 354
354 
Содержание
- Архитектура и «Магия» скорости
- Как не потерять данные: RDB vs AOF
- Репликация и высокая доступность
- Больше чем просто «Ключ-Значение»: Структуры данных
- Сценарии использования Redis в Big Data и Web
- Взаимодействие и примеры кода (Python)
- Redis vs Остальной мир
- Redis vs Memcached
- Redis Pub/Sub vs Apache Kafka
- Топ-5 ошибок новичка
- Заключение
- Референсные ссылки
Redis (Remote Dictionary Server) — это высокопроизводительное in-memory хранилище данных типа key-value, поддерживающее различные структуры данных и используемое для кэширования, очередей, сессий и real-time-сценариев благодаря низкой задержке и горизонтальному масштабированию.
В мире больших данных и веб-разработки скорость отклика часто является критическим фактором успеха. Традиционные дисковые базы данных не всегда успевают обрабатывать запросы мгновенно. Здесь на помощь приходит Redis. Он работает как база данных, кэш и брокер сообщений. В отличие от простого кэша, Redis позиционирует себя как «сервер структур данных». Это означает, что вы можете хранить не только простые строки, но и сложные объекты: списки, множества и хеш-таблицы. Главная особенность системы заключается в хранении всех данных в RAM (оперативной памяти). Это обеспечивает субмиллисекундное время отклика. Благодаря этому Redis стал стандартом де-факто для высоконагруженных систем.
Архитектура и «Магия» скорости
Понимание внутреннего устройства Redis помогает использовать его эффективно. Его архитектура спроектирована для максимальной скорости при минимальных накладных расходах. Она отличается от привычных реляционных баз данных и даже от своего ближайшего конкурента — Memcached..
Однопоточная модель (Event Loop)
Многие новички удивляются, узнав, что Redis обрабатывает команды в одном потоке. На первый взгляд это кажется узким местом. Однако это осознанное инженерное решение.
Основные преимущества однопоточной модели:
- Отсутствие переключения контекста. Процессору не нужно тратить ресурсы на переключение между потоками.
