 311
311 
Содержание
- Архитектура и структуры данных Pandas
- Принцип работы и механизм
- Сценарии использования
- Взаимодействие и код в Pandas Python
- Чтение и первичный осмотр данных в Pandas
- Фильтрация и "умная" индексация
- Очистка данных (Cleaning)
- Группировка и агрегация dataframes
- Объединение таблиц (Merging)
- Оптимизация производительности Pandas
- Pandas и экосистема Big Data
- Заключение
- Референсные ссылки
Pandas — это высокопроизводительная библиотека с открытым исходным кодом для обработки и анализа данных на языке Python. Она предоставляет удобные структуры данных для работы с таблицами и временными рядами. Инструмент де-факто является стандартом в индустрии Data Science и машинного обучения.
Библиотека построена поверх NumPy. Это обеспечивает ей высокую скорость вычислений. Однако Pandas ( Далее PD) добавляет гибкость, позволяя работать с разнородными типами данных и пропущенными значениями.
Архитектура и структуры данных Pandas
В основе библиотеки PD лежат три фундаментальных объекта. Понимание их взаимодействия необходимо для эффективной работы с библиотекой. Эти структуры организуют данные в логическую иерархию.
- Series. Это одномерный маркированный массив. Он может хранить любой тип данных (целые числа, строки, числа с плавающей точкой). Представьте его как одну колонку в таблице Excel.
- Pandas DataFrame. Это двумерная маркированная структура данных. Она похожа на таблицу SQL или электронную таблицу. Pandas DataFrame состоит из упорядоченной коллекции объектов Series.
- Index. Это объект, хранящий метки осей (строк и колонок). Индекс обеспечивает быстрый доступ к данным, их выравнивание и эффективную нарезку (slicing).
Таким образом, DataFrame в Pandas — это контейнер для Series, а Index связывает их в единую координатную систему.
Принцип работы и механизм
Главная сила библиотеки PD заключается в векторизации. Библиотека делегирует математические операции низкоуровневым алгоритмам на языке C и кроме этого под капотом библиотека использует NumPy. Это позволяет избегать медленных итераций Python. Механизм работы строится на следующих принципах:
- Векторизированные операции. В стандартном Python, чтобы сложить два списка чисел, вам нужно запустить цикл for и складывать числа по одному. В Pandas операция Series_A + Series_B передает команду на уровень процессора, который выполняет сложение над всем массивом данных одновременно (SIMD-инструкции).
- Выравнивание данных (Alignment). Pandas автоматически сопоставляет данные по индексам при выполнении операций. Если индексы не совпадают, библиотека вставляет значение NaN (Not a Number).
- Broadcasting (Транслирование). Этот механизм позволяет проводить арифметические операции между массивами разных форм. Например, можно умножить весь DataFrame на одно число.
- Копирование против Представления (View vs Copy). Это важный нюанс. Некоторые операции создают новую копию данных (занимают память), а некоторые — создают лишь «ссылку» (view) на старые данные. Понимание этого механизма спасает от знаменитой ошибки SettingWithCopyWarning.
Благодаря этому код становится лаконичным и быстрым, а риск ошибок при ручном переборе индексов исчезает и PD позволяет обрабатывать миллионы строк за секунды на обычном ноутбуке.
Сценарии использования
Pandas закрывает большинство задач на этапе подготовки данных. Он редко используется для обучения моделей, но незаменим до этого момента.
Специалисты применяют библиотеку в трех основных направлениях:
- Data Wrangling (подготовка данных). Сырые данные никогда не бывают чистыми. В них встречаются опечатки, разные форматы дат (DD-MM-YYYY vs MM/DD/YYYY) и странные разделители. Pandas предоставляет инструментарий для приведения этого хаоса к единому стандарту.
- Разведочный анализ (EDA). Перед построением сложных моделей аналитику нужно «пощупать» данные. Pandas позволяет в одну строчку кода получить гистограмму распределения, найти выбросы (аномально большие или маленькие значения) и проверить гипотезы о корреляции признаков.
