 1538
1538 
Содержание
RAG (Retrieval-Augmented Generation) — это архитектурный подход в области искусственного интеллекта, который объединяет мощь больших языковых моделей (LLM) с внешними, авторитетными базами знаний. Проще говоря, это технология, которая учит языковые модели не выдумывать ответы, а находить их в проверенных источниках и на их основе генерировать осмысленный текст. RAG был разработан для решения двух фундаментальных проблем стандартных LLM: склонности к «галлюцинациям» (созданию правдоподобной, но ложной информации) и ограниченности знаний моментом их последнего обучения.
Можно представить стандартную LLM как очень эрудированного, но немного забывчивого эксперта, который не читал ничего нового за последние пару лет. RAG же дает этому эксперту доступ к огромной, постоянно обновляемой библиотеке. Прежде чем ответить на вопрос, модель сначала обращается к этой библиотеке, находит релевантные факты, и только потом формулирует свой ответ. Этот процесс «заземления» на внешние данные делает ответы LLM значительно более точными, надежными и актуальными. Как следствие, RAG превращает языковые модели из простого инструмента для генерации текста в мощную систему для работы со знаниями.
Архитектура RAG: два ключевых компонента
В основе любого RAG-решения лежат два фундаментальных компонента, работающих в тандеме. Каждый из них выполняет свою уникальную, но взаимодополняющую функцию. Понимание их ролей — ключ к пониманию всей архитектуры.
Ретривер (The Retriever):
Это «поисковый движок» или «библиотекарь» всей системы. Его задача — не генерировать текст, а эффективно и быстро находить наиболее релевантную информацию в огромном массиве данных в ответ на запрос пользователя. Процесс его работы обычно включает несколько этапов:
- Индексация: Все внешние документы (статьи, PDF-файлы, записи в базе данных) загружаются, разбиваются на логические фрагменты (чанки) и преобразуются в числовые представления — векторы (embeddings).
- Хранение: Эти векторы хранятся в специализированной векторной базе данных (например, Pinecone, Weaviate, Chroma), которая оптимизирована для сверхбыстрого поиска по сходству.
- Поиск: Когда поступает запрос пользователя, он также векторизуется, и ретривер ищет в базе данных те фрагменты документов, чьи векторы наиболее близки к вектору запроса.
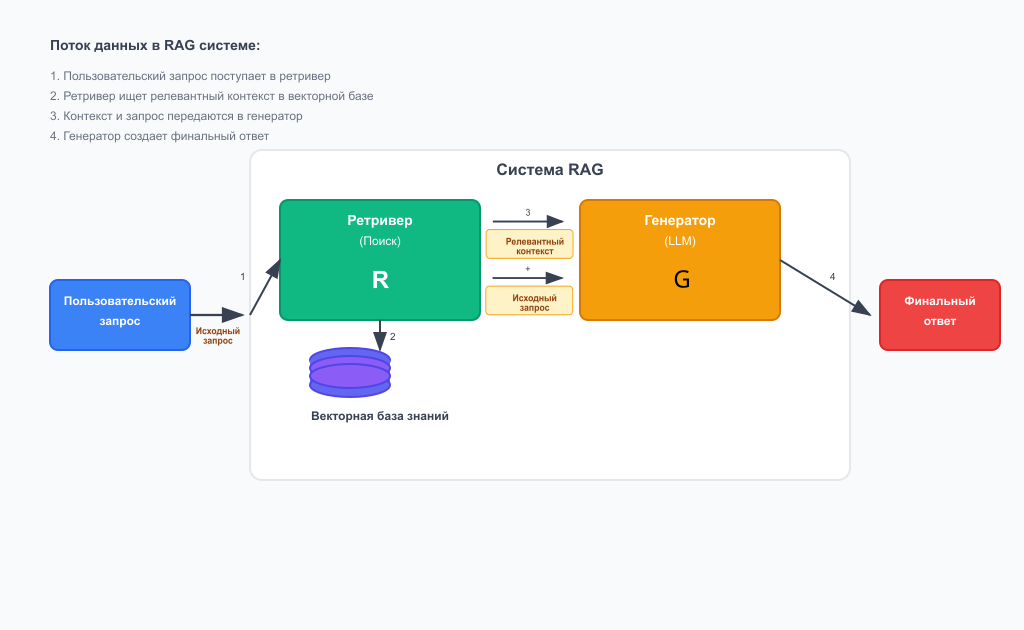
Генератор (The Generator):
Это «красноречивый писатель» — большая языковая модель (например, GPT-4, Llama 3). В отличие от стандартного использования, в RAG-архитектуре генератор получает не просто исходный вопрос пользователя, а «обогащенный» промпт. Этот промпт включает в себя как сам вопрос, так и фрагменты релевантной информации, найденные ретривером. Получив такую подробную инструкцию с фактическим материалом, LLM генерирует окончательный ответ, который является синтезом ее собственных лингвистических способностей и предоставленных ей конкретных данных.