- Отсутствие блокировок (Race Conditions). Нет необходимости в сложных механизмах синхронизации доступа к данным.
- Эффективность CPU. Все ресурсы процессора идут на выполнение команд, а не на администрирование потоков.
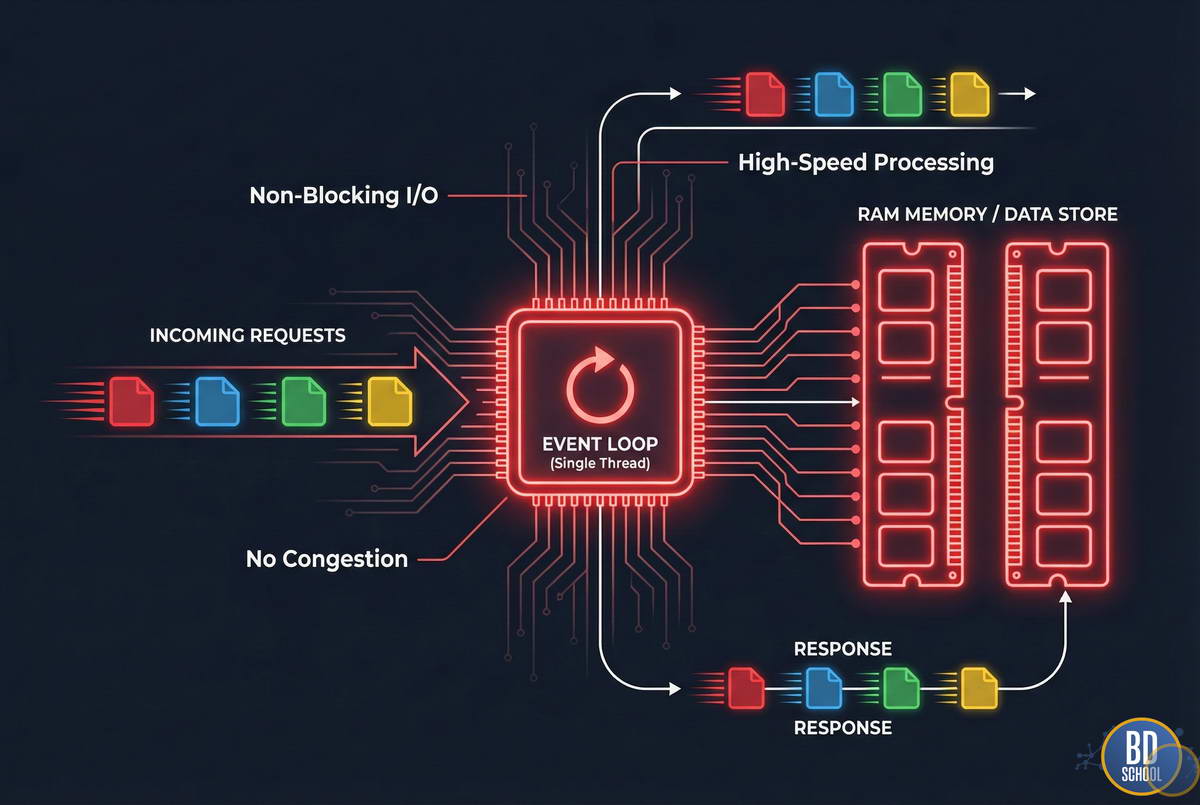
Redis использует механизм ввода-вывода I/O multiplexing (через epoll или kqueue). Это позволяет ему обрабатывать тысячи подключений одновременно. Фактическим бутылочным горлышком чаще становится сеть, а не процессор.
Как не потерять данные: RDB vs AOF
Redis предлагает два механизма сохранения данных на диск. Часто их используют вместе, но важно понимать разницу между ними.
RDB (Redis Database Backup)
Это создание «снимков» (snapshots) памяти через заданные интервалы времени. Например, «сохранять каждые 5 минут, если изменилось 100 ключей».
- Плюс: Компактные файлы, идеальны для бэкапов и быстрого старта сервера.
- Минус: Если сервер упадет, вы потеряете данные за последние 5 минут.
AOF (Append Only File)
В этом режиме Redis записывает каждую операцию изменения данных (каждую команду SET, INCR и т.д.) в конец файла-лога.
- Плюс: Максимальная надежность. Можно настроить запись на диск каждую секунду или даже при каждом запросе.
- Минус: Файл лога растет быстрее, и восстановление из него занимает больше времени, чем из RDB.
Выбор стратегии зависит от бизнес-требований: важна ли абсолютная надежность или допустима потеря пары минут данных ради производительности.
Репликация и высокая доступность
В продакшене одного сервера часто бывает недостаточно. Для масштабирования чтения и отказоустойчивости используют репликацию. Redis поддерживает архитектуру Master-Replica. Данные пишутся в мастер, а читаются с реплик.
Для автоматического восстановления при сбоях применяют Redis Sentinel. Это система мониторинга. Если мастер падает, Sentinel автоматически выбирает новую главную ноду из реплик. Для горизонтального масштабирования записи используют Redis Cluster. Он распределяет данные по нескольким узлам (шардинг).
