 339
339 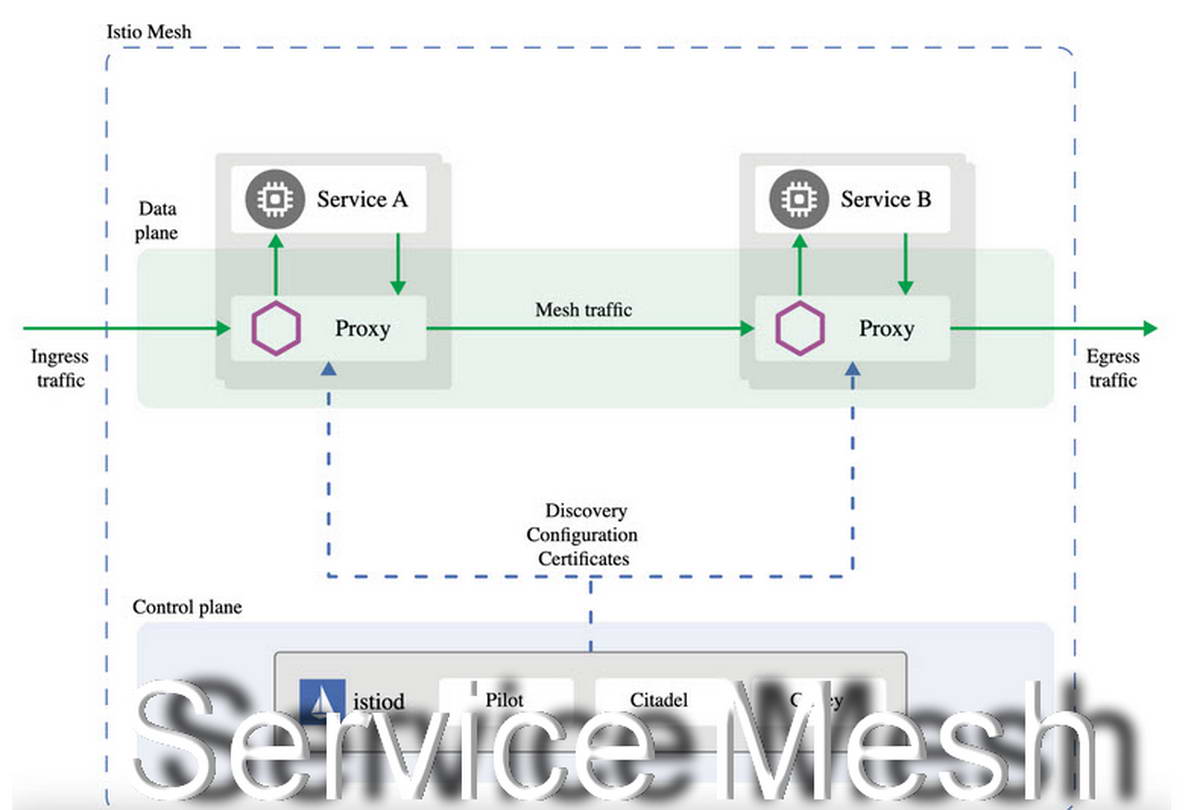
Содержание
- Эволюция проблемы: от Монолита к Хаосу
- Архитектура и Анатомия Service mesh
- Data Plane (Плоскость данных)
- Control Plane (Плоскость управления)
- Паттерн Sidecar: Как это работает "под капотом"
- Ключевые возможности и сценарии использования Service mesh топологии
- Управление трафиком (Traffic Management)
- Безопасность (Security)
- Наблюдаемость (Observability)
- Service Mesh vs API Gateway: В чем разница?
- Настройка Circuit Breaker в Istio
- Будущее технологии: eBPF и Sidecar-less
- Когда Mesh вам НЕ нужен
- Заключение
- Референсные ссылки
Service Mesh (сервисная сетка) — это инфраструктурный слой для управления сетевыми взаимодействиями между микросервисами, обеспечивающий наблюдаемость, маршрутизацию, безопасность и отказоустойчивость сервис-к-сервису без изменения прикладного кода.
Если представить микросервисы как сотрудников большой корпорации, то Service Mesh — это не сами сотрудники, а корпоративная телефонная сеть, система пропусков, видеонаблюдение и отдел логистики в одном флаконе. Сотрудники (сервисы) просто делают свою работу, не задумываясь о том, как их сообщение дойдет до коллеги в другом отделе — этим занимается инфраструктура.
