 307
307 
Содержание
RAFT — это алгоритм распределённого консенсуса, обеспечивающий согласованную репликацию журнала операций между узлами кластера и выбор лидера для координации изменений состояния системы.
Он решает фундаментальную проблему надежной синхронизации данных. Представьте группу полностью независимых серверов в сети. Они должны всегда работать как единый слаженный механизм. Если один сервер внезапно сломается, система обязана продолжить работу. Это критически важное свойство называется высокой отказоустойчивостью. Без надежного алгоритма консенсуса серверы начнут противоречить друг другу. Данные пользователей быстро станут неконсистентными и полностью бесполезными.
Таким образом, Raft строго гарантирует правильный порядок выполнения команд. Он тщательно следит за идентичностью данных на всех машинах. Разработчики изначально создали его для замены крайне сложного протокола Paxos. Главная цель этого алгоритма заключается в максимальной понятности. Его внутренняя логика легко разбивается на простые независимые блоки. Это сильно упрощает разработку программного обеспечения на практике. Сегодня алгоритм стал абсолютным стандартом де-факто в IT-индустрии.
Архитектура и роли узлов
Любой кластер Raft состоит из строго определенного количества серверов. Обычно администраторы выбирают нечетное число узлов для работы. Чаще всего в продакшене используют ровно три или пять серверов. Это необходимо для успешного формирования математического большинства голосов. Такое большинство в информатике принято называть кворумом. Узлы кластера непрерывно общаются между собой по локальной сети. В любой момент времени каждый узел имеет только одну конкретную роль. Смена этих ролей напрямую зависит от сетевых событий.
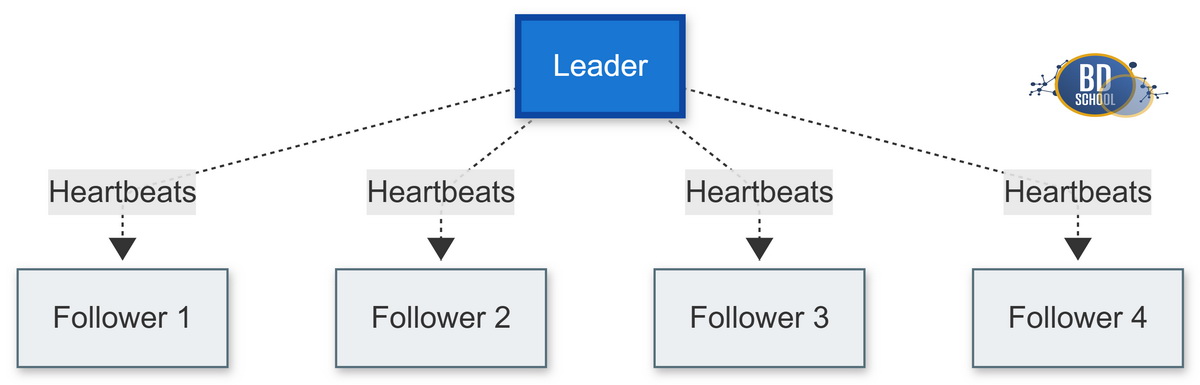
Рассмотрим основные роли серверов в кластере.
Лидер (Leader). Это самый главный сервер во всей системе.
- Лидер обрабатывает абсолютно все входящие запросы от клиентов.
- Он централизованно рассылает обновления данных остальным машинам.
- Лидер постоянно отправляет фоновые сигналы жизни (heartbeats).
Ведомый (Follower). Это базовая стартовая роль для всех новых серверов.
- Ведомые серверы никогда не инициируют новые запросы самостоятельно.
- Они полностью пассивны и только отвечают текущему лидеру.
- При долгом отсутствии лидера они автоматически меняют свою роль.
Кандидат (Candidate). Это временное переходное состояние любого сервера.
- Кандидат активно запрашивает голоса у других участников кластера.
- Он пытается быстро стать новым полноправным лидером системы.
- Успешное завершение голосования мгновенно меняет статус кандидата.
Подводя итог, можно уверенно сказать, что роли распределены предельно четко. В нормальном стабильном режиме всегда существует только один единственный лидер. Все остальные серверы кластера просто послушно следуют за его командами.
