 290
290 
Содержание
- Зачем нужен SDLC современному проекту
- Основные фазы жизненного цикла
- Популярные модели реализации SDLC
- Современный подход: От DevOps к DevSecOps
- Особенности SDLC в Big Data и ML
- Роли и ответственность
- Практический кейс: Автоматизация цикла "Разработка — Тест — Деплой".
- Шаг 1. Подготовка рабочего пространства
- Шаг 2. Изоляция через Virtual Environment (venv)
- Шаг 3. Создание Unit-теста
- Шаг 4. Настройка автоматики (GitHub Actions)
- Шаг 5. Создание файла конфигурации (Workflow)
- Итоговая схема процесса для читателя:
- Заключение
- Референсные ссылки:
SDLC (Software Development Life Cycle) — это структурированный процесс создания программного обеспечения, который описывает каждый этап разработки от идеи до вывода из эксплуатации. Понимание этого цикла позволяет командам выпускать качественный продукт в прогнозируемые сроки и в рамках бюджета. В сфере Big Data и ML этот процесс становится критически важным. Он помогает синхронизировать работу инженеров данных, аналитиков и бизнес-заказчиков.
Без четкого SDLC разработка превращается в хаотичное исправление ошибок. Это приводит к росту технического долга и потере денег. Методология же дает прозрачность. Она позволяет измерять эффективность команды на каждом отрезке пути.
Зачем нужен SDLC современному проекту
Основная цель цикла — минимизация рисков. Программные продукты сегодня стали слишком сложными для интуитивной разработки. SDLC решает несколько фундаментальных задач бизнеса.
Прогнозируемость. Менеджеры понимают, когда будет готов функционал.
- Четкие временные рамки.
- Обоснованное распределение бюджета.
Качество продукта. Ошибки находят на ранних стадиях.
- Стандартизация процессов тестирования.
- Снижение стоимости исправления багов.
Эффективность команды. Каждый знает свою зону ответственности.
- Устранение дублирования задач.
- Улучшение коммуникации между отделами.
Следование жизненному циклу гарантирует, что итоговое приложение соответствует ожиданиям пользователя. Это особенно важно в высоконагруженных системах обработки данных.
Основные фазы жизненного цикла
Классический SDLC состоит из последовательных шагов. Каждый этап имеет свои входные данные и ожидаемый результат. Пропуск любой фазы обычно ведет к катастрофическим последствиям на этапе эксплуатации.
Анализ требований
На этом этапе происходит сбор информации от заказчика. Архитекторы и аналитики определяют, что именно должна делать система. Итогом становится документ SRS (Software Requirements Specification). Здесь фиксируются функциональные требования и технические ограничения проекта.
Проектирование (Design)
Инженеры создают архитектурный план системы. На этом уровне принимаются решения о выборе стека технологий и баз данных.
Выбор архитектуры. Определение структуры монолита или микросервисов.
- Проектирование схем данных.
- Описание API для взаимодействия компонентов.

Разработка и кодинг
Это самая длительная фаза цикла. Программисты пишут код согласно проектной документации. В Big Data проектах здесь создаются ETL по расписанию: 4 способа планирования запусков DAG в Apache AirFlow и алгоритмы обработки. Код обязательно проходит процедуру ревью для соблюдения стандартов качества.
Тестирование (QA)
Специалисты проверяют продукт на соответствие требованиям. Это включает юнит-тесты, интеграционное и нагрузочное тестирование. В современных проектах этот этап максимально автоматизируется. Если найдены критические баги, разработка возвращается на предыдущий шаг.
Внедрение и сопровождение
Готовый продукт разворачивается в рабочей среде (Production). После релиза начинается стадия поддержки. Разработчики исправляют мелкие недочеты и оптимизируют производительность. Это бесконечный процесс до тех пор, пока продукт актуален.
Разработка и внедрение ML-решений
Код курса
MLOPS
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
Популярные модели реализации SDLC
Существует множество подходов к организации этих этапов. Выбор зависит от размера команды и изменчивости требований заказчика.
