 308
308 
Содержание
- Что такое Ray и зачем он нужен?
- Развертывание кластера Ray
- Как работает Ray Stack - Архитектура и компоненты
- Ray Core: Фундамент системы
- Экосистема нативных библиотек
- Основные сценарии использования
- Практика: Пишем первый код на Ray
- Ray Framework против Apache Spark - Сравнение кода
- Подводные камни и ограничения
- Заключение
- Референсные ссылки:
Ray — это распределённый фреймворк для параллельных и распределённых вычислений, предназначенный для масштабируемого выполнения задач и управления состоянием в кластере, широко используемый в задачах машинного обучения и обработки данных. Он имеет открытый исходный код. Инструмент создан специально для масштабирования приложений на Python. Код на этом языке часто работает довольно медленно. Главной причиной является глобальная блокировка интерпретатора. Сокращенно ее называют GIL. Она мешает эффективной параллельной работе скриптов. Ray изящно обходит это системное ограничение архитектуры. Фреймворк автоматически распределяет вычисления по всему доступному кластеру. При этом разработчикам не нужно переписывать свой код. Достаточно добавить пару простых декораторов в скрипт. Таким образом, тяжелое машинное обучение ускоряется в несколько раз. В этой статье мы подробно разберем работу инструмента.
Что такое Ray и зачем он нужен?
Язык Python крайне популярен в сфере Data Science. Однако он плохо справляется с настоящей многопоточностью. Это становится серьезной технической проблемой для тяжелых задач. Например, при глубоком обучении огромных нейронных сетей. Компании теряют драгоценное время на ожидание результатов вычислений. Данный инструмент решает эту проблему максимально элегантно. Фреймворк позволяет превратить любой локальный скрипт в распределенный.
Существует несколько весомых причин для выбора этой технологии.
- Высокая простота. Вы практически не меняете исходную логику вашей программы. Добавление декоратора мгновенно делает обычную функцию распределенной.
- Отличная масштабируемость. Код одинаково работает на одном ноутбуке и гигантском кластере. Система сама управляет всеми доступными вычислительными ресурсами.
- Широкая гибкость. Инструмент поддерживает любые популярные библиотеки для машинного обучения. Он невероятно легко интегрируется в уже существующую инфраструктуру. Эти важные преимущества делают систему настоящим стандартом отрасли. Кроме того, платформа активно поддерживается крупным сообществом инженеров. Поэтому новые полезные функции появляются в ней регулярно.
Развертывание кластера Ray
Перед началом полноценной работы систему необходимо правильно развернуть. Развертывание платформы является очень важным подготовительным этапом. Вы можете запустить фреймворк на одном локальном компьютере. Также можно использовать огромный облачный кластер из десятков машин. Процесс инициализации предельно прост и понятен новичкам.
Для запуска кластера используется командная строка вашего сервера. Сначала необходимо запустить главный узел управления. Затем к нему подключаются остальные рабочие машины.
#--- Используем VENV по традиции python3 -m venv venv source venv/bin/active #--- устанавливаем ray pip3 install ray # Запуск главного узла (head node) в консоли ray start --head --port=6379 # Подключение рабочего узла (worker node) к кластеру ray start --address='<ip_главного_узла>:6379'

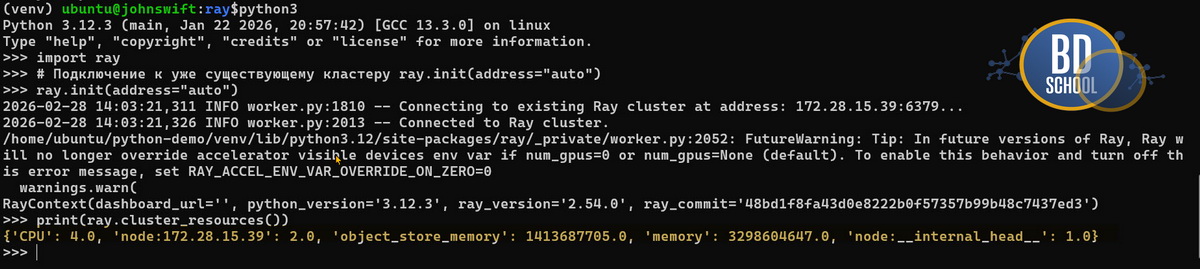
После успешного старта серверов нужно подключить Python-код. В скрипте указывается адрес главного узла кластера.
import ray # Подключение к уже существующему кластеру ray.init(address="auto") # Проверка всех доступных вычислительных ресурсов print(ray.cluster_resources())
Таким образом, ваш скрипт получает доступ ко всем серверам. Он может свободно распределять задачи между рабочими узлами. Это позволяет мгновенно масштабировать любые сложные вычисления.