Эпохи и время (Terms)
Время в алгоритме Raft концептуально разделено на отдельные логические отрезки. Каждый такой временной отрезок официально называется термином или эпохой. Абсолютно любой термин всегда начинается с процесса выбора нового лидера. В рамках одного термина может существовать максимум один легитимный лидер.
Однако иногда выборы могут закончиться ничьей. В этом случае текущий термин завершается вообще без выбора лидера. Кластер просто увеличивает счетчик и начинает абсолютно новый термин. Номер термина постоянно увеличивается на единицу с каждой итерацией. Узлы постоянно используют эти номера для взаимной синхронизации состояния. Если сервер внезапно видит сообщение с большим номером термина, он обновляется. Старый лидер в такой ситуации немедленно теряет власть и становится ведомым. Таким образом, система эффективно защищается от устаревших команд из прошлого.
Принцип работы- Механизм Raft
Работа всего алгоритма концептуально делится на две базовые активные фазы. Первая фаза отвечает за общее управление кластером. Вторая фаза гарантирует надежное и безопасное сохранение пользовательских данных. Рассмотрим эти критически важные механизмы более подробно.
Выбор лидера (Leader Election)
Процесс выборов всегда запускается полностью автоматически без участия человека. Это происходит ровно тогда, когда кластер внезапно теряет своего лидера.
Алгоритм проведения выборов состоит из нескольких последовательных шагов.
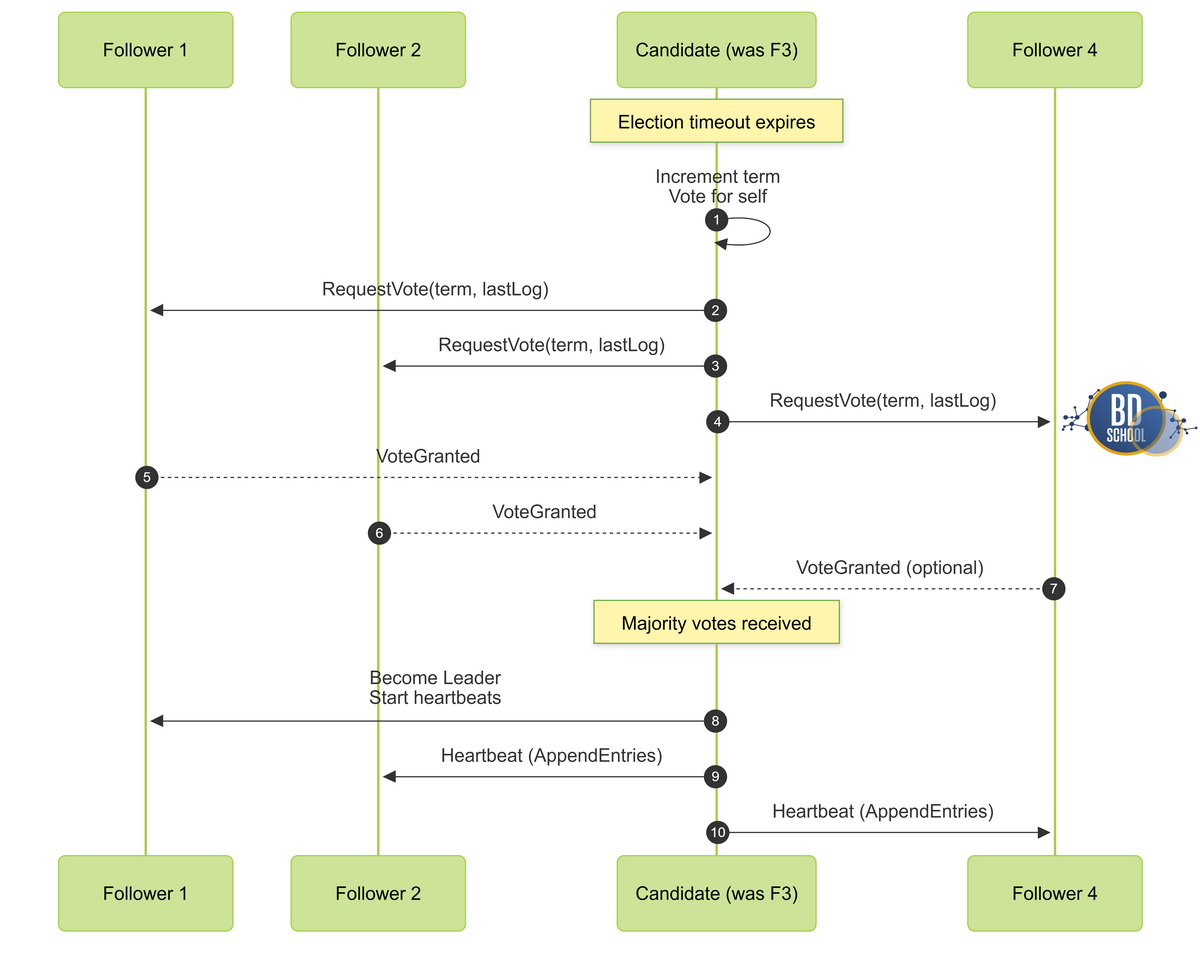
Таймаут ожидания. Каждый сервер имеет свой собственный таймер.
