 1050
1050 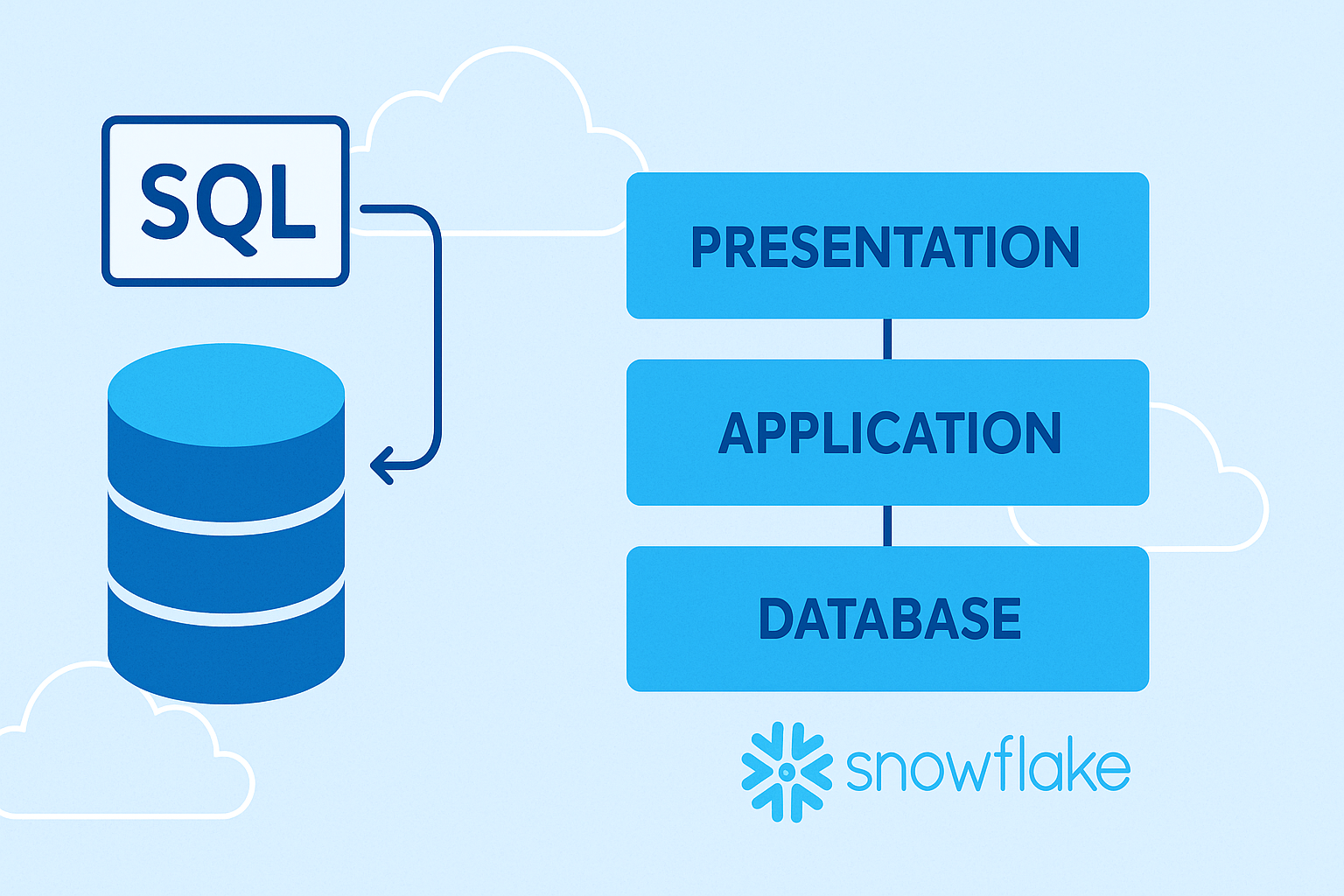
Содержание
Snowflake — это комплексная облачная платформа данных, предоставляемая по модели «программное обеспечение как услуга» (SaaS), которая в единой среде объединяет функциональность хранилища данных (Data Warehouse), озера данных (Data Lake) и аналитических систем, полностью абстрагируя пользователей от управления базовой инфраструктурой и предоставляя для работы с данными интерфейс на основе стандартного SQL.
