Data Lineage (линейность данных) — это процесс отслеживания, визуализации и понимания пути данных от их источника до конечного потребителя. Он включает в себя все точки остановки и трансформации на этом пути, отвечая на ключевые вопросы: откуда пришли данные, что с ними произошло и куда они направляются. Если представить все данные...
Data Mining - процесс поиска в сырых необработанных данных интересных, неизвестных, нетривиальных взаимосвязей и полезных знаний, позволяющих интерпретировать и применять результаты для принятия решений в любых сферах человеческой деятельности. Представляет собой совокупность методов визуализации, классификации, моделирования и прогнозирования, основанные на применении деревьев решений, искусственных нейронных сетей, генетических алгоритмов, эволюционного программирования, ассоциативной памяти, нечёткой логики. Дополнительно о...

Data Provenance (происхождение данных) — это документированная история данных с момента их создания до текущего состояния. Она включает в себя все метаданные, описывающие источники, процессы, преобразования и перемещения, которые данные претерпели. Представьте себе родословную ценного произведения искусства: она подтверждает его подлинность, описывает всех владельцев и реставрации. Точно так же Data...
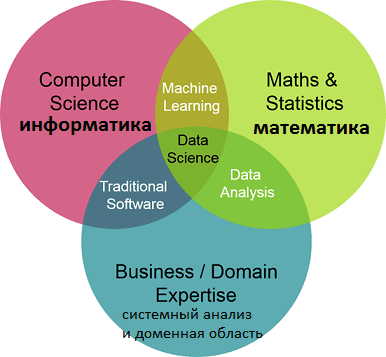
Data Science – это наука о данных, объединяющая разные области знаний: информатику, математику и системный анализ. Сюда входят методы обработки больших данных (Big Data), интеллектуального анализа данных (Data Mining), статистические методы, методы искусственного интеллекта, в т.ч машинное обучение (Machine Learning). DS включает методы проектирования и разработки баз данных и прикладного...

Data Vault (DV) — это современная методология моделирования, архитектура и набор практик для создания корпоративных хранилищ данных (DWH). Важно понимать: DV — это не программный продукт, который можно "купить" или "установить". Это подход, стандарт проектирования. Его главная цель — решить две основные проблемы традиционных DWH: нехватку гибкости при изменениях...
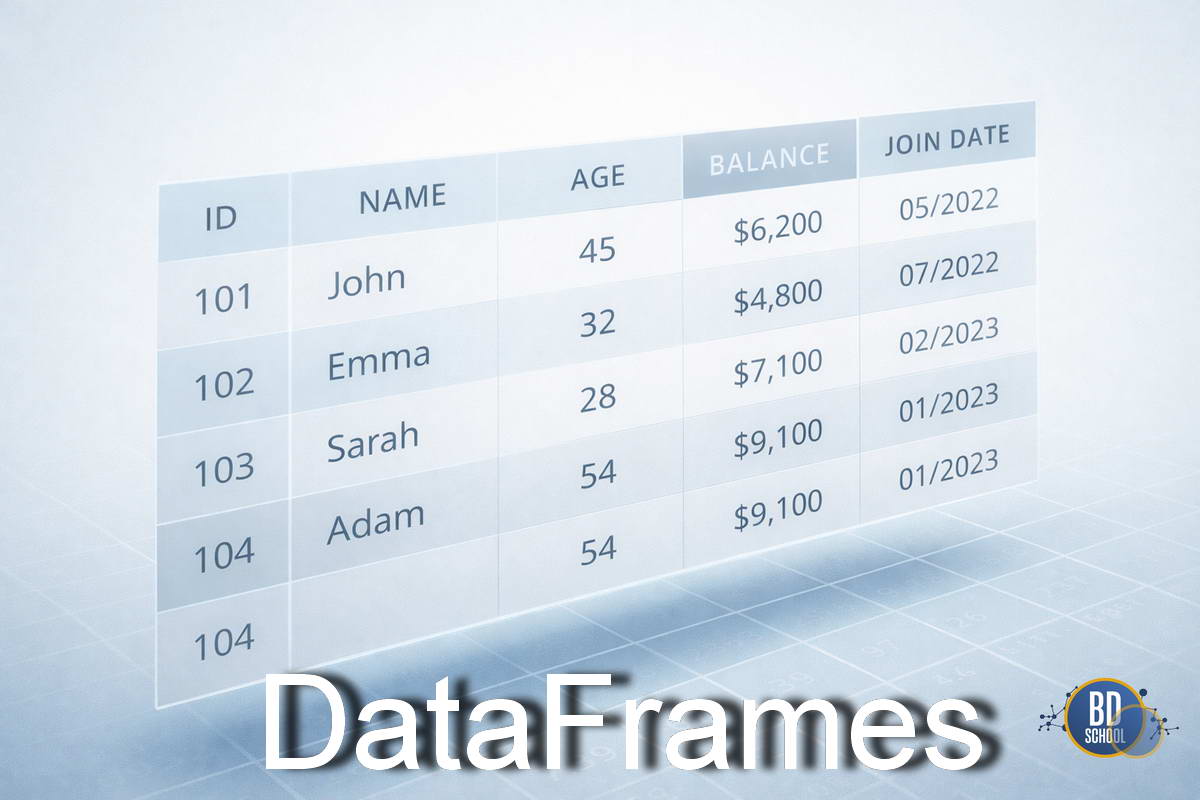
DataFrame — это табличная структура данных с именованными столбцами и индексами строк, предназначенная для удобного хранения, преобразования и анализа структурированных данных в аналитических и научных вычислениях. Представьте себе лист Excel, но с возможностью программного управления и обработки миллионов строк за секунды. Это основной объект для манипуляции данными в языке...