- Сервер использует случайный таймер ожидания ответа от лидера.
- Этот таймер официально называется election timeout.
- Значение таймера обычно составляет случайное число от 150 до 300 миллисекунд.
Начало выборов. Ведомый узел ждет дежурный сигнал от лидера.
- Если сигнала нет, ведомый объявляет себя кандидатом.
- Кандидат немедленно голосует сам за себя на выборах.
- Затем он рассылает запросы голосов всем остальным участникам.
Завершение выборов. Узлы отдают свой голос первому запросившему кандидату.
- Получив большинство голосов кластера, кандидат становится новым лидером.
- Новый лидер сразу начинает активную рассылку своих сигналов жизни.
- Это блокирует попытки других узлов начать новые параллельные выборы.
Этот элегантный процесс гарантирует непрерывность работы всей системы в целом. Случайные таймеры эффективно предотвращают коллизии и одновременный старт нескольких выборов.
Репликация логов (Log Replication)
Это основной процесс безопасной синхронизации всех пользовательских данных. Он гарантирует полную согласованность состояния на всех физических машинах.
Процесс репликации работает по принципу двухфазного коммита.
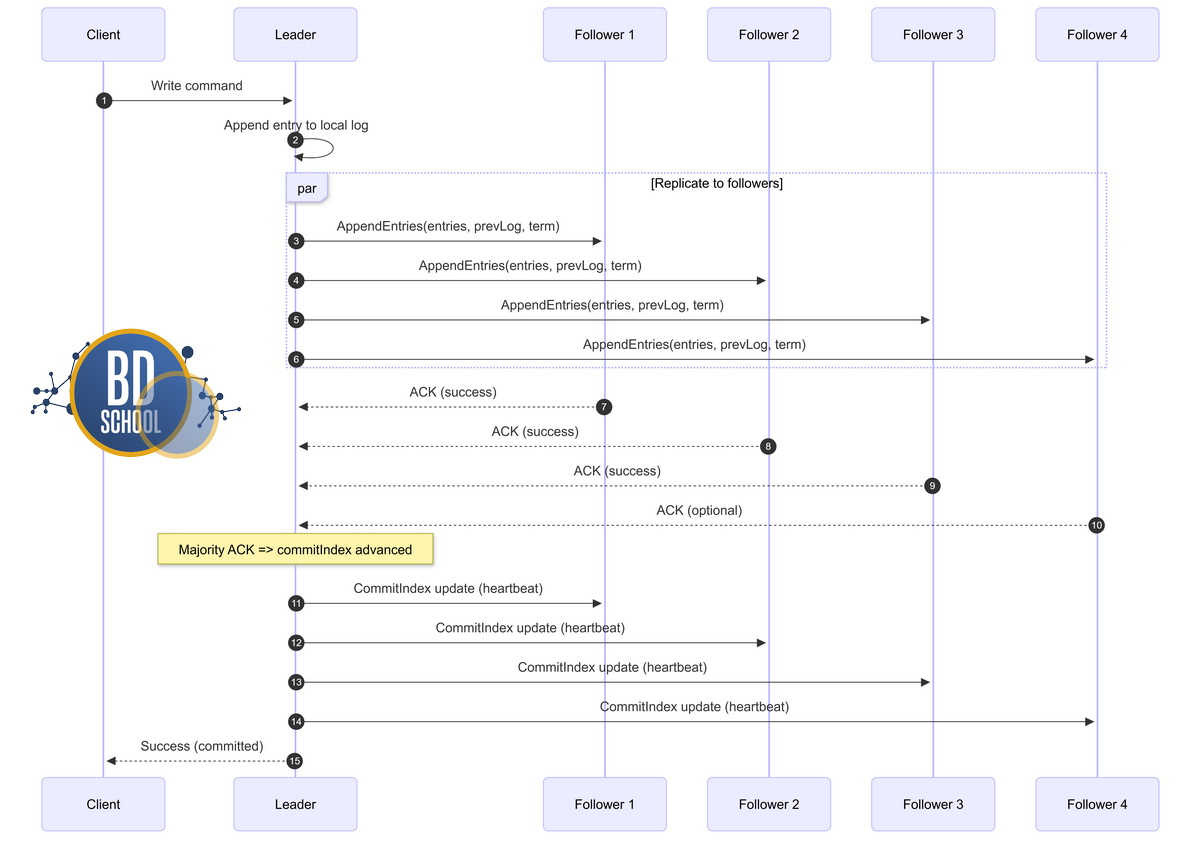
Запись данных. Клиент отправляет новую команду текущему лидеру кластера.