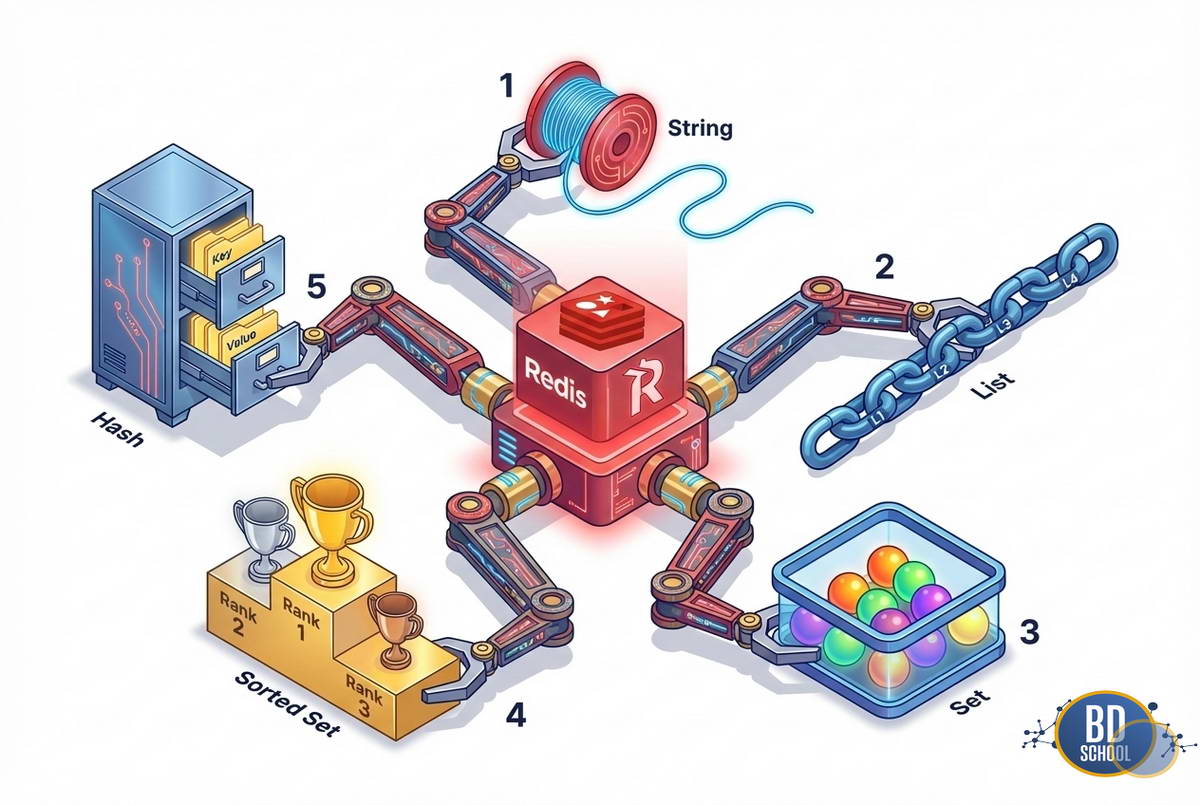
Больше чем просто «Ключ-Значение»: Структуры данных
Сила Redis не только в скорости, но и в богатом наборе типов данных. Это не просто key-value хранилище, а сервер структур данных. Выбор правильной структуры позволяет решать сложные алгоритмические задачи прямо в базе.
Основные типы данных включают:
- Strings (Строки): Базовый тип. Может хранить текст, сериализованный JSON, изображения или счетчики.
- Lists (Списки): Связные списки строк. Идеальны для реализации простых очередей или стеков.
- Sets (Множества): Неупорядоченные наборы уникальных строк. Позволяют быстро находить пересечения и объединения.
- Hashes (Хэши): Карты полей и значений. Подходят для хранения профилей пользователей или объектов.
Кроме базовых, существуют специализированные типы для аналитики и ранжирования.
Sorted Sets (ZSET)
Это одна из самых мощных структур в Redis. Элементы в множестве уникальны, но каждому присвоен балл (score). Данные автоматически сортируются по этому баллу.
Это позволяет мгновенно получать топ-лидерборды. Например, можно хранить ID игроков и их очки. Операция получения топ-10 игроков будет выполняться молниеносно. ZSET также используют для индексов и временных рядов.
HyperLogLog и Bitmap
В Big Data часто нужно считать уникальные события, экономя память. Хранить миллионы ID пользователей в Set слишком дорого. Для таких задач используют вероятностные структуры:
- HyperLogLog: Позволяет подсчитать количество уникальных элементов (cardinality) с погрешностью менее 1%. При этом он занимает фиксированные 12 КБ памяти, независимо от числа элементов.
- Bitmap: Работает с битами. Позволяет эффективно хранить информацию типа «был ли пользователь онлайн сегодня». Миллионы статусов занимают всего мегабайты.
Эти структуры незаменимы при анализе трафика и поведенческих факторов.
