 1031
1031 
Содержание
- Проблема масштабируемости HDFS: почему появился Ozone S3
- Архитектура Apache Ozone
- Основные преимущества и возможности
- Примеры кода и интеграции: Работа с Ozone S3 через S3-совместимый интерфейс
- Примеры кода и интеграции: Интеграция с Hadoop и Spark
- Ограничения и особенности Apache Ozone S3
- Сценарий простого развертывания (Docker Compose)
- Заключение
Apache Ozone S3 — это распределенное, масштабируемое и согласованное хранилище объектов, созданное для экосистемы Apache Hadoop. Оно спроектировано для решения фундаментальных проблем масштабируемости HDFS (Hadoop Distributed File System), в первую очередь связанных с ограничением на количество файлов из-за метаданных, хранящихся в памяти NameNode. В отличие от HDFS, которое является файловой системой, Ozone предоставляет объектный интерфейс, что позволяет ему эффективно хранить миллиарды как крупных, так и мелких объектов, делая его идеальным решением для современных задач больших данных, таких как аналитика, машинное обучение и хранение данных IoT.
Проблема масштабируемости HDFS: почему появился Ozone S3
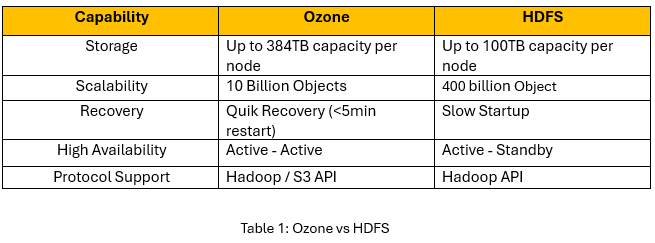
Традиционная архитектура HDFS десятилетиями была стандартом для хранения больших данных. Однако ее центральный компонент, NameNode, хранит всю информацию о файловой системе (метаданные) в оперативной памяти. Это создает серьезное ограничение: чем больше файлов в кластере, тем больше памяти требуется NameNode. Когда количество файлов достигает сотен миллионов, NameNode становится узким местом, что ограничивает дальнейшую масштабируемость данных кластера. Apache Ozone был разработан, чтобы устранить этот недостаток. Он отделяет управление пространством имен от управления блоками, что позволяет системе масштабироваться до миллиардов и даже триллионов объектов.
Архитектура Apache Ozone
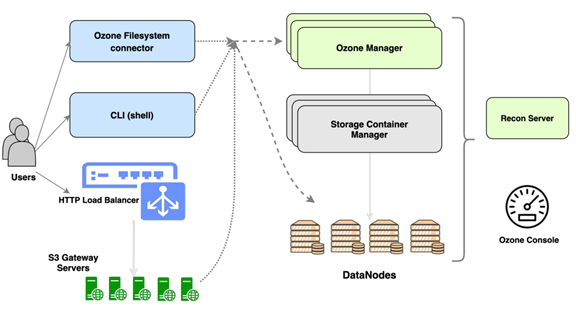
Архитектура Ozone S3 более распределенная и гибкая по сравнению с HDFS. Она состоит из нескольких ключевых компонентов, которые совместно обеспечивают надежность и масштабируемость данных.
- Ozone S3 Manager (OM): Это менеджер пространства имен в Ozone. Он отвечает за обработку запросов пользователей, связанных с объектами, такими как создание, удаление и поиск ключей (объектов). В отличие от NameNode в HDFS, OM управляет только иерархией пространства имен и не отслеживает расположение блоков данных.
- Storage Container Manager (SCM): Это менеджер физического хранения. SCM управляет Datanodes и отвечает за жизненный цикл контейнеров — базовых единиц хранения в Ozone. Он отслеживает репликацию данных, обеспечивает их целостность и управляет состоянием всего пула Datanodes.
- Datanodes: Как и в HDFS, Datanodes отвечают за фактическое хранение данных. Однако в Ozone они оперируют не блоками, а «контейнерами». Контейнер — это независимый объект хранения размером в несколько гигабайт, внутри которого хранятся блоки данных от множества разных объектов. Такой подход значительно снижает нагрузку на управление метаданными.
Важная заметка: Ключевое отличие Ozone S3 от многих других объектных хранилищ — это строгая согласованность данных (strong consistency). Когда клиент записывает данные и получает подтверждение, любой последующий запрос на чтение этого объекта гарантированно вернет именно эти, последние записанные данные. Это критически важно для аналитических рабочих нагрузок.
Основные преимущества и возможности
Apache Ozone S3 предлагает ряд преимуществ, делающих его современным решением для хранения больших данных.
Экстремальная масштабируемость: Благодаря распределенной архитектуре метаданных, Ozone может хранить миллиарды объектов без деградации производительности. Это делает его идеальным выбором для Data Lake нового поколения. Для более глубокого понимания принципов построения Data Lake вы можете ознакомиться с нашими курсами на нашем портале.
S3-совместимость: предоставляется нативный S3-совместимый API через компонент S3 Gateway. Это позволяет использовать существующие инструменты, SDK и приложения, разработанные для Amazon S3, без каких-либо изменений.
Интеграция с экосистемой Hadoop: Ozone S3 легко интегрируется с такими фреймворками, как Apache Spark, Apache Hive и Apache NiFi. Он может служить заменой для HDFS, предоставляя более масштабируемое и гибкое хранилище объектов.