- Подготовка временных рядов. Финансовые аналитики любят PD за мощный функционал работы с датами. Библиотека умеет делать ресемплинг (превращать минутные данные в часовые), сдвигать временные окна (lag features) и заполнять пропуски в датах.
- ETL-процессы. Инженеры данных используют Pandas для извлечения (Extract), очистки (Transform) и загрузки (Load) информации. Сюда входит удаление дубликатов, заполнение пропусков и смена форматов.
- Подготовка фичей (Feature Engineering). Дата-саентисты создают новые признаки для ML-моделей. Например, они могут разбить дату на день недели и месяц или нормализовать числовые значения.
Эти сценарии делают библиотку PD универсальным инструментом в руках специалиста по большим данным или data scientistа. Без этого этапа невозможно построить качественную модель машинного обучения: принцип «мусор на входе — мусор на выходе» работает безотказно.
Взаимодействие и код в Pandas Python
Синтаксис библиотеки интуитивно понятен. Рассмотрим базовые операции, которые составляют 80% ежедневной работы аналитика.
Для выполнения сквозных тестовых задач сгенерируем датасет 2000 строк и сделаем его более реалистичным добавив немного , «генератора случайностей», чтобы данные выглядели как настоящие логи магазина: разные даты в течение года, разброс цен и, конечно, пропуски (NaN), с которыми нужно будет бороться, чтобы ты мог ощутить возможности библиотеки PD на большом массиве данных.
Скачай и запусти этот код dataset_gen.ipynb с нашего GitHub репозитория где мы выкладываем код для наших статей. Он создаст файлы orders.csv и clients.csv в той же папке.
Ниже приведены примеры типовых задач с использование данного датасета для демонстрации применения возможностей библиотеки PD для работы с dataframes и фильтрации, группировки и аггрегации данных.
Чтение и первичный осмотр данных в Pandas
Pandas умеет читать практически любые форматы: CSV, Excel, JSON, Parquet и даже SQL-запросы.
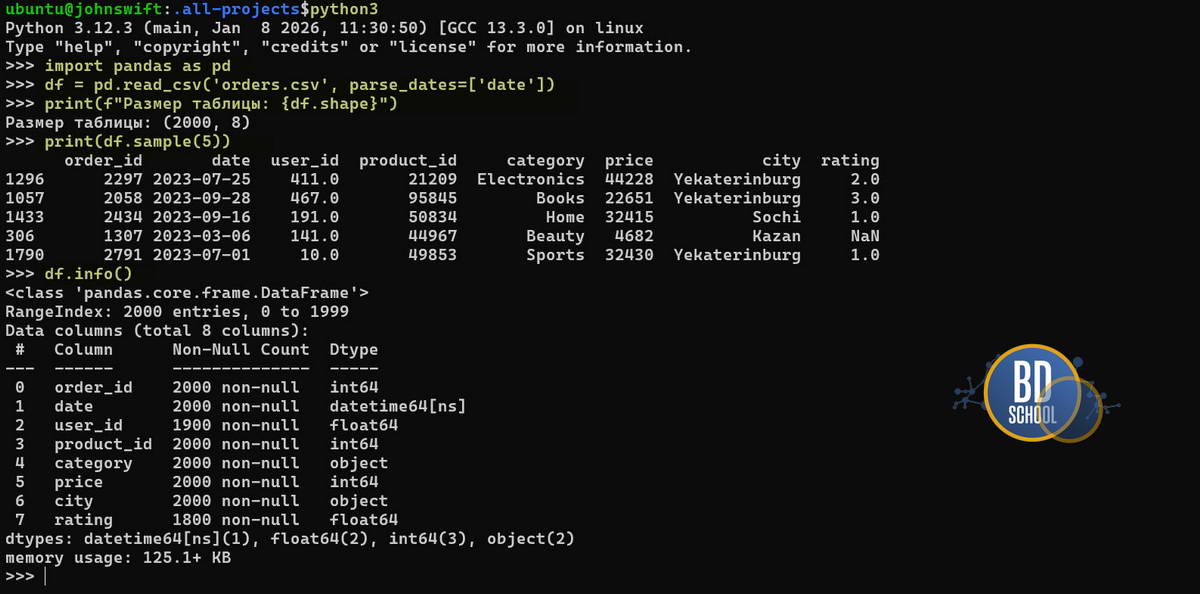
import pandas as pd
# Загружаем данные, указывая, что колонка 'date' содержит даты
df = pd.read_csv('orders.csv', parse_dates=['date'])
# Смотрим размерность таблицы (строки, колонки)
print(f"Размер таблицы: {df.shape}")
# Выводим случайные 5 строк, а не первые, чтобы увидеть разнообразие данных
print(df.sample(5))
# Проверяем типы данных и наличие пустых значений
df.info()
Разбор кода:
- parse_dates=[‘date’]: Этот параметр сразу превращает текстовые строки «2023-01-01» в полноценные объекты datetime. Если это не сделать сразу, даты останутся строками, и вы не сможете извлечь из них месяц или день недели.