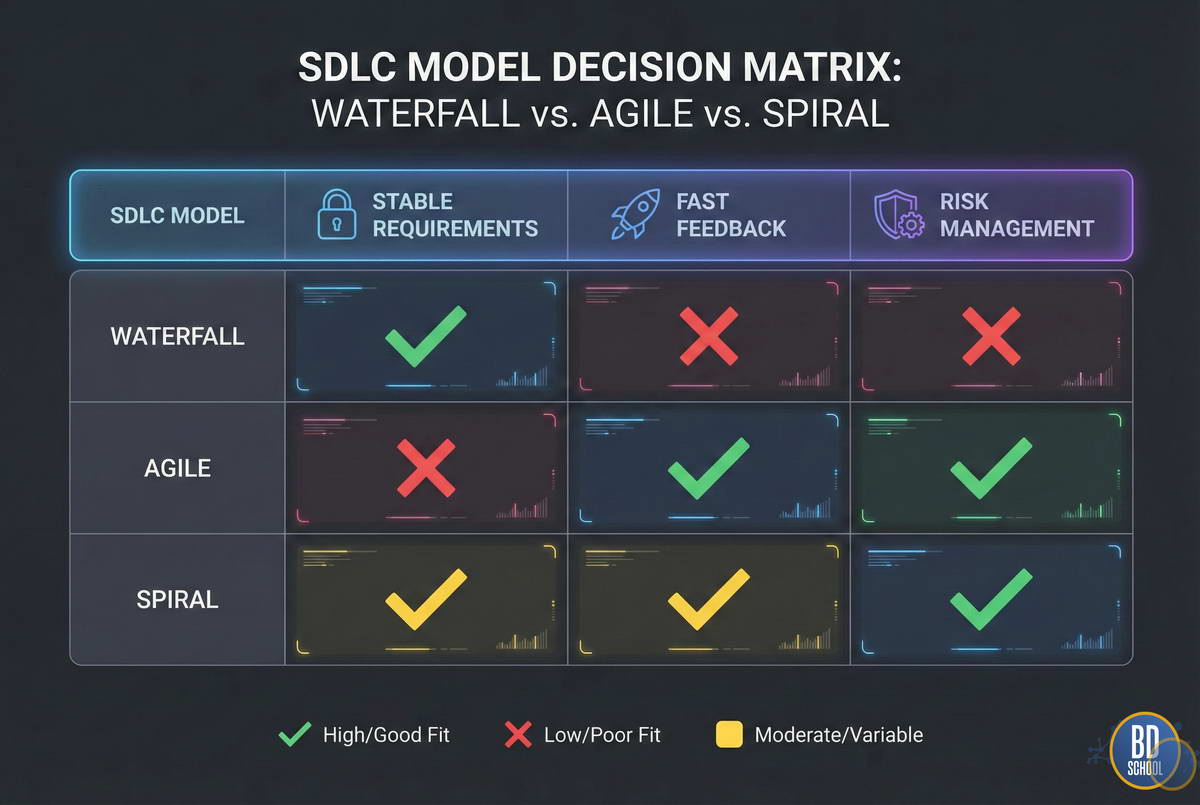
Waterfall (Каскад). Строго последовательное прохождение всех стадий.
- Переход к новому этапу только после завершения предыдущего.
- Подходит для проектов с жестко фиксированными требованиями.
- Минус: сложно внести изменения в середине пути.
Agile (Гибкая разработка). Итеративный подход, где продукт создается маленькими частями.
- Циклы (спринты) длятся 2-4 недели.
- Постоянная обратная связь от пользователя.
- Максимальная адаптивность к изменениям рынка.
Spiral (Спиральная модель). Усиленный фокус на анализе рисков.
- Каждый виток спирали включает этап оценки угроз.
- Идеально для сложных и дорогостоящих систем.
Современный подход: От DevOps к DevSecOps
Современная разработка стремится к непрерывности. Подход DevOps объединяет разработку и эксплуатацию в единый поток. Это позволяет деплоить код десятки раз в день без потери стабильности.
Автоматизация (CI/CD). Сборка и деплой происходят автоматически.
- Continuous Integration: частая интеграция кода в общий репозиторий.
- Continuous Deployment: автоматический выпуск изменений в прод.
DevSecOps. Внедрение безопасности (Security) в каждый шаг SDLC.
- Проверка уязвимостей начинается на этапе написания кода.