Не забудьте выключить Ray кластер комнадой ray stop
Высокопроизводительная обработка данных на Python
Код курса
HPPY
Ближайшая дата курса
10 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
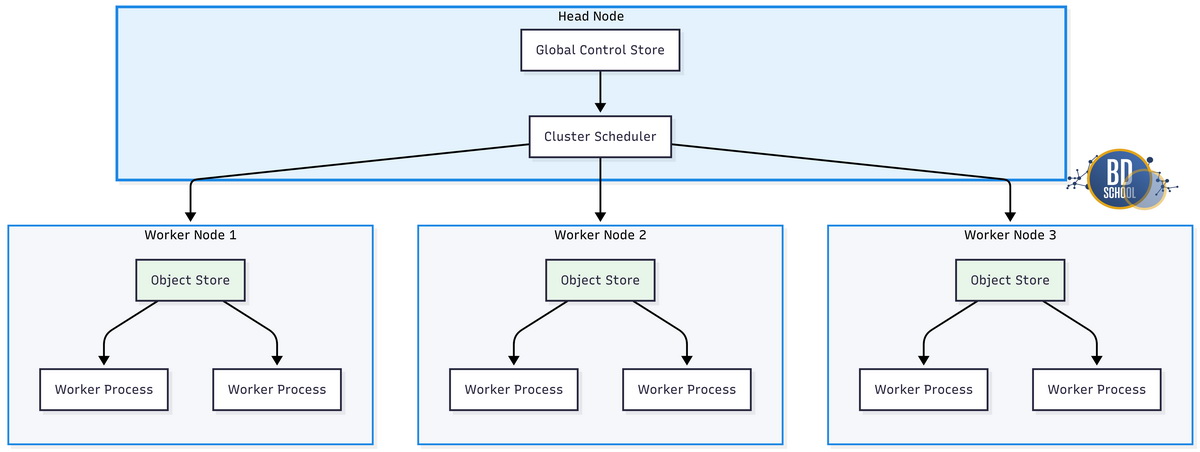
Как работает Ray Stack — Архитектура и компоненты
Архитектура системы Ray спроектирована для обеспечения максимальной производительности. Она надежно скрывает сложность распределенных систем от программиста. В основе фреймворка лежит строгий принцип разделения состояний. Базовый уровень отвечает за распределение памяти и процессов.
Ray Core: Фундамент системы
Базовый уровень берет на себя самую тяжелую работу. Для успешного использования нужно понимать три ключевые концепции. Они составляют фундамент архитектуры всей распределенной платформы.
Концепции включают в себя задачи, акторы и хранилище.
- Задачи. Это обычные функции без сохранения внутреннего состояния. Они выполняются строго асинхронно в разных рабочих процессах.
- Акторы. Это специальные классы с сохранением текущего состояния. Они полезны для долговременного хранения тяжелых моделей.
- Хранилище. Это общая распределенная память для всех серверов. Она построена на базе формата Apache Arrow. Такая структура обеспечивает очень высокую скорость работы. В результате разработчик получает гибкий инструмент для микросервисов. Общая память позволяет мгновенно передавать огромные массивы данных.
Экосистема нативных библиотек
Поверх базового уровня построен набор мощных дополнительных инструментов. Они предназначены для решения конкретных прикладных задач инженеров. Экосистема закрывает все этапы работы с данными.
В состав платформы входят пять основных высокоуровневых компонентов.
- Ray Data. Библиотека для загрузки и быстрой предварительной обработки данных. Она легко масштабируется на сотни рабочих машин.
- Ray Train. Инструмент для распределенного обучения сложных нейросетей. Пакет отлично поддерживает фреймворки PyTorch и TensorFlow.
- Ray Tune. Мощная система для автоматического подбора оптимальных гиперпараметров. Она сильно ускоряет процесс тонкой настройки моделей.
- RLlib. Специализированная библиотека для алгоритмов обучения с подкреплением. Инструмент отличается невероятной производительностью в сложных виртуальных средах.
- Ray Serve. Платформа для развертывания готовых ML-моделей в продакшене. Она позволяет легко обновлять работающие сервисы без простоев.