- df.shape: Возвращает кортеж (например, (1000, 5)), позволяя мгновенно оценить масштаб данных.
- df.sample(5): Часто начало и конец файла выглядят аккуратно, а ошибки прячутся в середине. Метод sample берет случайную выборку, давая более честную картину.
ML Практикум: от теории к промышленному использованию
Код курса
PYML
Ближайшая дата курса
30 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
Фильтрация и «умная» индексация
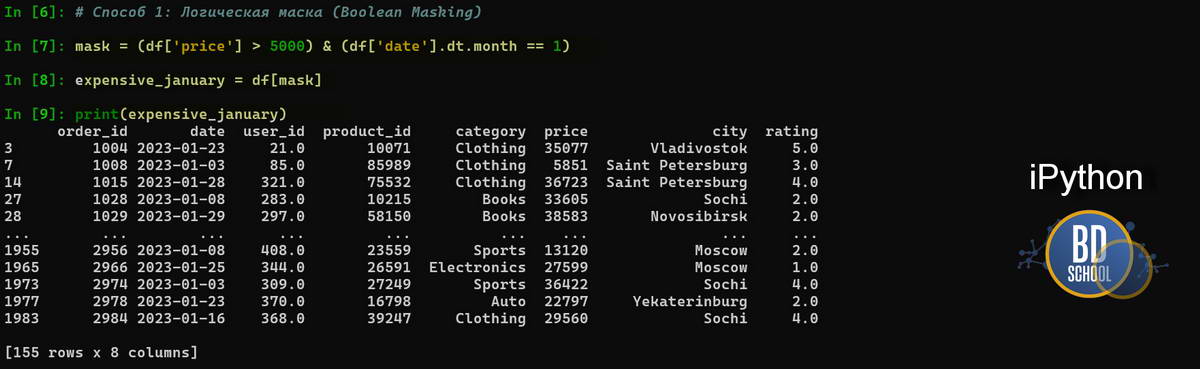
Одна из самых частых задач — выбрать данные по условию. Новички часто путаются между методами .loc и .iloc. Используйте методы .loc (по меткам) и .iloc (по позициям) для точного доступа к данным. Наша задача найти все заказы дороже 5000 рублей за январь
# Способ 1: Логическая маска (Boolean Masking) mask = (df['price'] > 5000) & (df['date'].dt.month == 1) expensive_january = df[mask]
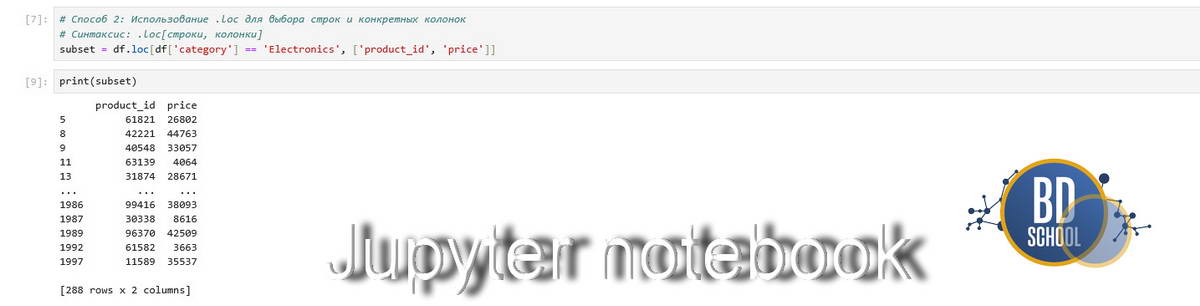
# Способ 2: Использование .loc для выбора строк и конкретных колонок # Синтаксис: .loc[строки, колонки] subset = df.loc[df['category'] == 'Electronics', ['product_id', 'price']]
Разбор кода:
- mask: Это вспомогательный объект Series, состоящий только из True и False. Когда мы передаем его в df[…], Pandas оставляет только те строки, где стоит True.