Архитектура ML-систем
Код курса
ARML
Ближайшая дата курса
13 апреля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Принцип работы RAG: пошаговый процесс
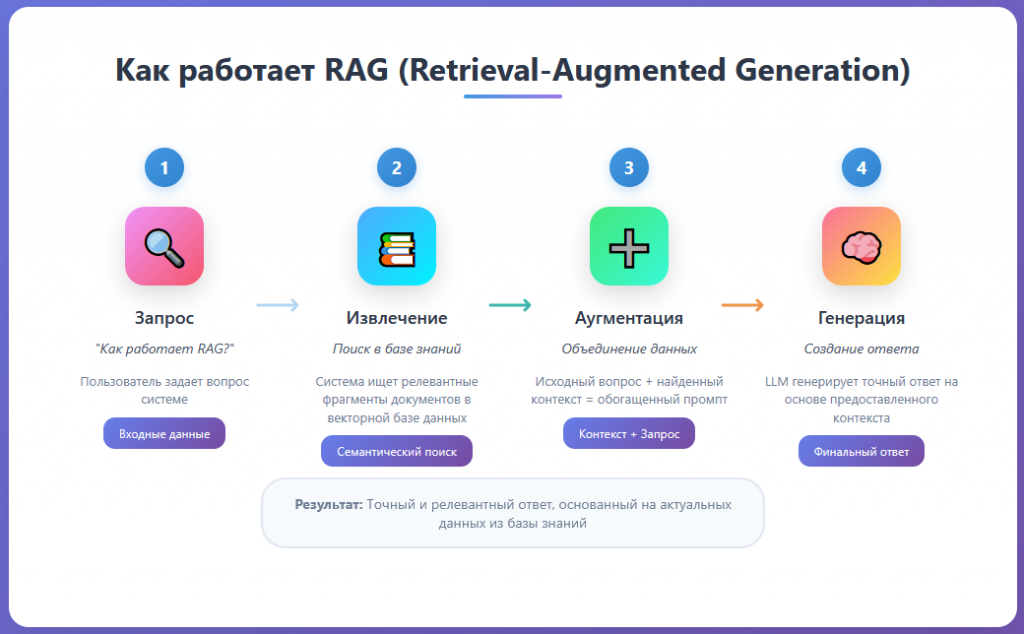
Весь процесс работы RAG-системы можно разбить на четыре четких и последовательных шага. Эта цепочка превращает простой вопрос в подробный и фактически обоснованный ответ.
Запрос (Query): Пользователь формулирует и отправляет свой вопрос в систему. Например: «Какие ключевые преимущества у архитектуры RAG?».
Извлечение (Retrieval): Система не спешит отправлять этот вопрос напрямую в LLM. Сначала ретривер преобразует текст вопроса в вектор и выполняет поиск по векторной базе данных. Он находит несколько наиболее релевантных фрагментов текста из проиндексированных документов, которые с наибольшей вероятностью содержат ответ.
Аугментация (Augmentation): На этом ключевом этапе происходит «обогащение» промпта. Система формирует новый, расширенный промпт для языковой модели. Он обычно имеет следующую структуру: «Используя следующий контекст: [здесь вставляются фрагменты, найденные ретривером], ответь на вопрос пользователя: [здесь вставляется исходный вопрос]».
