 560
560 
Содержание
- Ключевые компоненты архитектуры SIMD
- Широкие регистры
- Специализированные инструкции
- Принцип работы SIMD: Как это работает на самом деле?
- Где используется SIMD: от баз данных до Python
- Как программисты "взаимодействуют" с SIMD?
- Эволюция SIMD: от MMX до AVX и NEON
- SIMD vs. MIMD vs. SIMT: В чем разница?
- Заключение
- Референсные ссылки
SIMD (Single Instruction, Multiple Data или «Одиночный поток команд, множественный поток данных») — это класс процессорных инструкций, позволяющий выполнить одну операцию одновременно над несколькими элементами данных. Это фундаментальная технология, которая обеспечивает параллелизм вычислений на уровне одного ядра процессора. Вместо того чтобы обрабатывать данные по одному, SIMD позволяет процессору захватывать целый «пакет» данных и применять к нему одну команду за один такт.
Чтобы по-настоящему понять эту концепцию, проще всего использовать аналогию.
- Обычный процессор (SISD): Представьте себе повара на кухне, которому нужно нарезать 16 морковок. Он берет одну морковку, кладет ее на доску, делает 10 режущих движений. Затем он берет вторую морковку и повторяет все 10 движений. Это последовательная обработка.
- Процессор с SIMD: Теперь представьте, что повар берет специальный широкий нож с 16 лезвиями. Он выстраивает все 16 морковок в один ряд и одним-единственным нажатием (одной инструкцией) разрезает все 16 морковок одновременно.
В мире вычислений этот подход невероятно важен. Данные редко приходят поодиночке. Они почти всегда организованы в массивы: пиксели в изображении, сэмплы в аудиофайле, числа в колонке базы данных или векторы в 3D-модели. SIMD позволяет обрабатывать эти массивы не в цикле «по одному», а целыми блоками, что приводит к колоссальному приросту производительности.
Ключевые компоненты архитектуры SIMD
Как эта «магия» реализована в «железе»? Технология SIMD опирается на два фундаментальных аппаратных компонента, встроенных в современные CPU.
Широкие регистры
Регистр — это сверхбыстрая ячейка памяти прямо на кристалле процессора. В обычном 64-битном процессоре регистр хранит одно 64-битное число. Однако для SIMD существуют специальные, очень «широкие» регистры.
- 128-битные регистры (SSE): Могут хранить 4 числа с плавающей запятой (по 32 бита каждое) или 2 числа с двойной точностью (по 64 бита).
- 256-битные регистры (AVX): Могут хранить 8 чисел с плавающей запятой (32-бит).
- 512-битные регистры (AVX-512): Могут хранить 16 чисел с плавающей запятой (32-бит).
Возвращаясь к аналогии, это «рабочий стол» повара. Обычный регистр — это крошечная доска, куда помещается одна морковка. Широкий SIMD-регистр — это огромный промышленный стол, на котором можно сразу разложить 16 морковок для одновременной работы. Процесс упаковки нескольких чисел в один регистр называется «data packing».
Специализированные инструкции
Наличие широких регистров бесполезно без команд, которые умеют с ними работать. Это и есть SIMD-инструкции — тот самый «широкий нож» повара.
Это не обычные команды ADD (сложить) или MUL (умножить), которые работают с одним числом. Это их «векторизованные» аналоги, которые говорят процессору:
«Возьми два 256-битных регистра. Считай, что в каждом из них лежит по 8 чисел. Теперь сложи попарно эти 8 чисел (первое с первым, второе со вторым…) и положи 8 результатов в третий 256-битный регистр».
У этих инструкций обычно есть специальные названия, например ADDPS (Add Packed Single-precision) или vaddps (Vector Add Packed Single-precision). Для выполнения этих команд в процессоре существуют выделенные аппаратные блоки (ALU — арифметико-логические устройства), спроектированные специально для параллельной математики.