- &: В Pandas для условий «И» используется амперсанд &, а не слово and. Это важно!
- .loc: Этот оператор работает по меткам (названиям). Мы говорим: «Дай мне строки, где категория Электроника, и верни только колонки ID и Цену». Это экономит память, так как мы не тянем лишние столбцы.
Очистка данных (Cleaning)
Данные редко приходят идеальными. Пропуски (NaN) могут сломать вычисления.
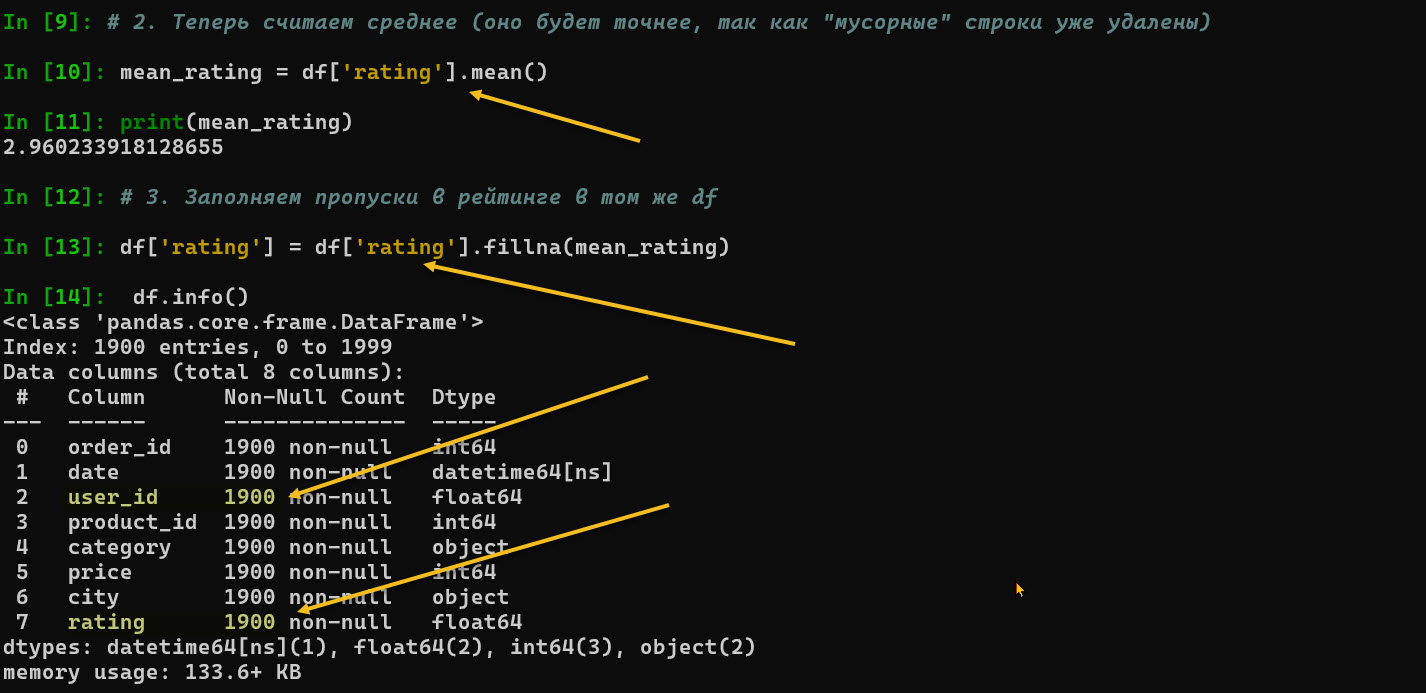
# 1. Сначала удаляем строки с пустым user_id и ПЕРЕЗАПИСЫВАЕМ df
df = df.dropna(subset=['user_id'])
# 2. Теперь считаем среднее (оно будет точнее, так как "мусорные" строки уже удалены)
mean_rating = df['rating'].mean()
# 3. Заполняем пропуски в рейтинге в том же df
df['rating'] = df['rating'].fillna(mean_rating)