- Автоматические сканеры зависимостей в пайплайне.
- Защита данных становится частью культуры разработки.
Такой подход позволяет находить дыры в безопасности до того, как они попадут в сеть. Это критично для систем, работающих с персональными данными.
Особенности SDLC в Big Data и ML
Разработка систем обработки данных отличается от создания обычных веб-приложений. Здесь код вторичен по отношению к данным. Если данные «отравлены» или имеют плохое качество, никакой идеальный код не спасет систему.
Экспериментальный характер. В ML невозможно гарантировать результат заранее.
- Этап исследования данных (EDA) предшествует разработке.
- Постоянное переобучение моделей требует цикличного подхода.
Data Lifecycle. Жизненный цикл данных накладывается на SDLC.
- Важность отслеживания происхождения данных (Data Lineage).
- Валидация схем данных на этапе CI/CD.
В этой среде классический SDLC эволюционирует в MLOps и DataOps. Эти дисциплины добавляют в цикл этапы мониторинга качества данных и дрейфа моделей.
Роли и ответственность
В рамках SDLC за успех отвечают разные специалисты. Разделение ролей помогает избежать конфликтов интересов.
Product Owner. Формулирует видение продукта и приоритеты.
- Сбор бизнес-требований.
- Управление бэклогом задач.
System Architect. Отвечает за техническую структуру.
- Выбор технологий и паттернов.
- Контроль масштабируемости системы.
DevOps Engineer. Строит мост между кодом и «железом».
- Настройка серверов и пайплайнов.
- Обеспечение отказоустойчивости.
QA Engineer. Гарантирует, что продукт работает как надо.
- Создание тестовых сценариев.
- Контроль качества релизов.
Координация этих людей — залог того, что жизненный цикл не прервется из-за человеческого фактора.
ML Практикум: от теории к промышленному использованию
Код курса
PYML
Ближайшая дата курса
30 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
Практический кейс: Автоматизация цикла «Разработка — Тест — Деплой».
В этом примере мы пройдем путь от написания кода до его автоматического запуска в изолированном виртуальном окружении на локальном сервере Ubuntu (или WSL).
Шаг 1. Подготовка рабочего пространства
Сначала создаем структуру проекта в Ubuntu. Это имитация нашего «сервера», где будет жить работающее приложение.
# Создаем папку и заходим в нее
mkdir -p ~/sdlc_demo && cd ~/sdlc_demo
# Создаем файл скрипта-обработчика
cat <<EOF > processor.py
import sys
def run_logic(data):
if not data:
raise ValueError("Empty data")
return [x * 10 for x in data]
if __name__ == "__main__":
test_data = [1, 2, 3]
print(f"Обработка: {run_logic(test_data)}")
EOF
Шаг 2. Изоляция через Virtual Environment (venv)
Чтобы зависимости проекта не конфликтовали с системными библиотеками Ubuntu, используем виртуальное окружение. Это стандарт современного SDLC.
# Создаем окружение python3 -m venv venv # Активируем и проверяем source venv/bin/activate pip3 install pytest # Нам понадобится для тестов
Шаг 3. Создание Unit-теста
Автоматизация не имеет смысла без проверки качества. Создадим тест, который пайплайн будет запускать перед каждым деплоем.
cat <<EOF > test_processor.py
from processor import run_logic
import pytest
def test_success():
assert run_logic([1]) == [10]
def test_fail():
with pytest.raises(ValueError):
run_logic([])
EOF
И файл requirements
cd ~/sdlc_demo cat <<EOF > requirements.txt pytest EOF
Шаг 4. Настройка автоматики (GitHub Actions)
Теперь связываем твой репозиторий с Ubuntu через GitHub Self-hosted Runner. Это позволит GitHub отдавать команды твоему локальному терминалу.
В интерфейсе GitHub:
- Перейди в Settings -> Actions -> Runners.
- Нажми New self-hosted runner и выбери Linux.
- Выполни предложенные команды в терминале Ubuntu.