Принцип работы SIMD: Как это работает на самом деле?
Давайте разберем на самом простом примере: сложение двух массивов C[i] = A[i] + B[i]. Допустим, нам нужно сложить 4 пары чисел.
Подход №1: Без SIMD (Последовательно)
Обычный процессор будет выполнять цикл. На каждую пару чисел ему нужно:
- Загрузить A[0] из памяти в регистр R1.
- Загрузить B[0] из памяти в регистр R2.
- Выполнить ADD R1, R2. Результат в R1.
- Выгрузить результат из R1 в C[0].
…и так 4 раза. Итого: минимум 12-16 операций.
Подход №2: С SIMD (Параллельно)
Процессор с SIMD (например, 128-битным SSE) делает это принципиально иначе:
- Шаг 1. Загрузка (Load): Процессор выполняет одну SIMD-инструкцию (например, _mm_load_ps). Эта команда «пакует» сразу 4 числа (A[0], A[1], A[2], A[3]) из оперативной памяти в один 128-битный регистр XMM0.
- Шаг 2. Загрузка (Load): Точно так же он одной инструкцией загружает 4 числа (B[0], B[1], B[2], B[3]) в регистр XMM1.
- Шаг 3. Выполнение (Execute): Процессор выполняет одну SIMD-инструкцию _mm_add_ps(XMM0, XMM1). Внутри ядра процессора 4 пары чисел складываются одновременно (параллельно) за один такт. Все 4 результата помещаются в третий регистр XMM2.
- Шаг 4. Выгрузка (Store): Процессор выполняет одну SIMD-инструкцию _mm_store_ps, которая выгружает все 4 результата из XMM2 в массив C в памяти.
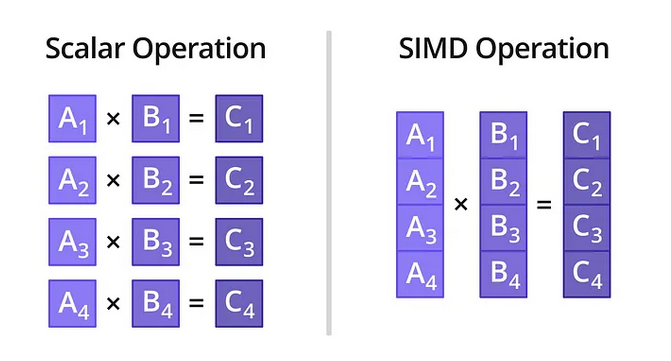
Итог: Мы выполнили ту же работу (4 сложения) всего за 4 операции вместо 12+. Прирост производительности в этом идеальном примере — 3-4 раза. На современных 512-битных регистрах (AVX-512) мы могли бы сложить 16 пар чисел за то же время, получив теоретический прирост до 16 раз.
Конечно, в реальности прирост не всегда такой линейный из-за накладных расходов на загрузку и выгрузку данных. Однако на задачах с большим объемом вычислений SIMD дает колоссальное, а не процентное, ускорение.
Где используется SIMD: от баз данных до Python
SIMD — это не какая-то эзотерическая технология для суперкомпьютеров. Она является «секретным ингредиентом», обеспечивающим производительность в программном обеспечении, которым вы пользуетесь каждый день.
Вот краткий список технологий и продуктов, чья работа была бы немыслима без SIMD:
Аналитические СУБД (OLAP): Это, пожалуй, самый яркий пример в мире Big Data. Современные аналитические базы используют векторизованный движок выполнения (vectorized execution engine), который идеально ложится на SIMD.
Построение DWH на ClickHouse
Код курса
CLICH
Ближайшая дата курса
16 февраля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
- ClickHouse: Один из пионеров, который ставит SIMD во главу угла. Когда вы выполняете запрос SUM(column) или AVG(column) по миллиарду строк, ClickHouse не использует цикл. Он вызывает SIMD-инструкции, которые складывают или фильтруют данные огромными «пачками» по 8, 16 или 32 значения за раз.