Эволюция проблемы: от Монолита к Хаосу
Чтобы понять суть Service Mesh, нужно оглянуться назад. В эпоху монолитных приложений (Monolith) все компоненты жили в одном адресном пространстве. Вызов функции был просто обращением к памяти. Это было быстро и надежно. Сеть в этом уравнении практически не участвовала.
Однако индустрия перешла к микросервисам. Приложение распилили на десятки и сотни маленьких частей, разбросанных по разным серверам и дата-центрам. Теперь «вызов функции» превратился в сетевой HTTP/gRPC запрос.
И тут инженеры столкнулись с суровой реальностью, которую описывают как «8 заблуждений распределенных вычислений«
- Сеть надежна (нет, кабели рвутся).
- Задержка равна нулю (нет, скорость света конечна).
- Пропускная способность бесконечна (каналы забиваются).
- Сеть безопасна (данные могут перехватить).
- Топология не меняется (серверы постоянно появляются и исчезают).
- Администратор всегда только один (в большой распределенной компании особенно)
- Цена передачи данных нулевая ( оборудование, облако, провайдеры альтруисты)
- Сеть однородна ( у вас только Windows 95 …..)
Раньше разработчики решали эти проблемы внутри кода (Application Layer). В каждом микросервисе на Java, Go или Python приходилось писать библиотеки для повторных попыток (retries), шифрования и балансировки. Это приводило к «жирному» коду (fat client), который сложно поддерживать.
Service Mesh забрал эту ответственность у разработчиков и спустил её на уровень ниже — в инфраструктуру.
Архитектура и Анатомия Service mesh
Классическая архитектура Service Mesh, такая как в Istio или Linkerd, строго разделена на две логические части. Это разделение критически важно для производительности и масштабируемости.
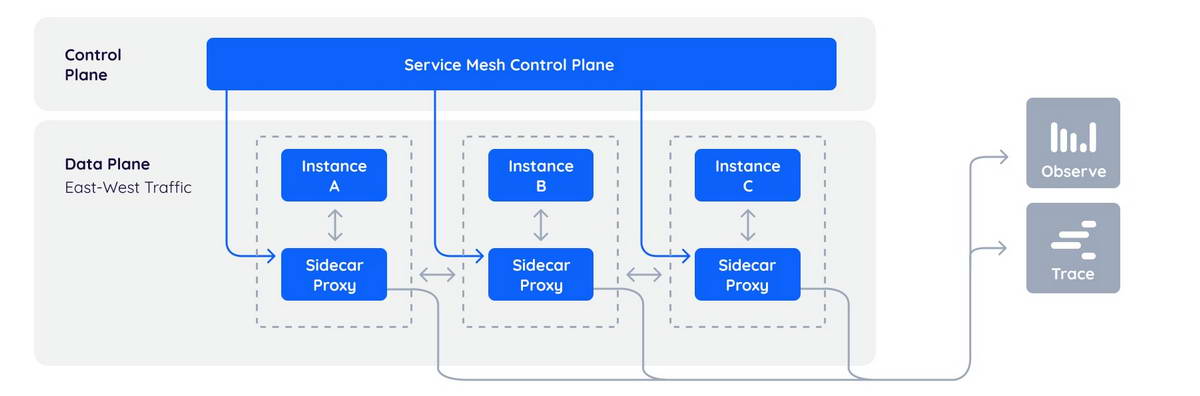
Data Plane (Плоскость данных)
Это «рабочие лошадки» системы. Data Plane состоит из множества интеллектуальных прокси-серверов. Они располагаются рядом с каждым экземпляром вашего приложения.
Эти прокси перехватывают абсолютно все сетевые пакеты. Когда Сервис А хочет поговорить с Сервисом Б, он не шлет запрос напрямую.
- Запрос выходит из Сервиса А.
- Мгновенно перехватывается локальным прокси (Sidecar A).
- Прокси А решает, куда направить запрос, шифрует его и отправляет по сети.
- Прокси Б (Sidecar B) получает запрос, расшифровывает его, проверяет права доступа.
- Только после этого запрос попадает в Сервис Б.
Control Plane (Плоскость управления)
Это «мозг» системы. Прокси-серверы в Data Plane сами по себе глупы: они просто исполняют правила. Правила им выдает Control Plane.