# 4. Проверяем результат
print("--- ПРОВЕРКА ---")
print(df.isna().sum())
print(f"\nРазмер таблицы: {df.shape}")
В ходе выполнения очистки проверяем результаты ( см. скриншот)
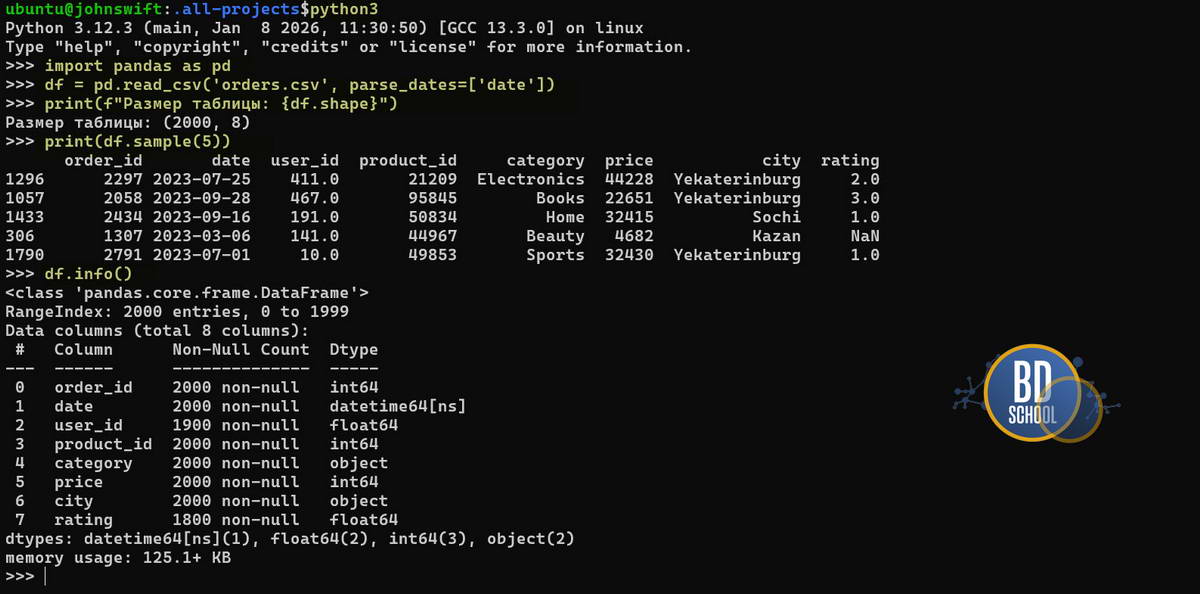 и замена rating NA на среднее но по уже усеченной таблице 1900 строк user_id
и замена rating NA на среднее но по уже усеченной таблице 1900 строк user_id
Или проверим dataframe c помощью .isna().sum() — который покажет нуль если нет пропущенных значений в колонке
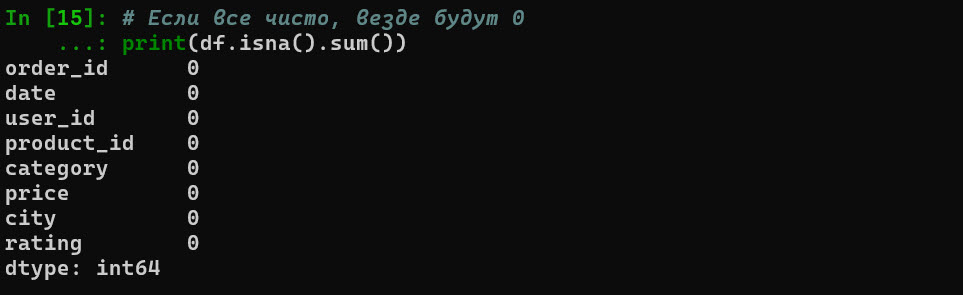
Разбор кода:
- .isna().sum(): Первая часть создает таблицу из True/False (где пропуск), а .sum() считает True как единицы. Это лучший способ быстро найти «дыры» в данных.