- StarRocks / Apache Doris: Эти системы также построены на векторизованных движках. Они обрабатывают данные не построчно, а «векторами» (блоками по 1024+ значений), применяя SIMD-операции ко всему вектору.
- DuckDB: Вся архитектура этой встраиваемой (in-process) СУБД построена на векторизации для максимального использования SIMD на локальной машине.
Библиотеки обработки данных и Машинного обучения (ML): Если вы работаете с данными в Python, вы используете SIMD каждую минуту, даже не зная об этом.
ML Практикум: от теории к промышленному использованию
Код курса
PYML
Ближайшая дата курса
30 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
- NumPy / Pandas: Когда вы складываете два больших NumPy-массива (arr_a + arr_b), Python не выполняет цикл for. «Под капотом» NumPy вызывает оптимизированный, скомпилированный C-код, который использует SIMD-инструкции вашего процессора.
- TensorFlow / PyTorch: Перемножение матриц — сердце глубокого обучения. Когда эти фреймворки работают на CPU (а не GPU), они полагаются на высокооптимизированные библиотеки (такие как Intel MKL или oneDNN), которые по максимуму используют SIMD (особенно AVX2 и AVX-512).
- Apache Arrow: Это не просто формат данных, это формат в памяти, который спроектирован так, чтобы быть «SIMD-friendly». Данные в нем уже лежат в колонках и выровнены в памяти так, чтобы их можно было мгновенно загрузить в SIMD-регистры без дополнительных преобразований.
Графика, игры и мультимедиа: Исторически это была первая область применения SIMD.
- Игровые движки (Unreal Engine, Unity): 3D-графика — это, по сути, миллионы операций с векторами (координатами x, y, z). SIMD идеально подходит для параллельного расчета физики, освещения и трансформаций для тысяч объектов на экране.
- Видеокодеки (H.264, H.265, AV1): Сжатие и воспроизведение видео — это массовая обработка «пакетов» пикселей. Применение фильтра яркости или размытия к кадру 4K — это классическая SIMD-задача.
- Аудио- и фоторедакторы (Adobe Photoshop, Audition): Применение сложного фильтра к фотографии или эффекта «реверберации» к аудиодорожке происходит с использованием SIMD.
Таким образом, от быстрой аналитики в ClickHouse до простого сложения массивов в NumPy — за всей этой скоростью стоит SIMD.
Как программисты «взаимодействуют» с SIMD?
Разработчики редко пишут на чистом ассемблере, чтобы использовать SIMD. Существует три основных способа «заставить» эту технологию работать.
Авто-векторизация (The «Easy Way»)
Современные компиляторы (такие как GCC, Clang, MSVC) стали невероятно умными. Программист пишет обычный, простой цикл for на C++ или Rust. Затем он включает флаг оптимизации (например, -O3). Компилятор анализирует этот цикл, понимает, что он безопасен для параллельной обработки, и автоматически заменяет его набором SIMD-инструкций.
- Плюс: Не требует усилий.
- Минус: Очень «хрупкий» метод. Любое усложнение логики в цикле (например, if-else или зависимость итераций) может «сломать» авто-векторизацию.
Интpинсики (Intrinsics) (The «Hard Way»)
Это для экспертов, которым нужен полный контроль. Интpинсики — это специальные функции, встроенные в C/C++ (например, _mm256_add_ps(a, b)). Они выглядят как вызов функции, но на самом деле являются прямым указанием компилятору: «Вставь именно эту SIMD-инструкцию в ассемблерный код».
- Плюс: Максимальная производительность и полный контроль.
- Минус: Код становится сложным, нечитаемым и жестко привязанным к архитектуре (код с AVX2 не запустится на старом CPU без AVX2).