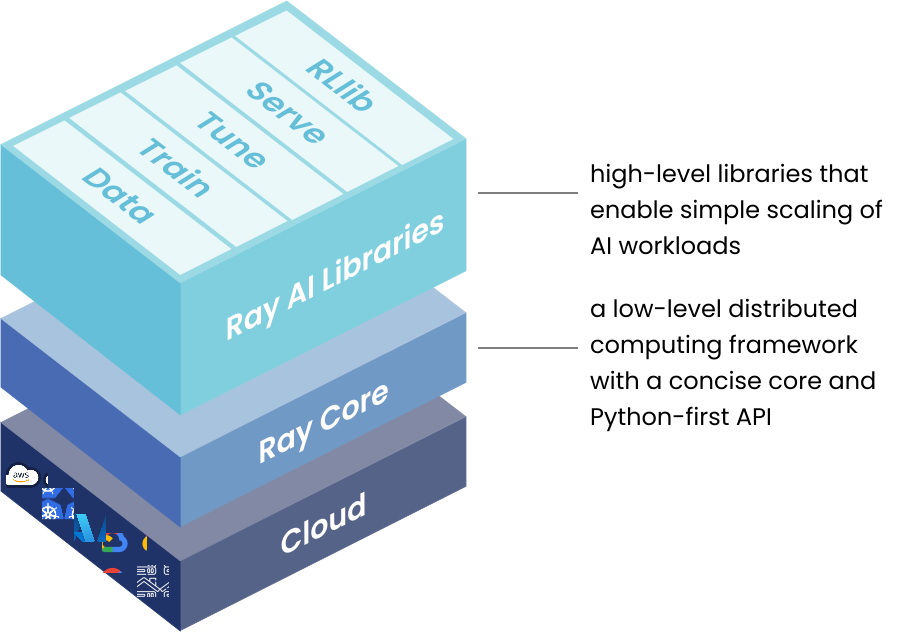
Каждая библиотека может свободно использоваться отдельно от остальных. Однако вместе они создают идеальный конвейер машинного обучения. Это делает экосистему самым универсальным решением на рынке.
Основные сценарии использования
Платформа применяется в самых разных технических бизнес-областях. Чаще всего инструмент используют для ускорения рутинных аналитических процессов. Например, аналитики данных радикально сокращают время обучения нейросетей. То, что раньше занимало целые дни, теперь требует часов.
Кроме того, фреймворк отлично подходит для обработки бесконечных потоков. Крупные корпорации строят на нем сложные рекомендательные системы. Программа анализирует поведение пользователей в режиме реального времени. Затем она практически мгновенно обновляет выдачу персонализированного контента.
Также технология стала незаменимой в сфере финансовых технологий. Крупнейшие банки запускают масштабные симуляции рынковых рисков. Распределенные вычисления позволяют анализировать тысячи сложных сценариев одновременно. Таким образом, бизнес начинает принимать решения намного быстрее.
Высокопроизводительная обработка данных на Python
Код курса
HPPY
Ближайшая дата курса
10 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Практика: Пишем первый код на Ray
Начать работу с платформой очень просто. Сначала нужно установить пакет через стандартный менеджер пакетов. Используйте команду установки в вашем терминале. Затем импортируйте библиотеку в свой скрипт.
Рассмотрим базовый пример использования инструмента на языке Python.
import ray
import time
# Инициализация локального кластера
ray.init()
# Превращаем обычную функцию в задачу Ray
@ray.remote
def slow_function(x):
time.sleep(1)
return x * x
# Запускаем 4 задачи параллельно
futures = [slow_function.remote(i) for i in range(4)]
# Получаем готовые результаты
results = ray.get(futures)
print(results)
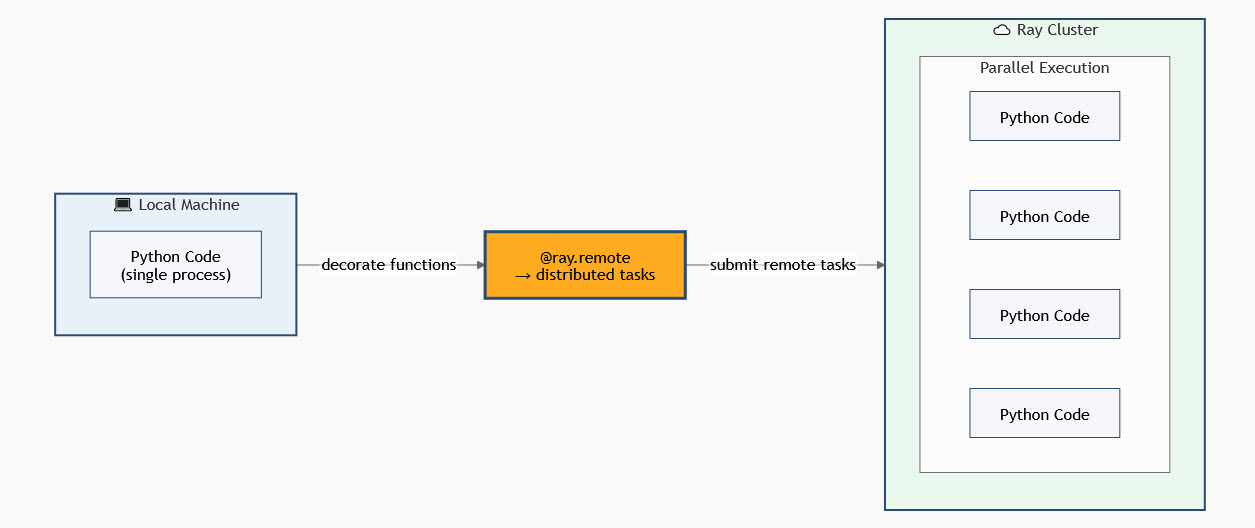
В этом примере базовая функция выполняется полностью асинхронно. Декоратор дает системе команду создать отдельную независимую задачу. Мы запускаем четыре вычисления практически в одно мгновение. В обычном синхронном Python это заняло бы четыре секунды. Благодаря фреймворку весь код выполняется всего за одну секунду. Это наглядно демонстрирует невероятную мощь параллельных вычислений.