- Лидер аккуратно записывает полученную команду в свой локальный лог.
- Эта новая запись пока считается неподтвержденной и небезопасной.
- Лидер параллельно рассылает эту запись всем доступным ведомым узлам.
Подтверждение. Ведомые узлы получают новую запись от лидера.
- Они успешно сохраняют полученную запись в свои локальные логи.
- Затем они отправляют лидеру сообщение об успешном сохранении данных.
- Лидер терпеливо ждет ответа от строгого большинства серверов кластера.
Фиксация изменений. Получив кворум, лидер окончательно принимает решение.
- Лидер официально применяет изменения к своей конечной машине состояний.
- Этот критический процесс в документации называется фиксацией (commit).
- Затем лидер сообщает конечному клиенту об успешном выполнении операции.
- В конце лидер дает команду всем ведомым применить сохраненные изменения.
Кроме того, алгоритм обеспечивает строгую хронологическую последовательность всех записей. Каждая отдельная запись в логе имеет свой уникальный порядковый индекс. Следовательно, внутренние базы данных узлов всегда остаются полностью идентичными.
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
18 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Управление памятью — Сжатие логов
Со временем операционный лог любого сервера непрерывно и неизбежно растет. Он бережно сохраняет абсолютно все исторические изменения системы. Однако бесконечный рост лога со временем создает очень серьезные технические проблемы. Во-первых, на сервере может банально закончиться свободное место на диске. Во-вторых, перезапуск сервера начинает занимать слишком много драгоценного времени. Серверу нужно последовательно прочитать весь огромный исторический лог. Для изящного решения этой проблемы применяется механизм сжатия логов.
Этот процесс основан на регулярном создании компактных снимков.
Создание снимка (Snapshot). Процесс запускается при достижении лимита памяти.
- Сервер собирает текущее конечное состояние своей базы данных.
- Он быстро записывает его в отдельный компактный бинарный файл.
- В этот снимок обязательно включаются метаданные последнего сохраненного изменения.
- Метаданные содержат номер текущего термина и индекс последней записи.
Очистка памяти. После сохранения снимка алгоритм удаляет старый мусор.
- Сервер физически удаляет все записи в логе до индекса снимка.
- Это действие мгновенно освобождает огромное количество дискового пространства.
- Теперь сервер может невероятно быстро загрузиться после любой аварии.
Иногда ведомый узел слишком сильно отстает от текущего лидера. Лидер к этому моменту уже удалил старые логи из своей оперативной памяти. В таком случае лидер отправляет ведомому свой свежий снимок целиком. Специальная сетевая команда позволяет безопасно передать большой файл по сети. Таким образом, система всегда поддерживает оптимальный размер хранимых данных.
Сценарии использования
В чистом виде алгоритм нигде не используется как отдельный коммерческий продукт. Он является прочным логическим фундаментом для множества других современных систем. Инженеры глубоко встраивают его в ядра своих распределенных приложений. Это позволяет быстро создавать надежные и отказоустойчивые архитектуры.