Шаг 5. Создание файла конфигурации (Workflow)
Создай файл .github/workflows/main.yml. Он станет «дирижером» нашего процесса.
name: SDLC_Automation
on: [push]
jobs:
build-and-run:
runs-on: self-hosted
steps:
- name: Checkout code
uses: actions/checkout@v4 # Раннер скачивает код в свою папку _work
- name: Setup Environment
run: |
# Создаем виртуальное окружение прямо внутри папки раннера
python3 -m venv venv_ci
source venv_ci/bin/activate
pip3 install pytest # Устанавливаем зависимости с нуля
- name: Run Tests
run: |
source venv_ci/bin/activate
# Указываем Python искать модули в текущей папке
PYTHONPATH=. pytest test_processor.py
- name: Deploy (Manual log update)
run: |
source venv_ci/bin/activate
# А вот здесь мы можем запустить скрипт и дотянуться до твоего лога
python3 processor.py >> $HOME/sdlc_demo/production.log
echo "Авто-деплой выполнен: $(date)" >> $HOME/sdlc_demo/production.log
Примечание: Мы опускаем фрагмент настройки взаимодействия GitHub с нашим сервером оставляя лишь несколько итоговых скриншотов
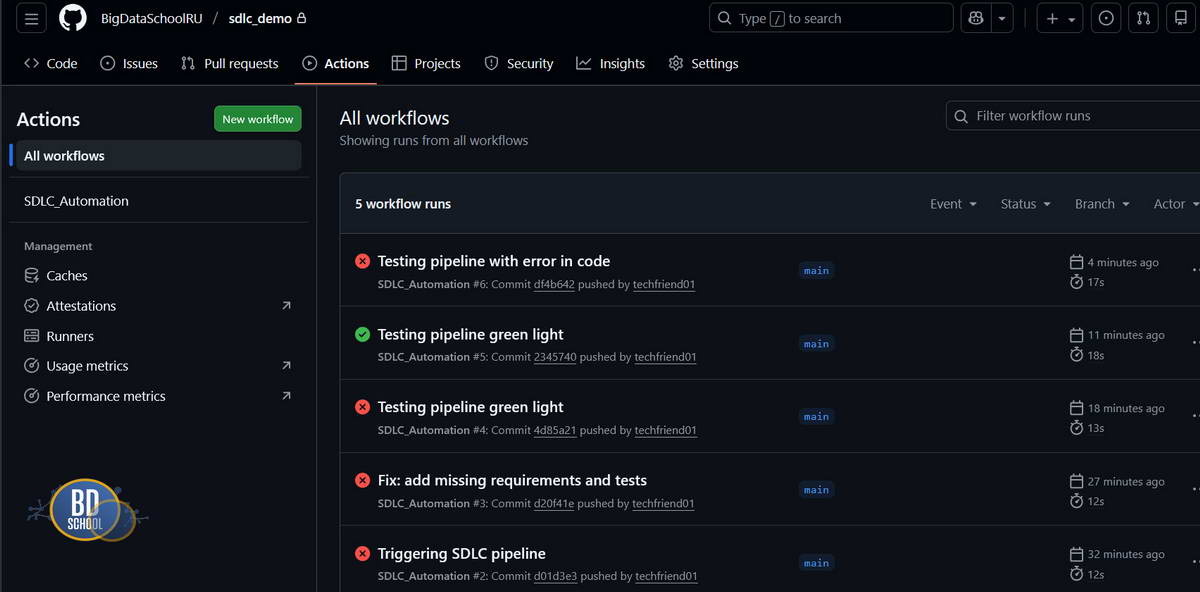
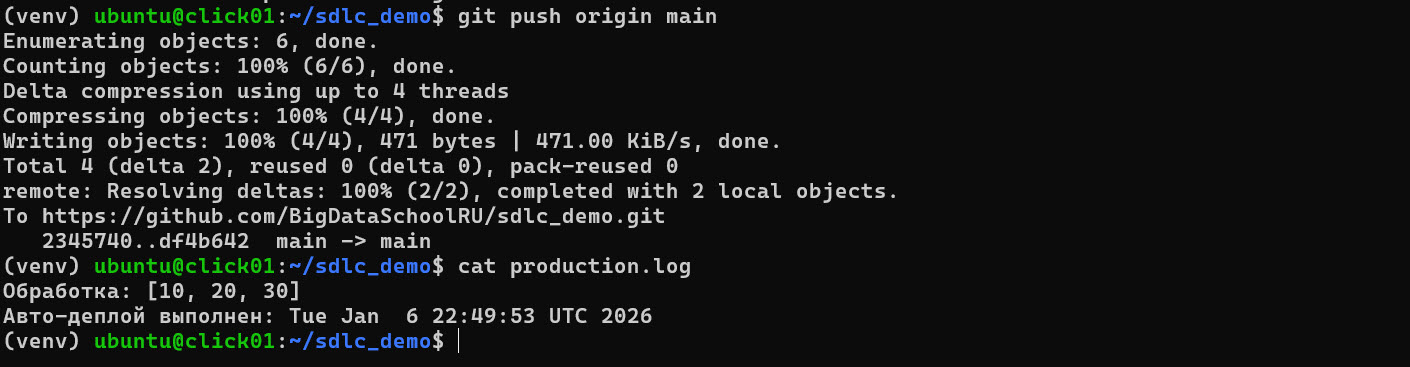
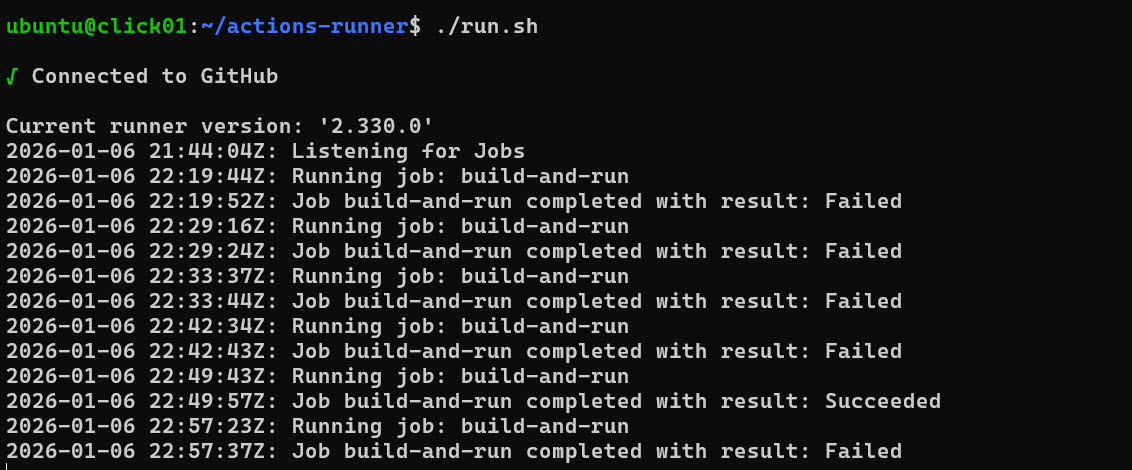
Итоговая схема процесса для читателя:
Написание кода. Разработчик правит processor.py и делает git push.