В задачи плоскости управления входит:
- Service Discovery: Знать, где находится каждый сервис и жив ли он.
- Конфигурация: Рассылка правил маршрутизации (например, «отправляй 10% трафика на версию v2»).
- Сертификаты: Выпуск и ротация TLS-сертификатов для шифрования.
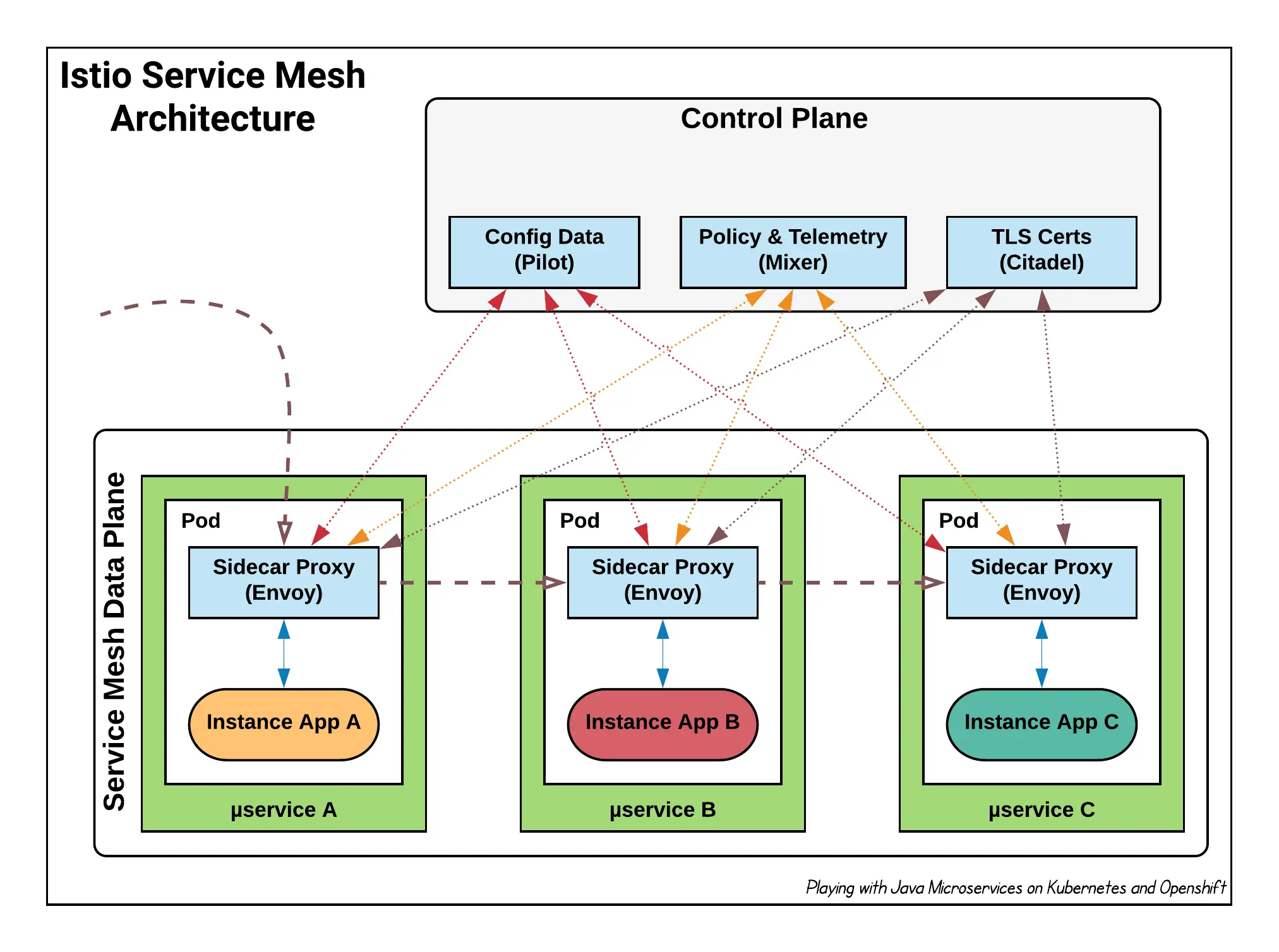
Таким образом, администратор взаимодействует с Control Plane (пишет конфиги), а Control Plane управляет тысячами прокси в Data Plane.