Сценарии использования Redis в Big Data и Web
Redis находит применение практически в любом современном архитектурном стеке. Его гибкость позволяет закрывать самые разные потребности бизнеса.
Рассмотрим наиболее частые паттерны использования:
- Кэширование: Самый популярный сценарий. Хранение результатов тяжелых SQL-запросов или вычислений. Это снижает нагрузку на основную БД.
- Сессии пользователей: Хранение токенов авторизации и данных профиля. Быстрый доступ к сессии ускоряет загрузку страниц.
- Rate Limiting: Ограничение количества запросов к API. Счетчики Redis с TTL (временем жизни) позволяют легко блокировать спам.
- Real-time аналитика: Сбор метрик, просмотров и кликов в реальном времени. Данные агрегируются в памяти и сбрасываются в хранилище пачками.
Каждый из этих сценариев существенно повышает отзывчивость системы.
Практическая архитектура данных
Код курса
PRAR
Ближайшая дата курса
20 апреля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Взаимодействие и примеры кода (Python)
Чтобы работать с Key-Value хранилищем, нам нужно два компонента: запущенный сервер и клиентская библиотека (драйвер). Рассмотрим процесс на примере самой популярной связки: Redis и Python.
Шаг 1: Подготовка окружения (Запуск сервера Key Value store REDIS )
Перед написанием кода нужно поднять сервер Redis. Самый простой способ сделать это без установки лишнего софта в систему — использовать контейнеры.
Вариант А: Docker (Рекомендуемый) Если у вас установлен Docker, выполните одну команду в терминале. Она скачает официальный образ и запустит Redis на стандартном порту.
docker run --name local-redis -p 6379:6379 -d redis
Вариант Б: WSL (Windows Subsystem for Linux) Если вы используете Ubuntu внутри Windows, установка выполняется через стандартный пакетный менеджер.
# Обновляем списки пакетов и ставим сервер sudo apt update sudo apt install redis-server # Запускаем службу sudo service redis-server start
Теперь ваш локальный сервер Redis готов к работе и слушает порт 6379.
Шаг 2: Python Script
Python имеет отличную библиотеку redis-py. Она предоставляет интерфейс, максимально похожий на нативные команды Redis. Сначала установите её:
#--запускаем venv python3 -m venv venv/ source venv/bin/activate #Для более наглядной демонстрации работы кода доустановим библиотеку rich pip3 install redis rich
Шаг 3: Python Script паттерна Producer-Consumer
Этот код — классический пример паттерна Producer-Consumer (Производитель-Потребитель) с использованием Redis в двух ролях: как базы данных для профилей и как брокера сообщений.
Что происходит на самом деле
-
Слой хранения (Hash): Когда вызывается r.hset, данные пользователя улетают в Redis и ложатся там в структуру «Хеш». Это как мини-таблица или словарь внутри Redis. Ключ user:101 позволяет мгновенно достать имя или почту, не перебирая всё подряд.
-
Слой очереди (List): r.lpush кладет только ID пользователя в список. Это «сигнал» для системы, что с этим юзером надо что-то сделать (например, отправить письмо).
-
Слой обработки (Worker): Воркер не «спрашивает» базу каждую секунду «есть работа?». Благодаря brpop (Blocking Right Pop), он просто засыпает, пока Redis сам не «толкнет» его, когда в списке появится новый ID. Это максимально эффективно для ресурсов.