- Триггер. GitHub замечает изменения и запускает Runner в твоей Ubuntu.
- Контроль качества. Runner активирует venv и прогоняет тесты.
- Релиз. Если тесты «зеленые», скрипт запускается в рабочей среде и пишет результат в лог.
Это превращает теоретический SDLC в живой механизм, где вероятность ошибки в «проде» сводится к минимуму.
Этот код может запускаться автоматически при каждой попытке программиста сохранить изменения. Если тесты падают, процесс SDLC блокирует переход к этапу внедрения. Это базовый пример автоматизации контроля качества.
Заключение
SDLC — это не бюрократия, а карта выживания проекта. Правильно выбранная модель позволяет команде расти и выпускать надежные продукты. В эпоху Big Data этот цикл дополняется инструментами MLOps, делая процесс еще более надежным. Начинайте с малого, автоматизируйте проверки и всегда помните о требованиях бизнеса.
Референсные ссылки:
- [IEEE Standard for Software Life Cycle Processes] (https://standards.ieee.org/standard/12207-2017.html) (2024 update reference)
- [What is SPLC? — Amazon AWS Guide] (https://aws.amazon.com/what-is/sdlc/) (2025)
- [The DevOps Handbook: Second Edition] (https://itrevolution.com/book/the-devops-handbook/) (2024 version)
- [Google SRE Book — Release Engineering] (https://sre.google/sre-book/release-engineering/) (2025)