Паттерн Sidecar: Как это работает «под капотом»
Самая популярная модель развертывания прокси — это паттерн Sidecar («мотоцикл с коляской»).
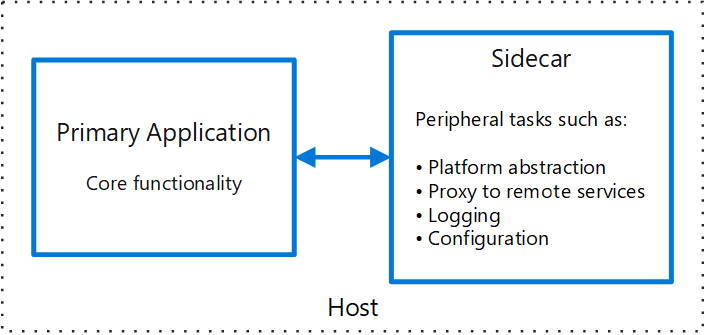
В Kubernetes минимальной единицей деплоя является Pod. Pod может содержать один или несколько контейнеров, которые делят общие ресурсы сети (один IP-адрес) и диски.
При внедрении Service Mesh в каждый под к вашему контейнеру с приложением (мотоцикл) автоматически добавляется контейнер с прокси (коляска). Обычно это делается через механизм MutatingAdmissionWebhook при создании пода, так что разработчику даже не нужно править YAML-файлы деплоймента.
Магия iptables
Чтобы приложение не знало о прокси, Service Mesh настраивает правила iptables (брандмауэр Linux) внутри пода. Эти правила «насильно» заворачивают весь входящий и исходящий трафик в порт, который слушает прокси-сервер (например, Envoy). Для приложения это выглядит прозрачно: оно думает, что общается с внешним миром, но на самом деле говорит только со своей «коляской».
Ключевые возможности и сценарии использования Service mesh топологии
Функционал Service Mesh можно разделить на три большие группы: Traffic Management, Security и Observability. Разберем их на конкретных примерах.
Управление трафиком (Traffic Management)
Это не просто балансировка нагрузки. Это интеллектуальное управление потоками.
- Канареечные релизы (Canary Releases): Вы выкатываете новую версию сервиса, но боитесь багов. Через Mesh вы настраиваете правило: «Направлять на новую версию только запросы от пользователей из группы ‘beta-testers’ или только 1% от общего потока». Если метрики в норме, вы постепенно увеличиваете процент.
- Circuit Breaking (Размыкание цепи): Представьте, что один из микросервисов начал тормозить и отвечать по 30 секунд. Если другие сервисы будут продолжать его долбить и ждать ответа, «ляжет» вся система (эффект домино). Mesh видит это и «размыкает цепь»: он перестает посылать запросы к больному сервису, мгновенно возвращая ошибку 503. Это дает сервису время восстановиться.
- Retry Logic (Повторные попытки): Если сетевой пакет потерялся, прокси может сам повторить запрос. Причем сделать это умно (exponential backoff), чтобы не «задушить» целевой сервис.
Безопасность (Security)
В классической сети внутри периметра часто царит «доверие по умолчанию». Если злоумышленник проник внутрь кластера, он может обращаться к любым сервисам. Service Mesh реализует концепцию Zero Trust.
- mTLS (Mutual TLS): Весь трафик между сервисами шифруется. Причем это не просто HTTPS. Это взаимная аутентификация. Сервис А доказывает Сервису Б, что он именно Сервис А, предъявляя криптографический сертификат.
- Автоматическая ротация: Самое сложное в сертификатах — их обновлять. Control Plane делает это автоматически, обновляя сертификаты прокси каждые несколько часов без простоя системы.
- Authorization Policies: Вы можете настроить правила: «Сервису Frontend можно делать GET-запросы к сервису Users, но нельзя делать POST». Это работает на уровне сети, приложение не сможет это обойти.
Наблюдаемость (Observability)
Поскольку весь трафик проходит через прокси, Mesh видит всё. Без добавления единой строчки кода вы получаете:
- Метрики (Metrics): RED-метрики (Rate, Errors, Duration) для каждого сервиса. Вы точно знаете, какой сервис тормозит.