Поддержка контейнеризации: Ozone может быть развернут в контейнерных средах, таких как Docker и Kubernetes, что соответствует современным подходам к развертыванию и управлению инфраструктурой.
Высокая надежность и безопасность: Данные в объектном хранилище реплицируются между Datanodes с использованием протокола RAFT (через библиотеку Apache Ratis), что обеспечивает высокую отказоустойчивость. Система также поддерживает механизмы безопасности, включая интеграцию с Kerberos и Apache Ranger.
Примеры кода и интеграции: Работа с Ozone S3 через S3-совместимый интерфейс
Благодаря компоненту S3 Gateway, взаимодействие с данным обьектным хранилищем ничем не отличается от работы с Amazon S3. Для этого можно использовать любой S3-совместимый клиент, например, AWS CLI.
# Указываем эндпоинт нашего S3 Gateway export AWS_ENDPOINT_URL=http://<s3-gateway-host>:9878 # Указываем ключи доступа (полученные в Ozone) export AWS_ACCESS_KEY_ID=<your-access-key> export AWS_SECRET_ACCESS_KEY=<your-secret-key> # 1. Создаем новый бакет (bucket) с именем 'my-bucket' aws s3api create-bucket --bucket my-bucket # 2. Загружаем локальный файл 'report.csv' в бакет aws s3api put-object --bucket my-bucket --key reports/report.csv --body report.csv # 3. Список объектов в бакете aws s3api list-objects --bucket my-bucket # 4. Скачиваем объект обратно aws s3api get-object --bucket my-bucket --key reports/report.csv downloaded_report.csv
Примеры кода и интеграции: Интеграция с Hadoop и Spark
Ozone S3 предоставляет файловую систему o3fs, которая позволяет инструментам экосистемы Hadoop работать с Ozone так же, как они работают с HDFS.
# 1. Создаем том и бакет через нативный CLI Ozone
ozone sh volume create /myvolume
ozone sh bucket create /myvolume/mybucket
# 2. Теперь работаем с данными через стандартную утилиту hdfs dfs,
# указывая путь в формате o3fs://<bucket>.<volume>/<path>
hdfs dfs -mkdir -p o3fs://mybucket.myvolume/data/raw
hdfs dfs -put mylocalfile.txt o3fs://mybucket.myvolume/data/raw/
# 3. Запуск Spark-задачи, которая читает данные из Ozone
# (пример для spark-shell)
spark-shell --master yarn
# Внутри Spark Shell:
val df = spark.read.text("o3fs://mybucket.myvolume/data/raw/mylocalfile.txt")
df.show()
Ограничения и особенности Apache Ozone S3
Несмотря на все преимущества, при внедрении, следует учитывать несколько моментов:
- Относительная новизна: Проект моложе, чем HDFS или коммерческие облачные хранилища. Сообщество пользователей пока меньше, а некоторые специфические сценарии могут быть хуже документированы.
- Операционная сложность: Как любая распределенная система, требуется экспертизы для развертывания, мониторинга и обслуживания. Управление компонентами OM, SCM и Datanodes добавляет дополнительный уровень сложности по сравнению с более простыми системами.
- Неполная совместимость с S3 API: S3 Gateway обеспечивает отличную совместимость с базовыми операциями, но может не поддерживать некоторые продвинутые или редко используемые функции Amazon S3 API, такие как управление жизненным циклом объектов на стороне сервера или сложные политики доступа.
Сценарий простого развертывания (Docker Compose)
Самый быстрый способ познакомиться с Apache Ozone — развернуть его локально с помощью Docker. Команда проекта предоставляет готовый docker-compose.yaml файл.
#---Клонируйте репозиторий Ozone: git clone https://github.com/apache/ozone.git #---Перейдите в директорию с Docker-конфигурацией: cd ozone/compose/ozone #---Запустите кластер: docker-compose up -d
Эта команда в фоновом режиме поднимет все необходимые сервисы: SCM, OM, один Datanode и S3 Gateway. После запуска вы сможете сразу же начать работать с кластером, используя примеры кода, приведенные выше, указав в качестве эндпоинта localhost.
Заключение
Apache Ozone S3 представляет собой значительный шаг вперед в эволюции систем хранения данных для экосистемы Hadoop. Он успешно решает проблему масштабируемости, присущую HDFS, предлагая распределенное хранилище объектов, способное управлять миллиардами файлов. Практические возможности интеграции через S3 API и файловую систему o3fs, а также простота первоначального развертывания через Docker, делают его привлекательным выбором для построения современных, высокопроизводительных платформ больших данных. Он позволяет компаниям эффективно управлять постоянно растущими объемами информации, открывая новые возможности для аналитики и машинного обучения.
Список справочной литературы
- Официальная документация Apache Ozone
- Статья «Understanding Apache Ozone: An Object Store for Hadoop» на блоге Cloudera https://blog.cloudera.com/understanding-apache-ozone-an-object-store-for-hadoop/
- Статья «Apache Ozone vs. HDFS: A Comparative Guide» на портале Dremio https://www.dremio.com/resources/guides/apache-ozone-vs-hdfs-a-comparative-guide/
- Официальный репозиторий Apache Ozone с Docker-конфигурациями https://github.com/apache/ozone