Ключевое отличие Snowflake от традиционных хранилищ и конкурентов, таких как Amazon Redshift, Google BigQuery или Microsoft Azure Synapse, заключается в его уникальной многокластерной архитектуре с полным разделением ресурсов хранения (storage) и вычислений (compute). Такая архитектура обеспечивает практически неограниченную и независимую масштабируемость, а также высокий уровень параллелизма при обработке запросов, что делает платформу чрезвычайно гибкой и производительной для решения самых разнообразных задач.
Эта платформа изначально была создана для работы в облачных средах, таких как Amazon Web Services (AWS), Google Cloud Platform (GCP) и Microsoft Azure. Благодаря этому пользователи могут разворачивать Snowflake в том же регионе, где находятся их остальные данные и приложения, минимизируя задержки.
Snowflake полностью абстрагирует пользователей от сложностей управления инфраструктурой, позволяя сконцентрироваться исключительно на работе с данными. Платформа поддерживает стандартный SQL, что упрощает миграцию для команд, уже имеющих опыт работы с реляционными базами данных.
Ключевая архитектура Snowflake: Три столпа успеха
В основе эффективности и гибкости Snowflake лежит ее уникальная трехуровневая архитектура. Эти уровни независимы друг от друга, но тесно интегрированы для обеспечения бесперебойной работы.
- Уровень хранения данных (Database Storage)
Все данные, загруженные в Snowflake, автоматически преобразуются в собственный оптимизированный, сжатый и колоночный формат. Эти данные хранятся в облачном хранилище (например, Amazon S3 или Azure Blob Storage) того региона, где развернут аккаунт Snowflake. Этот уровень полностью отвечает за сохранность, отказоустойчивость и управление данными, включая организацию таблиц, шифрование и метаданные. Важно, что этот уровень полностью отделен от вычислительных ресурсов. - Уровень вычислений (Query Processing)
Обработка запросов в Snowflake выполняется с помощью «виртуальных хранилищ» (Virtual Warehouses). Virtual Warehouse — это, по сути, кластер из одного или нескольких вычислительных узлов (compute nodes), которые запрашивают данные с уровня хранения для выполнения SQL-операций. Каждый хранилище работает независимо, не разделяя ресурсы с другими. Это позволяет разным командам (например, аналитикам, дата-сайентистам и ETL-процессам) работать с одними и теми же данными одновременно, не влияя на производительность друг друга. Хранилища можно масштабировать «на лету» — увеличивать или уменьшать их мощность, а также автоматически приостанавливать при отсутствии нагрузки для экономии средств. - Уровень облачных сервисов (Cloud Services)
Это «мозг» всей платформы Snowflake. Этот уровень координирует все действия внутри системы. Он отвечает за управление транзакциями, аутентификацию пользователей, управление метаданными, оптимизацию запросов и контроль доступа. Именно этот слой обеспечивает согласованность данных и выполняет всю фоновую работу, делая взаимодействие с платформой простым и надежным для конечного пользователя.

Уникальные возможности Snowflake
Архитектура платформы открывает доступ к нескольким мощным функциям, которые выделяют ее на рынке.
- Time Travel: Эта функция позволяет «откатить» состояние данных на определенный момент в прошлом. Snowflake хранит историю изменений данных в течение настраиваемого периода (до 90 дней). Это невероятно полезно для восстановления случайно удаленных или измененных данных, а также для анализа исторических срезов без необходимости создавать сложные резервные копии.
- Zero-Copy Cloning: Snowflake позволяет создавать полные копии баз данных, схем или отдельных таблиц практически мгновенно и без дублирования физического хранения данных. Клон является «записью по ссылке» на исходные данные. Изменения в клоне записываются как дельта, что делает этот процесс крайне эффективным для создания сред для разработки, тестирования или экспериментов.