Генерация (Generation): Обогащенный промпт отправляется в LLM (генератор). Модель анализирует предоставленный контекст и на его основе формулирует связный и точный ответ. Таким образом, ответ генерируется не из абстрактных «воспоминаний» модели, а на основе конкретных, поданных ей на вход фактов.
Практическое применение RAG и его ключевые преимущества
Благодаря своей надежности и гибкости, архитектура RAG нашла широкое применение в создании практичных AI-решений, особенно в корпоративной среде.
Сценарии применения:
- Чат-боты для корпоративных баз знаний: Компании создают RAG-системы, которые отвечают на вопросы сотрудников на основе внутренних документов: политик, инструкций, регламентов и технических спецификаций.
- Автоматизация клиентской поддержки: Чат-боты могут мгновенно находить ответы на вопросы клиентов в руководствах пользователя, FAQ и статьях базы знаний, снижая нагрузку на операторов.
- Образовательные платформы и научные исследования: Системы могут помогать студентам и ученым быстро находить и суммировать информацию из больших объемов учебных материалов или научных статей.
Ключевые преимущества:
- Значительное снижение галлюцинаций: Поскольку модель генерирует ответ на основе предоставленных фактов, вероятность выдумывания информации резко снижается.
- Актуальность данных: Для обновления знаний системы не нужно переобучать дорогостоящую LLM. Достаточно просто добавить, обновить или удалить документы во внешней базе знаний.
- Прозрачность и цитирование: RAG-системы могут указывать источники, на основе которых был сгенерирован ответ. Это повышает доверие пользователя и позволяет ему проверить информацию.
- Экономическая эффективность: Развертывание и поддержка RAG-пайплайна в большинстве случаев значительно дешевле, чем регулярное дообучение (fine-tuning) или полное переобучение больших языковых моделей.
Создание базового RAG-пайплайна: инструменты и код
Создание RAG-системы — это процесс сборки конвейера из нескольких ключевых компонентов. Современные фреймворки значительно упрощают эту задачу.
Необходимые инструменты:
- Фреймворки-оркестраторы: LangChain и LlamaIndex являются отраслевыми стандартами. Они предоставляют готовые модули для загрузки документов, их векторизации, взаимодействия с векторными базами данных и LLM.
- Модель для эмбеддингов: Модель, которая превращает текст в векторы (например, text-embedding-ada-002 от OpenAI, Sentence-Transformers).
- Векторная база данных: Место для хранения и поиска векторов. Для локальной разработки часто используют Chroma или FAISS, для облачных решений — Pinecone или Weaviate.
- Языковая модель (LLM): Генератор ответов, доступный через API (например, GPT-4, Claude 3).
Концептуальный пример кода (на основе логики LangChain):
# 1. Загрузка и подготовка документов
from langchain.document_loaders import DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Загружаем все текстовые файлы из директории
loader = DirectoryLoader('./knowledge_base/', glob="*.txt")
documents = loader.load()
# Разбиваем документы на небольшие чанки
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
chunks = text_splitter.split_documents(documents)
# 2. Создание векторного хранилища
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
# Инициализируем модель для создания векторов
embeddings = OpenAIEmbeddings()
# Создаем векторную базу данных из чанков
vector_store = Chroma.from_documents(chunks, embeddings)
# 3. Настройка RAG-цепочки
from langchain.chat_models import ChatOpenAI
from langchain.schema.runnable import RunnablePassthrough
from langchain.prompts import PromptTemplate
# Настраиваем ретривер для поиска
retriever = vector_store.as_retriever()
# Создаем шаблон промпта
template = """
Используя следующий контекст, ответь на вопрос.
Контекст: {context}
Вопрос: {question}
"""
prompt = PromptTemplate.from_template(template)
# Инициализируем LLM
llm = ChatOpenAI(model_name="gpt-4")
# Собираем все вместе в единую цепочку (пайплайн)
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
)
# 4. Запуск и получение ответа
query = "Какие ключевые преимущества у архитектуры RAG?"
response = rag_chain.invoke(query)
print(response.content)
RAG против Fine-Tuning: что и когда выбирать?