DataOps - это междисциплинарный подход к управлению данными, который объединяет принципы DevOps, автоматизацию, оркестрацию и контроль качества для обеспечения непрерывной, масштабируемой и надежной доставки данных от источников до аналитических и продуктовых систем. В традиционных организациях путь данных от источника до отчета часто занимает недели. Инженеры данных, аналитики и...

Delta Lake — это открытый формат хранения данных, спроектированный для обеспечения надежности, качества и производительности озер данных. Он не является самостоятельной базой данных, а работает как транзакционный уровень поверх существующих облачных хранилищ, таких как Amazon S3 или Yandex Object Storage. Основная миссия Delta Lake — решить фундаментальные проблемы традиционных...

DevOps (DEVelopment OPeration) – это набор практик для повышения эффективности процессов разработки (Development) и эксплуатации (Operation) программного обеспечения (ПО) за счет их непрерывной интеграции и активного взаимодействия профильных специалистов с помощью инструментов автоматизации. Девопс позиционируется как Agile-подход для устранения организационных и временных барьеров между командами разработчиков и других участников жизненного...
Druid – это высокопроизводительная, распределенная база данных для аналитики в реальном времени (real-time analytics database). Она создана для быстрых OLAP-запросов (Online Analytical Processing) по большим наборам данных. Druid идеально подходит для сценариев, где требуется мгновенная обработка и визуализация потоковых или исторических данных, таких как бизнес-аналитика, мониторинг сетевых событий, анализ пользовательского...

DuckDB — это высокопроизводительная встраиваемая аналитическая система управления базами данных (СУБД), разработанная для быстрого и эффективного выполнения аналитических запросов (OLAP). Её часто и справедливо называют "SQLite для аналитики". Подобно SQLite, DuckDB не требует установки отдельного серверного процесса; она интегрируется непосредственно в приложение в виде библиотеки. Это кардинально упрощает развертывание...

Edge Computing (Граничные вычисления) - это архитектурная парадигма, предполагающая перенос вычислительных мощностей и логики обработки данных из централизованных дата-центров (облаков) на периферию сети - туда, где эти данные генерируются. Представьте, что вы управляете огромным современным заводом. Ежесекундно тысячи датчиков генерируют гигабайты информации: температура, вибрация, видеопотоки. Если отправлять каждый...