Готовые библиотеки (The «Smart Way»)
Это самый распространенный подход. Вместо того чтобы изобретать велосипед, разработчики используют библиотеки, где вся SIMD-оптимизация уже сделана за них. Когда вы используете NumPy, TensorFlow или ClickHouse, вы как раз пользуетесь этим методом. Эксперты уже написали сложный код на интринсиках или ассемблере, а вы просто вызываете высокоуровневую функцию (например, np.dot(a, b)).
Эволюция SIMD: от MMX до AVX и NEON
SIMD — это не одна технология, а целое семейство стандартов, которые постоянно развиваются, главным образом в сторону увеличения «ширины» регистров.
Вот краткая хронология для понимания «зоопарка» аббревиатур:
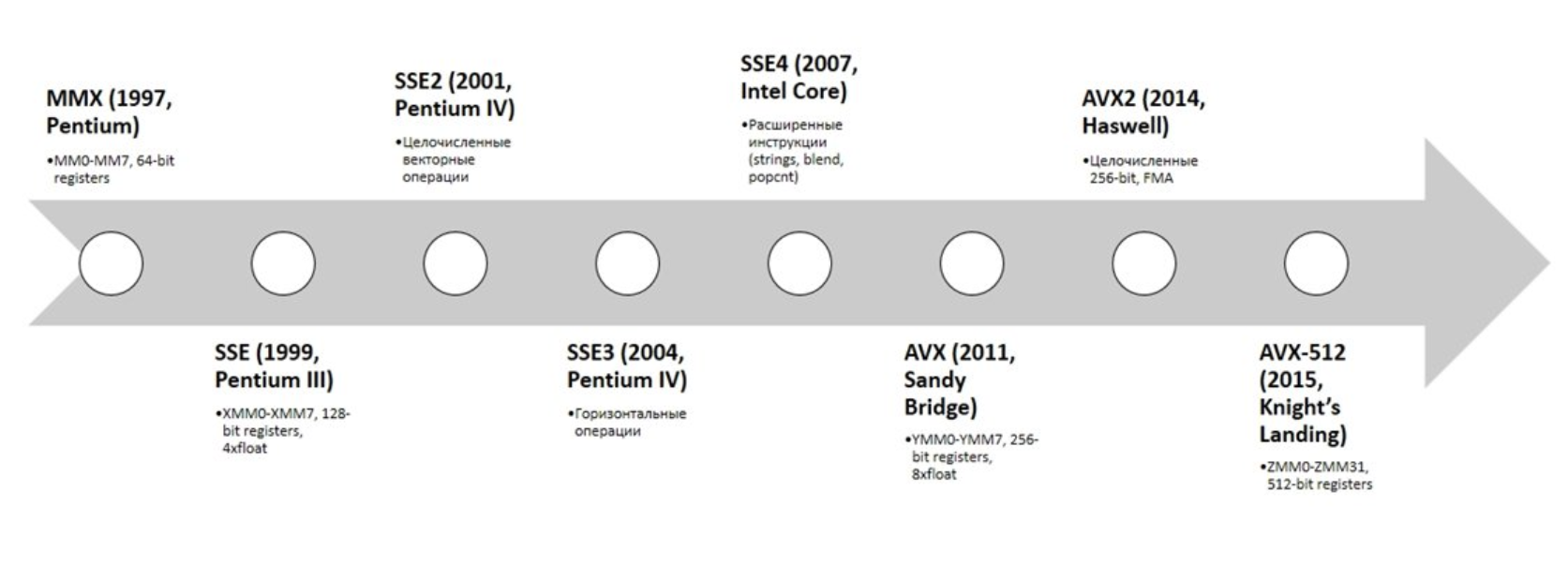
- Intel/AMD (Архитектура x86, наши ПК и серверы)
- MMX (1997) «Дедушка» SIMD. Использовал 64-битные регистры, в основном для целочисленной графики.
- SSE (1999) Настоящая революция. Ввел 128-битные регистры (XMM), добавил операции с плавающей запятой. Именно SSE сделал возможной быструю 3D-графику и обработку видео на ПК.