- subset=[‘user_id’]: Мы удаляем не все строки с пропусками, а только те, где отсутствует критически важный ID пользователя. Если у заказа нет рейтинга, его можно оставить, но заказ без пользователя — мусор.
- .fillna(): Этот метод позволяет безопасно заменить NaN. Замена на среднее (mean) или медиану — стандартная практика, чтобы сохранить объем выборки для обучения моделей.
Группировка и агрегация dataframes
Метод groupby работает по парадигме «Split-Apply-Combine» (Разделить-Применить-Объединить). Это аналог сводных таблиц в Excel или GROUP BY в SQL. Самый мощный инструмент для получения инсайтов.
# Задача: Узнать средний чек и количество заказов по каждому городу
city_stats = df.groupby('city').agg({
'price': ['sum', 'mean'], # Сумма и среднее по цене
'order_id': 'count' # Количество заказов
})
# Переименование колонок для красоты (опционально)
city_stats.columns = ['total_revenue', 'avg_check', 'orders_count']
print(city_stats)
Разбор кода:
- groupby(‘city’): Эта команда виртуально разрезает таблицу на множество маленьких таблиц — по одной для каждого города.
- .agg({…}): Метод агрегации позволяет применить разные функции к разным колонкам за один проход. Мы одновременно считаем выручку (sum) и количество заказов (count). Это намного эффективнее, чем делать это по очереди.
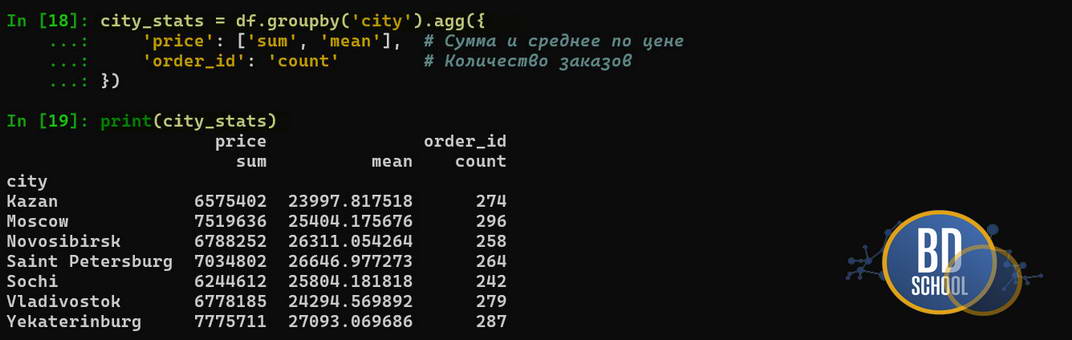
Этот код заменяет десятки строк на чистом Python и выполняется значительно быстрее.
Объединение таблиц (Merging)
Часто данные лежат в разных файлах: заказы в одном, а информация о клиентах — в другом.