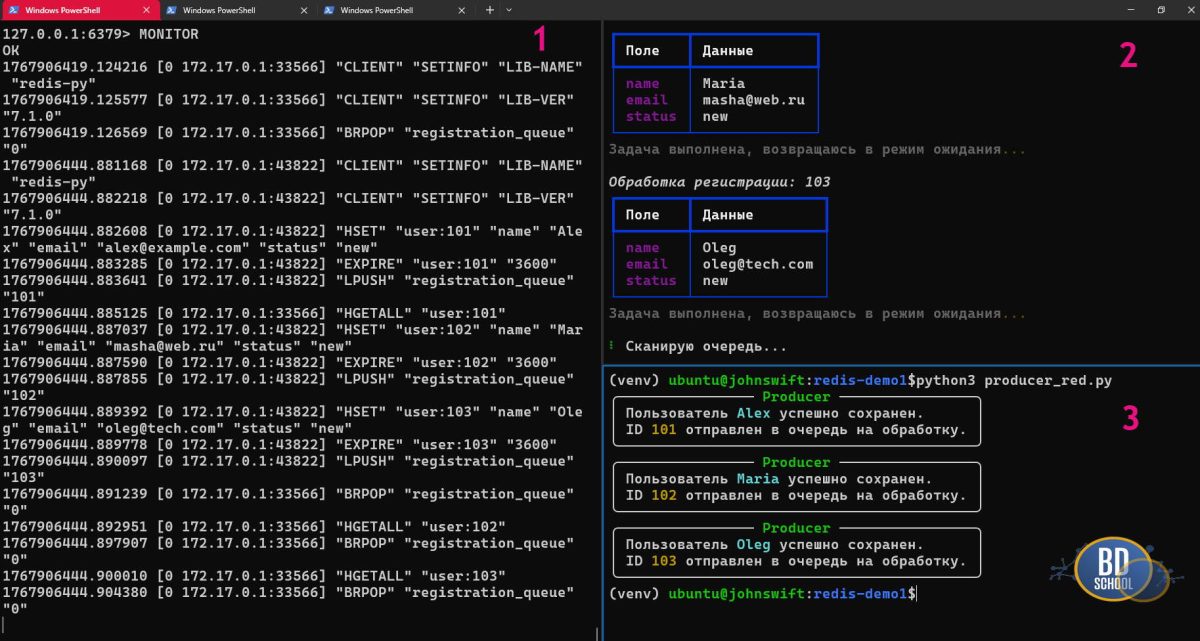
Для более наглядной демонстрации работы кода откроем 3 окна терминала одновременно.
- В первом откроем redis-cli с командой MONITOR Запустите её перед выполнением скрипта. Она в реальном времени покажет каждую команду, которую присылает Python.
- Во втором запустите скрипт worker.py (consumer). Этот скрипт должен быть запущен постоянно. Он «спит», пока в Redis пусто, и мгновенно просыпается при появлении нового ID.
import redis
from rich.console import Console
from rich.table import Table
from rich.status import Status
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
console = Console()
def start_worker():
console.print("[bold yellow]Воркер запущен. Ожидание задач...[/] (Ctrl+C для выхода)")
while True:
# Используем статус-спиннер для красоты ожидания
with Status("Сканирую очередь...", spinner="dots"):
# brpop возвращает кортеж: (имя_очереди, значение)
task = r.brpop("registration_queue", timeout=0)
user_id = task[1]
# Достаем полные данные из Hash по полученному ID
user_info = r.hgetall(f"user:{user_id}")
if user_info:
table = Table(title=f"Обработка регистрации: {user_id}", border_style="blue")
table.add_column("Поле", style="magenta")
table.add_column("Данные", style="white")
for key, value in user_info.items():
table.add_row(key, value)
console.print(table)
console.print("[dim]Задача выполнена, возвращаюсь в режим ожидания...\n")
else:
console.print(f"[bold red]Ошибка:[/] Данные для ID {user_id} не найдены в Redis!")
if __name__ == "__main__":
try:
start_worker()
except KeyboardInterrupt:
console.print("\n[bold red]Воркер остановлен вручную.[/]")
- В третьем окне терминала запустим скрипт producer.py. Этот скрипт отвечает за создание данных. Представьте, что это часть кода, которая срабатывает при регистрации нового пользователя.