- AVX / AVX2 (2011) Современный стандарт. Расширил регистры до 256 бит (YMM) и добавил множество удобных инструкций. Это «рабочая лошадка» для большинства современных аналитических СУБД и ML-библиотек.
- AVX-512 (2017) «Монстр». Регистры шириной 512 бит (ZMM), способные обрабатывать 16 чисел с плавающей запятой за раз. Используется в высокопроизводительных серверах (HPC) и активно применяется в ClickHouse для достижения рекордной производительности.
- ARM (Наши телефоны, планшеты, Apple Silicon)
- NEON Это собственный стандарт SIMD для ARM-архитектуры. Он использует 128-битные регистры и является причиной, по которой ваш смартфон или Mac M-серии может так плавно воспроизводить 4K-видео, применять фильтры в Instagram и запускать сложные 3D-игры.
Тенденция очевидна: регистры становятся все шире, позволяя «перемалывать» все больше данных за один такт процессора.
SIMD vs. MIMD vs. SIMT: В чем разница?
Очень важно не путать SIMD с другими формами параллелизма. Это три совершенно разных уровня.
SIMD (Single Instruction, Multiple Data)
- Что это: 1 инструкция работает с 1 «пакетом» данных.
- Где: Внутри одного ядра CPU.
- Аналогия: Один повар с одним широким ножом режет 16 морковок сразу.
MIMD (Multiple Instruction, Multiple Data)
- Что это: Много инструкций работают с многими данными.
- Где: Это ваш многоядерный процессор.
- Аналогия: 8 разных поваров (ядер) на одной кухне. Каждый повар делает свою задачу (один режет, другой варит, третий мешает) со своими продуктами. Это параллелизм на уровне задач.
SIMT (Single Instruction, Multiple Threads)
- Что это: 1 инструкция выполняется тысячами «потоков».
- Где: Это GPU (видеокарты).
- Аналогия: Огромный цех с 5000 «поваров-стажеров» (ядер GPU). У каждого одна морковка. Шеф-повар (контроллер) кричит «РЕЗАТЬ!», и все 5000 стажеров одновременно делают одно режущее движение. Это как SIMD, но в чудовищном масштабе.
SIMD — это параллелизм внутри одного ядра. MIMD — это параллелизм между ядрами. SIMT — это массовый параллелизм GPU.
Заключение
SIMD — это невидимый, но абсолютно незаменимый «работяга» в каждом современном процессоре. В эпоху, когда рост чистой тактовой частоты (ГГц) практически остановился, именно SIMD стал одним из главных инструментов повышения реальной производительности. Он позволяет процессору превратиться из «мастера-штучника», обрабатывающего по одному числу, в «эффективную бригаду», работающую синхронно над целыми массивами данных.
Понимание принципов SIMD сегодня критически важно для всех, кто занимается высокопроизводительными вычислениями. Будь то разработка аналитических баз данных вроде ClickHouse, оптимизация ML-моделей в NumPy или просто понимание того, почему современное программное обеспечение работает так быстро — в основе всего этого лежит простая, но мощная идея: «Одна команда — много данных».
Референсные ссылки
- Intel Intrinsics Guide (Официальный справочник Intel по SIMD-инструкциям) — https://www.intel.com/content/www/us/en/docs/intrinsics-guide/index.html
- SIMD on ARM NEON (Официальная документация ARM) — https://developer.arm.com/architectures/instruction-sets/simd-isas/neon
- A gentle introduction to SIMD (Введение в SIMD) — https://stackoverflow.blog/2020/07/08/a-gentle-introduction-to-simd/
- Vectorized Query Execution in Databases (Обзор векторизации в СУБД) — http://www.vldb.org/pvldb/vol11/p2141-kersten.pdf
- How ClickHouse uses SIMD — https://clickhouse.com/blog/clickhouse-performance-on-arm-and-x86_64