# Загружаем справочник клиентов
clients = pd.read_csv('clients.csv')
# Объединяем заказы с клиентами по ключу user_id
# how='left' означает: оставить все заказы, даже если данных о клиенте нет
full_data = df.merge(clients, on='user_id', how='left')
Теперь мы имее один датафрейм
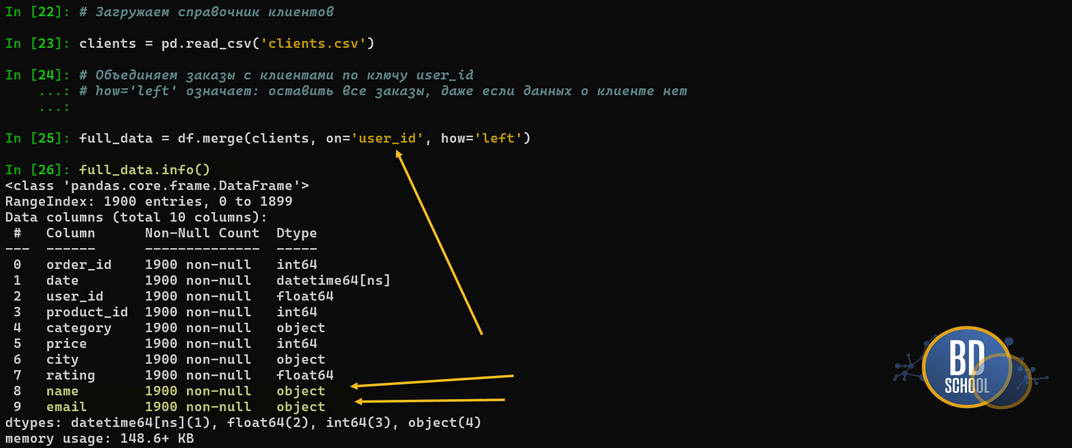
Разбор кода:
- .merge(): Это полный аналог SQL JOIN.
- how=’left’: Самый безопасный тип объединения для аналитики продаж. Он гарантирует, что мы не потеряем ни одного заказа, даже если в базе клиентов произошел сбой и запись о покупателе отсутствует. Если бы мы использовали inner, такие «проблемные» заказы просто исчезли бы из отчета.
Оптимизация производительности Pandas
PD работает в оперативной памяти (In-Memory). Это накладывает ограничения при работе с большими наборами данных. Неэффективный код может «убить» ядро Jupyter Notebook.
Для ускорения работы и экономии памяти следуйте этим правилам:
- Избегайте циклов for. Итерация по строкам DataFrame — это самое медленное действие. Всегда ищите векторизированную альтернативу или встроенный метод.
- Используйте .apply() с осторожностью. Метод .apply() удобен, но он часто работает как скрытый цикл. Векторные операции NumPy всегда будут быстрее.
- Оптимизируйте типы данных (Downcasting). По умолчанию Pandas использует int64 и float64. Часто данные влезают в int8 или float32. Принудительное изменение типа может сократить потребление памяти в разы.
Грамотное управление типами данных позволяет обрабатывать на ноутбуке файлы размером в несколько гигабайт. Предлагаем Вам посмотреть видео про основы работы с библиотекой Pandas которое является частью бесплатного видео курса записанного преподавателями «Школы больших данных» и доступного на сайте нашего проекта «Школы Питон».
Pandas и экосистема Big Data
PD не является инструментом для «настоящих» больших данных (Big Data), которые не помещаются в RAM. Однако он тесно интегрирован в эту экосистему.
Взаимодействие происходит на следующих уровнях:
- Форматы хранения. Библиотека отлично работает с колоночными форматами вроде Parquet или ORC. Они используются в экосистеме Hadoop и Spark для сжатия данных.
- Интеграция со Spark. PySpark позволяет конвертировать свои датафреймы в PD и обратно. Это полезно для локальной отладки на небольшом куске данных.
- Масштабирование. Когда данных становится слишком много, код PD можно перенести на Dask или Modin. Эти библиотеки используют синтаксис Pandas, но распределяют вычисления по ядрам процессора или кластеру.
Таким образом, Pandas остается «точкой входа» даже при работе с терабайтами информации.
Анализ данных с помощью современного Apache Spark
Код курса
SPARK
Ближайшая дата курса
6 апреля, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Заключение
Pandas — это фундамент стека технологий Python для Data Science. Он объединяет простоту использования с мощью научных вычислений. Освоение этой библиотеки является обязательным первым шагом для любого специалиста, желающего работать с данными профессионально.
Референсные ссылки