Рассмотрим самые популярные варианты практического применения.
Системы Service Discovery. Они хранят критически важную информацию о микросервисах.
- Популярный инструмент Consul использует этот алгоритм для хранения конфигураций.
- Известное хранилище ключей etcd также полностью построено на его основе.
- Знаменитый Kubernetes хранит абсолютно все свои данные именно в etcd.
Распределенные базы данных. Они требуют строгой консистентности пользовательских данных.
- База данных CockroachDB применяет его для надежной репликации таблиц.
- Проект TiDB использует эту логику для эффективного управления партициями.
- СУБД YugabyteDB также строит свой нижний слой хранения на этом протоколе.
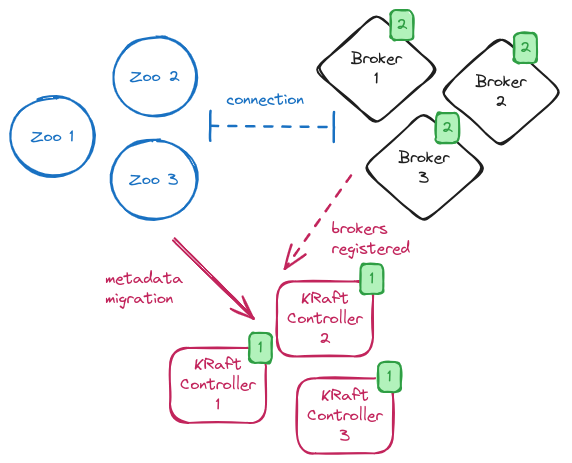
Системы брокеров сообщений. Сообщения от пользователей не должны теряться при сбоях.
- Apache Kafka успешно переходит на новый протокол KRaft вместо Zookeeper.
- Популярный брокер RabbitMQ предлагает пользователям очереди на основе кворума.
Подводя итог, можно смело отметить невероятную универсальность данного подхода. Любая серьезная система со строгими требованиями к консистентности может его использовать. Сегодня Raft заслуженно стал настоящим золотым стандартом IT-индустрии.
Взаимодействие — Код
Понимание алгоритма всегда проще всего закрепить чтением реального кода. Давайте детально посмотрим на внутреннюю логику работы типичного узла. Ниже представлен максимально базовый пример на популярном языке Python. Он описывает стандартный жизненный цикл работы очень простого ведомого узла. Мы специально не будем сейчас писать сложный асинхронный сетевой код. Мы сосредоточимся исключительно на логике работы внутренних случайных таймеров.
Данный скрипт отлично имитирует процесс томительного ожидания лидера.
import time
import random
class RaftNode:
def __init__(self, node_id):
self.node_id = node_id
# Все узлы стартуют как ведомые
self.state = "FOLLOWER"
self.current_term = 0
# Случайный таймер от 150 до 300 мс предотвращает коллизии
self.election_timeout = random.uniform(0.15, 0.3)
self.last_heartbeat = time.time()
def receive_heartbeat(self, term):
# Если термин лидера актуален, сбрасываем таймер
if term >= self.current_term:
self.current_term = term
self.state = "FOLLOWER"
self.last_heartbeat = time.time()
print(f"Узел {self.node_id}: Получен сигнал. Лидер жив.")
def check_timeout(self):
# Проверяем, сколько времени прошло с последнего сигнала
elapsed_time = time.time() - self.last_heartbeat
# Если лидер молчит дольше таймаута, начинаем революцию
if elapsed_time > self.election_timeout:
self.start_election()
def start_election(self):
self.state = "CANDIDATE"
self.current_term += 1
self.last_heartbeat = time.time()
print(f"Узел {self.node_id}: Таймаут! Начинаю выборы для эпохи {self.current_term}.")
# Здесь обычно отправляются сетевые запросы голосов RequestVote
Этот простой код наглядно демонстрирует самый базовый принцип работы для одноузлового кластера. Узел в бесконечном цикле проверяет время с момента последнего сигнала. Если действующий лидер долго молчит, узел смело берет инициативу. Случайный размер таймера эффективно предотвращает одновременный старт выборов всеми узлами. Таким образом, опасные сетевые коллизии происходят крайне редко.