RAG и дообучение (fine-tuning) — это два разных подхода к адаптации LLM, и они решают разные задачи. Понимание их отличий критически важно для выбора правильной стратегии. Основное различие заключается в том, что мы меняем. RAG — это метод добавления внешних, легко обновляемых знаний. Модель учится использовать эти знания «на лету». Fine-tuning — это процесс изменения внутренних весов самой модели, чтобы научить ее новому поведению, стилю или глубоким, неявным знаниям в определенной области.
Когда выбирать RAG:
- Вам нужно, чтобы ответы были основаны на конкретных, часто меняющихся документах (например, новости, техническая документация, юридические документы).
- Требуется высокая степень фактической точности и возможность ссылаться на источники.
- Бюджет и время ограничены; RAG быстрее и дешевле во внедрении и поддержке.
Когда выбирать Fine-Tuning:
- Вам нужно, чтобы модель освоила специфический стиль речи, формат ответа или сложный жаргон (например, медицинский или юридический).
- Знания, которые вы хотите привить, являются общими для всей предметной области, а не содержатся в конкретных документах.
- Вам нужно изменить само поведение модели, а не просто предоставить ей факты.
Часто наилучшие результаты дает гибридный подход: сначала модель дообучается (fine-tuning) для понимания специфического стиля и терминологии, а затем используется в RAG-системе для получения актуальных и точных ответов из конкретных документов.
ИИ-агенты для оптимизации бизнес-процессов
Код курса
AGENT
Ближайшая дата курса
18 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
Вызовы и ограничения RAG-подхода
Несмотря на свои очевидные преимущества, RAG не является универсальным решением и сопряжен с рядом технических вызовов, которые необходимо учитывать при разработке.
- Качество извлечения (Retrieval Quality): Это самое слабое звено и главная проблема. Если ретривер находит нерелевантные или некачественные фрагменты документов, LLM, даже самая продвинутая, сгенерирует плохой ответ. Эффективность всей системы зависит от того, насколько хорошо работает ее «поисковик».
- Стратегия разделения на чанки (Chunking): Способ, которым исходные документы нарезаются на фрагменты, оказывает огромное влияние на качество поиска. Слишком маленькие чанки могут не содержать полного контекста, а слишком большие — содержать много «шума», который запутает LLM.
- Сложность и задержка (Complexity & Latency): RAG-пайплайн — это многоступенчатая система (запрос -> векторизация -> поиск -> генерация). Каждый этап добавляет задержку, поэтому ответ от RAG-системы почти всегда будет медленнее, чем прямой запрос к LLM.
- Оценка качества: Измерить производительность RAG-системы непросто. Необходимо оценивать как качество найденных документов (точность и полнота ретривера), так и качество финального ответа (релевантность и отсутствие галлюцинаций), что требует разработки комплексных метрик.
Заключение
Retrieval-Augmented Generation (RAG) представляет собой мощный сдвиг от парадигмы «всезнающих» монолитных языковых моделей к более гибким, модульным и надежным AI-системам. Интегрируя LLM с внешними базами знаний, RAG напрямую решает критические проблемы точности и актуальности информации, превращая языковые модели из творческих генераторов текста в практические инструменты для работы со знаниями. Хотя внедрение RAG и сопряжено с определенными техническими вызовами, его преимущества — снижение галлюцинаций, прозрачность и экономическая эффективность — делают этот подход отраслевым стандартом для создания корпоративных и клиентских AI-ассистентов. В конечном счете, RAG — это не просто технология, а фундаментальная архитектура, которая делает искусственный интеллект более ответственным, полезным и заслуживающим доверия.
Референсные ссылки
- Оригинальная научная статья от исследователей Facebook AI https://arxiv.org/abs/2005.11401
- Объяснение архитектуры с примерами от Pinecone https://www.pinecone.io/learn/retrieval-augmented-generation/
- Практическое руководство по созданию RAG-приложений https://docs.langchain.com/docs/use_cases/question_answering/
- Обзор современных техник RAG от NVIDIA https://blogs.nvidia.com/blog/what-is-retrieval-augmented-generation/