- Распределенная трассировка (Distributed Tracing): Mesh добавляет специальные заголовки к запросам (trace IDs), позволяя визуализировать путь запроса через всю цепочку микросервисов в системах типа Jaeger или Zipkin.
- Логи доступа (Access Logs): Единый формат логов для всех HTTP-вызовов.
Практическая архитектура данных
Код курса
PRAR
Ближайшая дата курса
20 апреля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Service Mesh vs API Gateway: В чем разница?
Новички часто путают эти понятия. Давайте разграничим зоны ответственности.
- API Gateway (Шлюз): Отвечает за трафик North-South (Север-Юг). То есть за трафик, который приходит от внешних клиентов (браузеры, мобильные приложения) внутрь вашего кластера. Его задачи: аутентификация пользователей, управление тарифами, кэширование статики для внешнего мира.
- Service Mesh: Отвечает за трафик East-West (Восток-Запад). Это трафик внутри кластера, между вашими микросервисами.
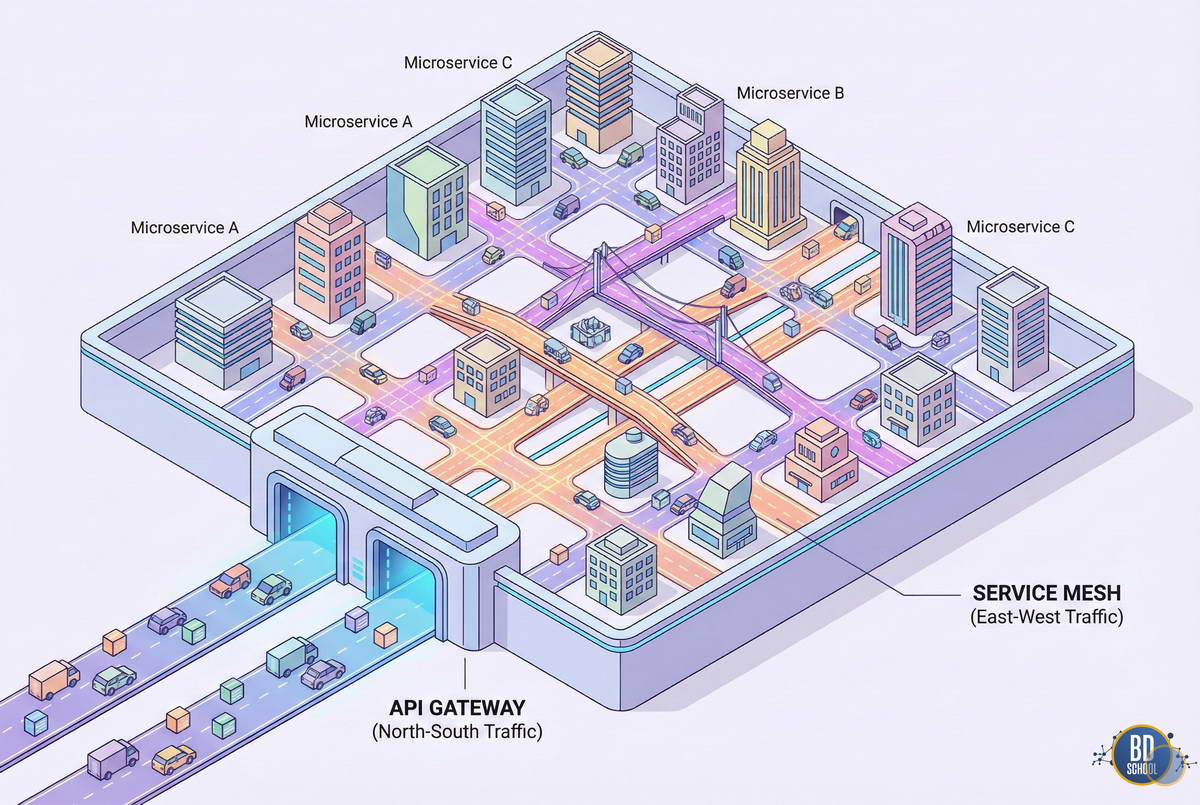
Вывод: API Gateway стоит «на входе» в вашу крепость, а Service Mesh управляет движением внутри крепости. В современной архитектуре они часто используются вместе. Более того, многие Ingress-контроллеры (например, Istio Ingress Gateway) являются частью экосистемы Mesh.