Практическое применение Big Data аналитики для решения бизнес-задач
Код курса
PRUS
Ближайшая дата курса
20 апреля, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Raft против Paxos
Исторически самым первым академическим алгоритмом консенсуса был знаменитый Paxos. Его блестяще разработал ученый Лесли Лампорт в далеком 1989 году. Долгое время Paxos считался абсолютно единственным правильным решением проблемы. Однако он всегда имел один невероятно серьезный практический недостаток. Этот алгоритм был просто фантастически сложным для понимания обычными людьми.
Это постоянно вызывало огромные проблемы при реальной реализации алгоритма. Инженерам было крайне трудно писать надежный код на его основе. Каждая крупная компания создавала свою собственную уникальную версию протокола Paxos. Эти самописные версии неизбежно содержали критические баги и архитектурные ошибки. Разработчики Raft поставили перед собой совершенно новую и амбициозную цель. Они хотели создать максимально прозрачный и понятный для людей алгоритм.
Им это полностью удалось благодаря двум важным архитектурным решениям.
Разделение логики. Алгоритм четко разделен на независимые логические блоки.
- Процесс выбора лидера работает полностью автономно от остальных систем.
- Механизм репликации логов идет своим собственным отдельным процессом.
- Это существенно облегчает изучение, тестирование и отладку конечного кода.
Авторитарное лидерство. В протоколе Paxos любой узел мог предлагать изменения.
- В новом алгоритме все входящие запросы направляются исключительно через лидера.
- Ведомые узлы никогда не пытаются изменять данные по своей инициативе.
- Такой строгий подход значительно упрощает управление возможными конфликтами данных.
В результате практически вся индустрия массово перешла на новый стандарт. Разрабатывать распределенные системы стало гораздо проще и значительно дешевле. Кроме того, студентам университетов стало намного легче изучать распределенные вычисления.
Обработка сбоев — Сетевые разделения
Одной из самых главных и страшных проблем распределенных систем является Split-Brain. Это неприятная ситуация полного физического сетевого разделения кластера. Представьте, что центральный коммутатор в вашем дата-центре внезапно сгорел. Ваш рабочий кластер из пяти серверов физически разделился пополам. Два сервера остались в одной изолированной подсети. Три других сервера оказались в совершенно другой изолированной подсети.
Сетевой связи между этими двумя группами машин больше не существует. Возникает огромный риск появления двух независимых лидеров в одной системе. Это гарантированно может привести к необратимому логическому повреждению пользовательских данных. Однако Raft решает эту классическую проблему невероятно элегантно и просто. Основной механизм защиты полностью основан на правиле математического кворума.
Посмотрим на поведение обеих изолированных групп.
Поведение меньшинства. Изолированная группа из двух серверов быстро потеряет лидера.