Elasticsearch – это одна из самых популярных поисковых систем в области Big Data, масштабируемое нереляционное хранилище данных с открытым исходным кодом, аналитическая NoSQL-СУБД с широким набором функций полнотекстового поиска. Назначение и основные функциональные возможности Elasticsearch (ES) – масштабируемая утилита полнотекстового поиска и аналитики, которая позволяет быстро в режиме реального времени хранить,...
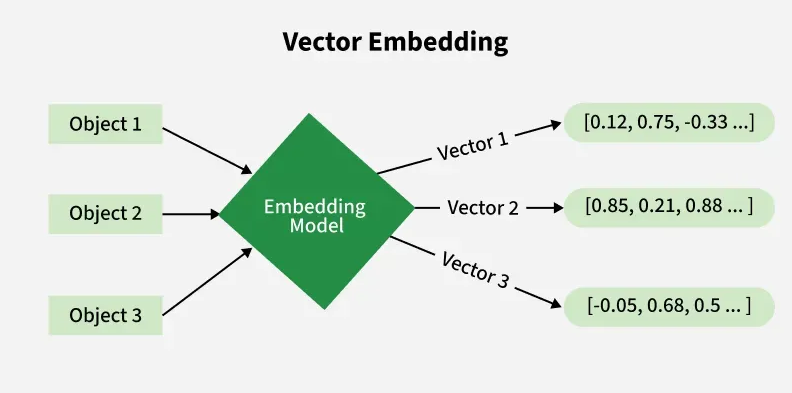
Embedding (Ембеддинг) — это техника в машинном обучении и обработке естественного языка, которая преобразует категориальные данные, такие как слова, товары или пользователи, в плотные числовые векторы фиксированной длины в многомерном пространстве. Проще говоря, ембеддинг — это способ перевести объекты из реального мира на язык, понятный компьютеру. Он не просто кодирует...
Переменная окружения (среды) ( environment variable) — текстовая переменная операционной системы, хранящая какую-либо информацию — например, данные о настройках системы.

Туманные вычисления (Fog Computing) - это архитектурная парадигма, которая расширяет возможности облачных вычислений до края сети. Она переносит вычислительные ресурсы, хранилища и сетевые сервисы из удаленных дата-центров ближе к конечным устройствам. Метафора, предложенная Cisco, идеально описывает суть: туман - это то же облако, но оно находится прямо у земли....

Gemini – это семейство передовых мультимодальных моделей искусственного интеллекта (ИИ), разработанное Google DeepMind. Gemini создана с нуля для мультимодальности, что означает способность понимать, обрабатывать и комбинировать различные типы информации, такие как текст, код, изображения, аудио и видео. Модели Gemini предлагаются в различных размерах (Ultra, Pro, Nano) для эффективного применения в...

GIL (Global Interpreter Lock) - это механизм синхронизации в интерпретаторе Python, который обеспечивает выполнение байткода только одним потоком одновременно внутри одного процесса, упрощая управление памятью, но ограничивая параллельное выполнение CPU-интенсивных задач. Данное жесткое правило действует даже на современных мощных многоядерных процессорах. Новички часто сталкиваются с непониманием этого механизма при...
Glove (Global Vectors for Word Representation) - это алгоритм обучения для получения векторных представлений для слов. Обучение выполняется на агрегированной глобальной статистике совпадений слово-слово из корпуса. Полученные представления демонстрируют интересные линейные подструктуры векторного пространства слов, коррелирующие с их семантическим значением.
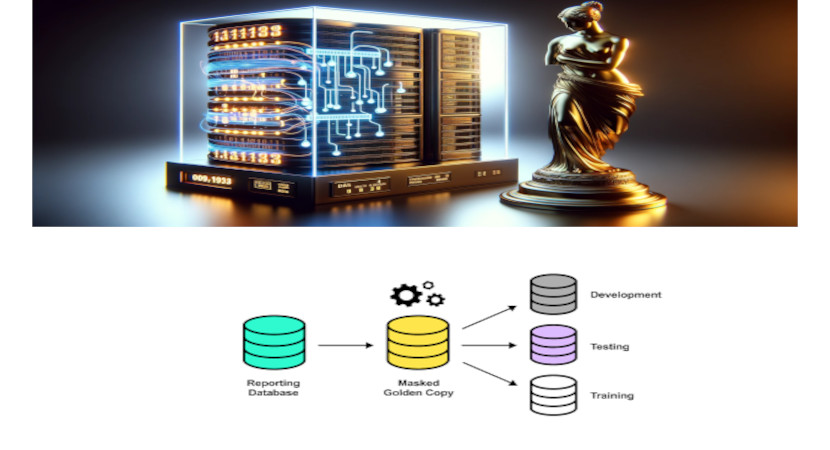
В мире разработки программного обеспечения и управления данными существует понятие "Golden Copy" или "Золотая Копия". Этот термин относится к единственной, авторитетной и доверенной версии данных, которая служит основой для всех других копий в системе. Золотая Копия представляет собой образец данных, который считается источником правды для всей системы. Это позволяет избежать...