import redis
from rich.console import Console
from rich.panel import Panel
# Настройки подключения
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
console = Console()
def create_user(user_id, name, email):
user_key = f"user:{user_id}"
user_data = {
"name": name,
"email": email,
"status": "new"
}
# 1. Пишем в Hash (основное хранилище)
r.hset(user_key, mapping=user_data)
r.expire(user_key, 3600) # Срок жизни 1 час
# 2. Пишем ID в List (очередь для воркера)
r.lpush("registration_queue", user_id)
console.print(Panel(
f"Пользователь [bold cyan]{name}[/] успешно сохранен.\n"
f"ID [yellow]{user_id}[/] отправлен в очередь на обработку.",
title="[bold green]Producer[/]",
expand=False
))
if __name__ == "__main__":
# Имитируем несколько регистраций
users = [
(101, "Alex", "alex@example.com"),
(102, "Maria", "masha@web.ru"),
(103, "Oleg", "oleg@tech.com"),
]
for u_id, name, mail in users:
create_user(u_id, name, mail)
В случае необходимости масштабировать workers вы можете открыть дополнительные терминалы с worker.py и Redis сам распределеит задачи между ними.
Redis vs Остальной мир
Выбор инструмента всегда зависит от конкретной задачи. Redis часто сравнивают с другими популярными решениями. Важно понимать границы применимости каждой технологии.
Redis vs Memcached
Memcached был королем кэширования до появления Redis. Он также хранит данные в памяти и работает очень быстро.
Однако Redis выигрывает по следующим пунктам:
- Структуры данных: Memcached умеет хранить только строки. Redis понимает списки, сеты и хэши.
- Персистентность: Memcached теряет всё при перезагрузке. Redis умеет сохранять данные на диск.
- Репликация: В Redis она есть «из коробки».
Memcached сейчас выбирают только для простейшего кэширования в многопоточной среде, где не нужны сложные функции.
Redis Pub/Sub vs Apache Kafka
Обе системы умеют передавать сообщения, но идеология у них разная. Redis реализует паттерн Pub/Sub (издатель-подписчик) по принципу «fire and forget».
Ключевые отличия подходов:
- Redis Pub/Sub: Сообщения доставляются подписчикам мгновенно. Если подписчик офлайн, сообщение теряется навсегда. История не хранится. Идеально для чатов и уведомлений.
- Apache Kafka: Это лог событий. Сообщения сохраняются на диск. Потребитель может вычитать историю за прошлую неделю. Идеально для критически важных данных и ETL-процессов.
Если вам нужна гарантия доставки и хранения истории, выбирайте Kafka. Если нужна мгновенная скорость и простота — Redis.
Топ-5 ошибок новичка
Даже опытные разработчики иногда совершают ошибки, которые могут «положить» продакшен. Redis мощный, но он требует дисциплины.
Избегайте следующих анти-паттернов:
- Команда KEYS *: Никогда не используйте её в коде приложения. Она ищет ключи перебором. В базе с миллионами ключей это заблокирует сервер на секунды (или минуты). Используйте SCAN.
- Огромные значения: Не храните JSON размером 10 МБ в одном ключе. Это забивает сетевой канал и блокирует поток при чтении. Разбивайте данные.
- Отсутствие TTL: Кэш должен устаревать. Если писать данные без EXPIRE, память рано или поздно закончится. Сервер встанет или начнет вытеснять нужные данные.
- Одна база на всё: Использование одной инстанции Redis для кэша, сессий и очередей опасно. Если кэш переполнит память, очереди тоже перестанут работать. Разделяйте инстансы.
- Синхронные тяжелые операции: Удаление ключа с миллионом элементов внутри может заблокировать сервер. Используйте асинхронное удаление UNLINK вместо DEL.
Соблюдение этих правил спасет ваши нервы и стабильность системы.
Практическое применение Big Data аналитики для решения бизнес-задач
Код курса
PRUS
Ближайшая дата курса
20 апреля, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Заключение
Redis — это не просто кэш, а фундамент современной веб-разработки. Его сила кроется в гибкости: начав с простого ускорения загрузки страниц, вы со временем начнете использовать его для очередей, чатов, гео-поиска и аналитики. Понимание того, как работают структуры данных и персистентность, позволит вам строить отказоустойчивые и молниеносные системы. Если Memcached — это спринтер на короткие дистанции, то Redis — это многоборец, готовый к любым дисциплинам.
Будущее Redis связано с развитием модулей. Redis Stack уже предлагает встроенный поиск (Search), работу с JSON и графовые модели данных. Знание этого инструмента обязательно для любого инженера, работающего с данными.