Ray Framework против Apache Spark — Сравнение кода
Новички часто пытаются сравнивать эти две популярные платформы. Обе системы предназначены для параллельной обработки больших данных. Однако их внутренние подходы и архитектура сильно различаются. Давайте посмотрим на выполнение одинаковой логики в обоих фреймворках. Мы напишем функцию возведения каждого числа в квадрат.
Сначала рассмотрим классическую реализацию на базе Apache Spark.
from pyspark.sql import SparkSession
# Инициализация тяжелой сессии Spark
spark = SparkSession.builder.appName("Demo").getOrCreate()
# Исходный массив данных
data = [1, 2, 3, 4, 5]
# Создание RDD и применение трансформации
rdd = spark.sparkContext.parallelize(data)
result = rdd.map(lambda x: x * x).collect()
print(result)

Теперь напишем абсолютно аналогичную логику с использованием Ray.
import ray
# Инициализация легковесного кластера
ray.init()
# Создание удаленной задачи для вычислений
@ray.remote
def square(x):
return x * x
# Исходный массив данных
data = [1, 2, 3, 4, 5]
# Асинхронный запуск задач для каждого элемента
futures = [square.remote(x) for x in data]
result = ray.get(futures)
print(result)

Spark использует абстракцию под названием RDD для работы. Он отлично подходит для длинных цепочек трансформации таблиц. Однако Spark требует инициализации очень тяжелой виртуальной машины Java. Ray работает напрямую с простыми нативными функциями Python. Он передает объекты между процессами без сложных лишних прослоек. Таким образом, платформа стартует быстрее и потребляет меньше памяти. Кроме того, она позволяет распараллеливать любой произвольный скрипт. Spark же жестко ограничен набором своих встроенных SQL-операторов. Следовательно, для сложного машинного обучения Ray подходит гораздо лучше.
Подводные камни и ограничения
Несмотря на все очевидные плюсы, платформа имеет недостатки. К ним нужно быть полностью готовым перед началом внедрения. Любая распределенная система всегда добавляет определенный процент технической сложности.
Вот основные проблемы, с которыми сталкиваются инженеры на практике.
- Сложность отладки. Найти логическую ошибку в распределенном коде бывает крайне непросто. Стандартные инструменты дебаггера Python здесь часто оказываются бессильны.
- Накладные расходы. Передача информации между процессами всегда требует времени на сериализацию. Для слишком простых задач фреймворк может немного замедлить работу.
- Управление памятью. Хранилище объектов иногда переполняется при очень интенсивной вычислительной нагрузке. Разработчику необходимо внимательно следить за очисткой всех неиспользуемых переменных. Понимание этих технических ограничений поможет избежать критических сбоев. Всегда тщательно тестируйте производительность кода перед релизом в продакшен. Иначе вы рискуете получить систему, которая работает нестабильно.
Высокопроизводительная обработка данных на Python
Код курса
HPPY
Ближайшая дата курса
10 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Заключение
Ray Framework — это невероятно мощный инструмент для современного программиста. Он эффективно решает главную техническую боль экосистемы языка Python. Платформа обеспечивает интуитивно простое и быстрое масштабирование любых скриптов. Фреймворк позволяет инженерам полностью сфокусироваться на сложной бизнес-логике. Вам больше не нужно тратить часы на настройку инфраструктуры. Богатая встроенная экосистема библиотек закрывает все потребности специалистов Data Science. Она охватывает путь от сырых данных до готового API. Обязательно попробуйте внедрить этот замечательный инструмент в свои проекты.
Референсные ссылки:
- [Официальная документация платформы Ray] (https://docs.ray.io/)
- [Детальное руководство по развертыванию кластеров] (https://docs.ray.io/en/latest/cluster/getting-started.html)
- [Статья «Scaling Python with Ray» на платформе Medium] (https://towardsdatascience.com/)
- [Глубокий разбор «Ray Architecture» от компании Anyscale] (https://www.anyscale.com/blog/)