Настройка Circuit Breaker в Istio
Посмотрим, как выглядит конфигурация паттерна «Предохранитель» (Circuit Breaker) в Istio. Мы хотим защитить сервис booking от перегрузки.
Для этого используется ресурс DestinationRule
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: booking-circuit-breaker
spec:
host: booking
trafficPolicy:
connectionPool:
tcp:
maxConnections: 100 # Максимум 100 TCP соединений
http:
http1MaxPendingRequests: 1 # Не более 1 запроса в очереди ожидания
maxRequestsPerConnection: 1
outlierDetection:
consecutive5xxErrors: 5 # Если 5 раз подряд вернулась ошибка 5xx
interval: 10s # Проверять каждые 10 секунд
baseEjectionTime: 30s # "Выкинуть" под из балансировки на 30 сек
maxEjectionPercent: 100 # Можно выкинуть все поды, если все сломались
Что делает этот код? Он говорит прокси-серверам: «Если какой-то экземпляр сервиса booking вернет ошибку 5 раз подряд, считай его мертвым и не посылай на него трафик в течение 30 секунд». Это спасает систему от каскадных сбоев, и, что важно, сам сервис booking не содержит ни строчки кода для реализации этой логики.
Будущее технологии: eBPF и Sidecar-less
Классическая модель с Sidecar-контейнерами имеет недостатки. Запуск дополнительного контейнера для каждого пода потребляет ресурсы (CPU и память). Если у вас 1000 микросервисов, вы запускаете 1000 прокси. Это может увеличить потребление ресурсов кластера на 30-50%.
Поэтому индустрия движется в сторону eBPF (Extended Berkeley Packet Filter). Это технология, позволяющая запускать песочницы с кодом прямо в ядре Linux.
Новые реализации Service Mesh (например, Cilium Service Mesh или режим Istio Ambient Mesh) предлагают архитектуру без сайдкаров (Sidecar-less).
Вместо того чтобы ставить прокси к каждому сервису, используется один мощный прокси на узле (Node), работающий на уровне ядра. Это значительно снижает накладные расходы и ускоряет передачу данных, так как пакеты не нужно копировать между пространствами пользователя и ядра так часто.
Когда Mesh вам НЕ нужен
Service Mesh — это мощный инструмент, но он не бесплатный. И речь не только о деньгах на серверы.
- Сложность (Complexity Tax). Вы добавляете в систему критически важный компонент. Если Control Plane упадет или будет настроен неправильно, ляжет всё взаимодействие. Отладка проблем становится сложнее: «Почему сервис А не видит сервис Б? Это баг в приложении, проблема сети Kubernetes или кривой конфиг Istio?».
- Задержки (Latency). Даже самый быстрый прокси добавляет задержку. В модели Sidecar каждый запрос проходит через прокси дважды (выход из А, вход в Б). Это добавляет единицы миллисекунд (2-5 мс). Для систем высокочастотного трейдинга это может быть неприемлемо.
- Кривая обучения. Инженерам нужно учить новые абстракции (VirtualService, Gateway, EnvoyFilter). На рынке не так много специалистов, глубоко понимающих, как дебажить Envoy.
Чек-лист «Нужен ли мне Service Mesh?»:
- [ ] У вас более 30-50 микросервисов?
- [ ] Вы используете разные языки программирования (Polyglot environment)?
- [ ] Вам критически важно шифрование mTLS (требования безопасности, PCI DSS)?
- [ ] Вам нужна сложная маршрутизация (A/B тесты, канарейки) на постоянной основе?
Если вы ответили «Нет» на большинство вопросов — скорее всего, стандартных средств Kubernetes (Service, Ingress, NetworkPolicies) вам пока достаточно.
Практическая архитектура данных
Код курса
PRAR
Ближайшая дата курса
20 апреля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Заключение
Service Mesh — это неизбежный этап эволюции для крупных облачных систем. Он отделяет логику приложения от логики сети, позволяя каждой части развиваться независимо. Разработчики пишут бизнес-функции, а платформенные инженеры настраивают надежность и безопасность через конфигурации Mesh.
Несмотря на сложность внедрения, для зрелых компаний выгоды от Наблюдаемости (Observability) и Единого управления (Control Plane) перевешивают затраты. Технология продолжает развиваться, становясь легче и быстрее благодаря eBPF, закрепляя за собой статус стандарта де-факто в мире Cloud Native.