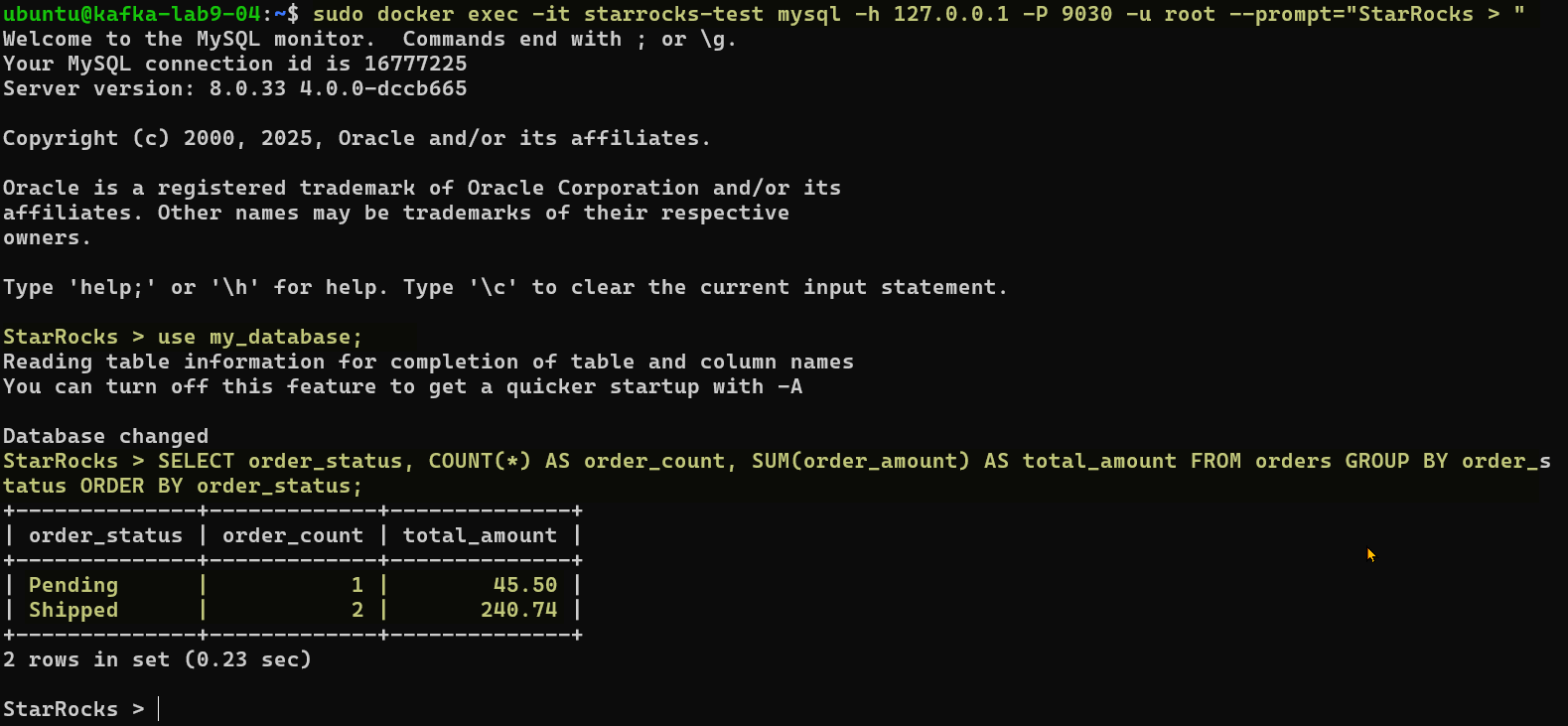
После загрузки данных мы можем немедленно выполнить запрос. Обратите внимание, что order_id 1001 был обновлен. В базе данных будет 3 строки, а не 4.