- Secure Data Sharing: Пользователи могут безопасно делиться данными с другими аккаунтами Snowflake без необходимости копировать или перемещать сами данные. Провайдер данных просто предоставляет защищенный доступ к своему хранилищу, а потребитель использует собственные вычислительные ресурсы для их анализа. Это упрощает обмен данными между компаниями и партнерами.
- Snowpipe: Сервис для непрерывной и автоматизированной загрузки данных. Snowpipe отслеживает файлы в указанном внешнем хранилище (например, S3) и автоматически загружает новые данные в таблицы Snowflake по мере их появления, что идеально подходит для потоковых сценариев. Для более сложных преобразований данных рекомендуем изучить подходы ETL и ELT, о которых можно узнать в нашем блоге.
Примеры реализации: Работа со Snowflake SQL
Snowflake использует стандартный ANSI SQL, что делает его интуитивно понятным для большинства аналитиков и инженеров. Рассмотрим базовый сценарий работы.
Шаг 1: Создание и настройка Virtual Warehouse
Сначала создадим вычислительный кластер. Укажем его размер (X-Small — самый маленький), политику автоматической приостановки через 5 минут бездействия и автоматического возобновления при поступлении запроса.
-- Создание виртуального склада для аналитических задач CREATE OR REPLACE WAREHOUSE ANALYTICS_WH WAREHOUSE_SIZE = 'XSMALL' AUTO_SUSPEND = 300 -- в секундах AUTO_RESUME = TRUE COMMENT = 'Склад для команды бизнес-аналитики';
Шаг 2: Создание базы данных и таблицы
Теперь создадим окружение для наших данных — базу данных и таблицу для хранения информации о продажах.
-- Создание базы данных для отдела продаж CREATE OR REPLACE DATABASE SALES_DB; -- Переключение на созданную базу данных для дальнейшей работы USE DATABASE SALES_DB; -- Создание таблицы для хранения транзакций CREATE OR REPLACE TABLE TRANSACTIONS ( transaction_id INT, product_name VARCHAR(100), sale_amount DECIMAL(10, 2), transaction_date TIMESTAMP_NTZ );
Шаг 3: Вставка данных и выполнение запроса
Загрузим несколько строк в нашу таблицу и выполним простой аналитический запрос для подсчета выручки по продуктам.
-- Вставка данных о продажах INSERT INTO TRANSACTIONS (transaction_id, product_name, sale_amount, transaction_date) VALUES (1, 'Laptop', 1200.00, '2025-07-24 10:00:00'), (2, 'Mouse', 25.50, '2025-07-24 10:05:00'), (3, 'Laptop', 1250.00, '2025-07-24 11:30:00'), (4, 'Keyboard', 75.00, '2025-07-24 12:00:00'); -- Активация нашего склада (если он был приостановлен) USE WAREHOUSE ANALYTICS_WH; -- Запрос на получение общей выручки по каждому продукту SELECT product_name, SUM(sale_amount) as total_revenue FROM TRANSACTIONS GROUP BY product_name ORDER BY total_revenue DESC;
Этот простой пример демонстрирует, как в Snowflake разделены задачи управления инфраструктурой (создание хранилища) и работа с данными (SQL-запросы), что является основой его гибкости. Для более глубокого изучения возможностей баз данных, вы можете ознакомиться с нашим курсом по ClickHouse, еще одной мощной аналитической СУБД.
Заключение
Snowflake представляет собой мощную и зрелую облачную платформу данных, которая успешно решает многие проблемы традиционных хранилищ. Благодаря своей уникальной архитектуре с разделением хранения и вычислений, она предлагает беспрецедентную гибкость, масштабируемость и производительность. Функции, такие как Time Travel, Zero-Copy Cloning и Secure Data Sharing, предоставляют инженерам и аналитикам инструменты, которые значительно упрощают разработку, тестирование и обмен данными. Именно поэтому Snowflake стала одним из лидеров на рынке Big Data и ключевым компонентом современного стека данных для тысяч компаний по всему миру.
Список использованных референсов и материалов
-
- Официальная документация Snowflake: Key Concepts & Architecture. https://docs.snowflake.com/en/user-guide/intro-key-concepts