- Они неминуемо начнут процесс абсолютно новых внутренних выборов.
- Ни один кандидат в этой группе не получит большинства голосов.
- Большинство для исходного кластера из пяти — это минимум три узла.
- Следовательно, эта группа физически не сможет выбрать себе нового лидера.
- Они полностью прекратят принимать любые новые записи от клиентов.
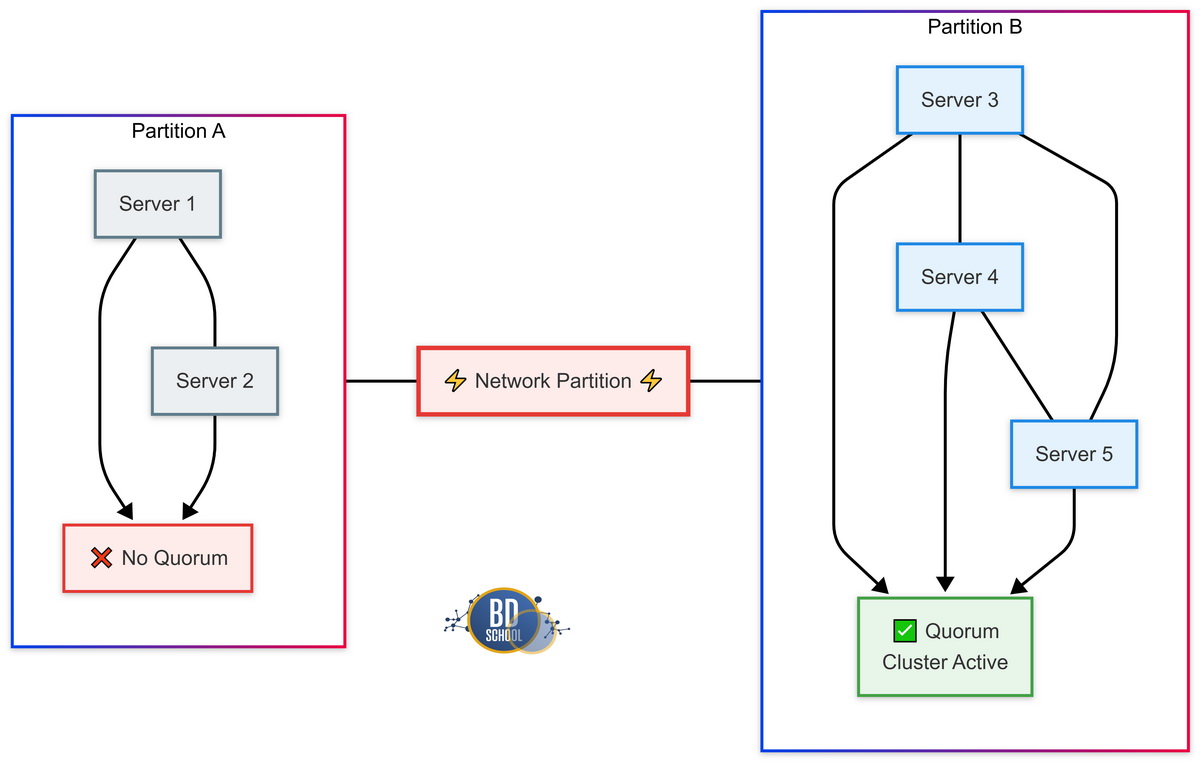
Поведение большинства. Группа из трех серверов успешно продолжит свою работу.
- Если старый лидер остался с ними, они просто работают дальше.
- Если лидер оказался в меньшинстве, они успешно выберут нового лидера.
- Три узла легко могут сформировать необходимый легитимный кворум.
- Они будут продолжать успешно принимать и сохранять новые пользовательские данные.
Когда сеть наконец восстановится, кластер мгновенно объединится обратно. Узлы из бывшего меньшинства сразу увидят нового легитимного лидера. Они обязательно заметят совершенно новую, более высокую эпоху работы. Старый лидер из меньшинства мгновенно станет обычным послушным ведомым. Затем эти отставшие узлы просто скачают новые логи у текущего лидера. Таким образом, система полностью автоматически исправит свое логическое отставание. Ручное вмешательство системного администратора для этого абсолютно не потребуется.
Практическая архитектура данных
Код курса
PRAR
Ближайшая дата курса
20 апреля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Заключение
Надежный распределенный консенсус больше никогда не является непостижимой магией. Современный протокол Raft убедительно доказал это на своей многолетней практике. Он предоставил простым инженерам невероятно надежный и предельно прозрачный инструмент. Автоматический выбор лидера надежно гарантирует строгий порядок в любом кластере. Постоянная репликация логов обеспечивает стопроцентную сохранность важных пользовательских данных. А строгий механизм кворума элегантно защищает систему от сетевых разделений.
Сегодня этот мощный алгоритм незаметно работает под капотом крупнейших мировых систем. Глубокое понимание его работы строго обязательно для всех современных backend-разработчиков. Это ваш главный ключ к созданию по-настоящему отказоустойчивых высоконагруженных сервисов. Если вы хотите углубиться в эту тему, обязательно изучите оригинальную статью. Кроме того, вы можете легко запустить локальный кластер etcd на компьютере. Это будет отличная практическая тренировка для закрепления всего прочитанного материала.
Хотите, я подробно расскажу вам, как развернуть свой первый локальный кластер etcd в Docker для экспериментов?
Референсные ссылки
- [In Search of an Understandable Consensus Algorithm] (https://raft.github.io/raft.pdf)
- [Raft Consensus Algorithm — Interactive Visualization] (https://thesecretlivesofdata.com/raft/)
- [Etcd Documentation — Distributed Consensus] (https://etcd.io/docs/v3.5/learning/why/)
- [Consul Architecture — HashiCorp] (https://developer.hashicorp.com/consul/docs/architecture/consensus)