Давайте посчитаем общую сумму заказов и их количество по каждому статусу:
SELECT order_status, COUNT(*) AS order_count, SUM(order_amount) AS total_amount FROM orders GROUP BY order_status ORDER BY order_status;
Ожидаемый результат:
Пример 4: Ускорение запросов (Materialized View)
Материализованные представления (Materialized Views, MV) в StarRocks — мощный инструмент ускорения. Они автоматически пересчитываются и хранят уже готовый результат агрегации. Этот MV будет в реальном времени считать дневную выручку. Но MV нельзя сделать на таблицу с Primary Key. Поэтому сначала делаем агрегат по дням
CREATE TABLE orders_daily (
order_date DATE,
total_revenue DECIMAL(18,2) SUM
)
AGGREGATE KEY(order_date)
DISTRIBUTED BY HASH(order_date)
PROPERTIES (
"replication_num" = "1"
);
Создаем Материализованное представление на агрегат orders_daily для подсчета месячной выручки
CREATE MATERIALIZED VIEW orders_monthly_mv
AS
SELECT
date_trunc('month', order_date) AS order_month,
SUM(total_revenue) AS monthly_revenue
FROM orders_daily
GROUP BY date_trunc('month', order_date);
--
SELECT
date_trunc('month', order_date) AS order_month,
SUM(total_revenue) AS monthly_revenue
FROM orders_daily
GROUP BY date_trunc('month', order_date);

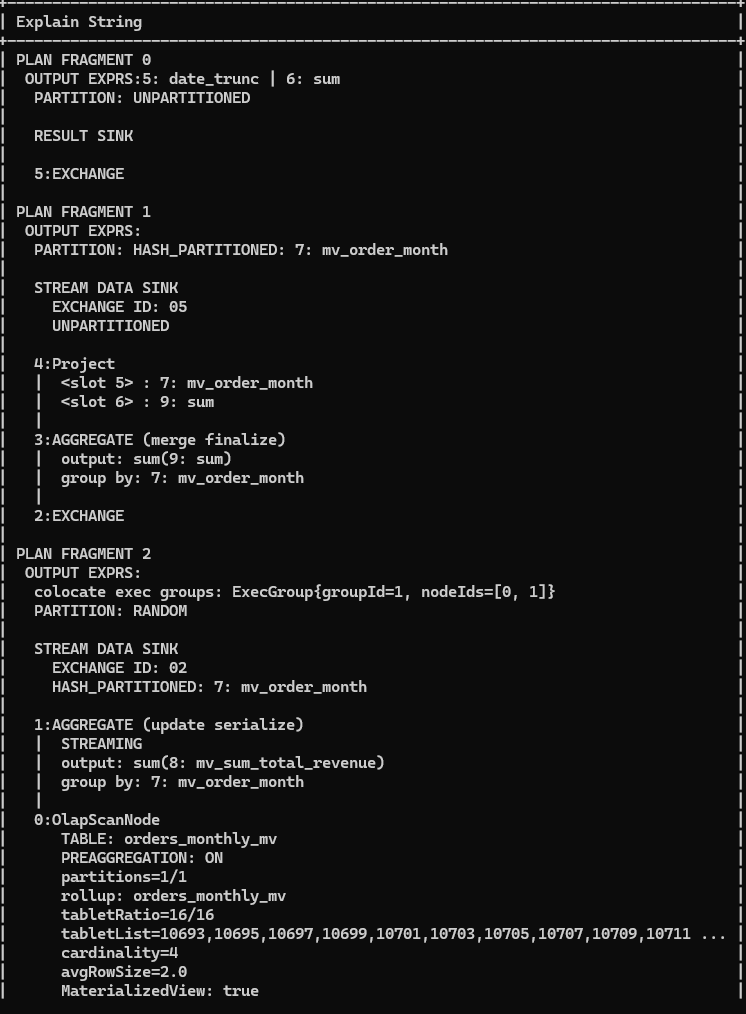
Теперь оптимизатор сможет подставить orders_monthly_mv вместо сырых данных orders_daily — запрос поедет по предрасчитанному MV
Построение DWH на ClickHouse
Код курса
CLICH
Ближайшая дата курса
16 февраля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Заключение
StarRocks уверенно занимает свою нишу в мире высокопроизводительных аналитических баз данных. Это не просто «еще один ClickHouse». Это мощная, зрелая система, которая предлагает уникальный баланс между скоростью чтения (сравнимой с ClickHouse) и гибкостью обновлений данных в реальном времени (чего не хватает многим OLAP-системам).
Его способность эффективно выполнять сложные JOIN-операции, простая архитектура без внешних зависимостей и гибкость развертывания (shared-nothing и shared-data) делают StarRocks идеальным кандидатом на роль единой аналитической платформы. Он способен заменить сложные ETL/ELT-пайплайны, позволяя анализировать данные сразу в момент их поступления.
Референсные ссылки
- Официальная документация SRocks (https://docs.starrocks.io/docs/introduction/StarRocks_intro/)
- Архитектура StarRs (https://docs.starrocks.io/docs/introduction/Architecture/)
- Модель данных Primary Key (https://docs.starrocks.io/docs/table_design/table_types/primary_key_table/)
- Тестирование скорости запросов для баз данных DuckDB, ClickHouse и StarRocks (https://medium.com/@marvin_data/testing-query-speed-for-duckdb-vs-clickhouse-vs-starrocks-databases-fecc6614d1ef)