 339
339 
Содержание
- Предпосылки использования слоя ODS
- Архитектура и место ODS в контуре данных
- Принцип работы и механизм обновления слоя ODS
- Сценарии использования
- Взаимодействие и код для интеграции Change Data Capture c ODS
- Главные отличия ODS vs DWH vs Data Lake
- Технологический стек для построения ODS
- Заключение
- Референсные ссылки:
ODS (Operational Data Store) — это интеграционный слой хранилища данных, предназначенный для консолидации и оперативного хранения очищенных и согласованных данных из нескольких транзакционных систем с целью поддержки оперативной аналитики и последующей загрузки в аналитические хранилища. Эта база располагается между источниками сырой информации и аналитическим хранилищем. Транзакционные системы (OLTP) отлично справляются с быстрыми операциями записи. Однако они совершенно не подходят для тяжелой сквозной аналитики. Сложный аналитический запрос может надолго заблокировать рабочую таблицу. В результате пользователи столкнутся с медленной загрузкой приложения. Это недопустимо для любого современного цифрового бизнеса. Поэтому инженеры данных придумали промежуточный технологический слой. Этим слоем и является оперативное хранилище данных.
Система непрерывно забирает свежие данные из всех рабочих баз. Затем она объединяет их в единую понятную структуру. Задержка передачи информации обычно составляет всего несколько миллисекунд. Таким образом, бизнес получает самую актуальную картину происходящего. Менеджеры могут строить сложные отчеты без влияния на продуктив. Кроме того, такая база выполняет роль надежного буфера. Корпоративное хранилище (DWH) требует очень тщательной очистки данных. Этот ночной процесс занимает значительное серверное время. Оперативная база предварительно агрегирует сырые строки для загрузки. В итоге общая система работает стабильно и предсказуемо.
Предпосылки использования слоя ODS
Рассмотрим ключевые причины внедрения этой технологии в компаниях. Каждая описанная проблема требует современного инженерного подхода.
Снижение нагрузки на источники. Тяжелые выборки переносятся на отдельный выделенный сервер.
- Транзакционные базы работают без перегрузок.
- Конечные клиенты не видят системных задержек.
Сведение сущностей воедино. Данные из CRM и биллинга мгновенно объединяются.
- Профиль клиента становится полным и прозрачным.
- Существенно упрощается поиск нужной информации.
Подготовка к DWH. База служит надежным источником для ночного батча.
- Снижается риск потери важных исторических записей.
- Ускоряется работа утренних аналитических витрин.
Эти факторы делают технологию незаменимой для крупных IT-компаний. Разделение ответственности систем является золотым стандартом современной разработки.
Архитектура и место ODS в контуре данных
Архитектура оперативного хранилища всегда логично встроена в общий поток. Этот непрерывный поток в инженерии называется Data Flow. Источники генерируют огромное количество абсолютно разрозненных бизнес-событий. Эти важные события нужно быстро собрать и структурировать. Интеграционный слой аккуратно захватывает изменения из рабочих баз. Для этого инженеры часто используют современные брокеры сообщений. Затем собранная информация непрерывным потоком льется в базу ODS. Здесь сырые строки проходят легкую автоматическую трансформацию на лету. Система приводит даты и числа к единому корпоративному стандарту.
После этого данные становятся мгновенно доступны всем внутренним потребителям. Главным потребителем выступает классическое корпоративное хранилище DWH. Оно обычно забирает нужный исторический срез один раз в сутки. Другими потребителями выступают BI-системы и различные корпоративные микросервисы. Таким образом, оперативный слой одновременно обслуживает множество разных систем. Это требует высокой надежности всего настроенного контура.
Выделим основные базовые элементы классической архитектуры потоков данных. Понимание этих зон критически необходимо каждому инженеру данных.
Слой источников данных. Это транзакционные базы ERP и различных CRM систем.
- Генерируют все первичные важные бизнес-события.
- Требуют максимальной защиты от случайных перегрузок.
Транспортный интеграционный слой. Это современные брокеры сообщений вроде Apache Kafka.
- Обеспечивают надежную гарантированную доставку всех пакетов.
- Эффективно сглаживают пиковые нагрузки корпоративной сети.
Слой оперативного хранения ODS. Непосредственно сама выделенная целевая база данных.
- Надежно хранит текущее актуальное состояние объектов.
- Отдает нужную информацию за доли секунды потребителям.
Четкое разделение слоев сильно упрощает техническую поддержку платформы. Инженеры могут безопасно обновлять компоненты без остановки всей системы.
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Принцип работы и механизм обновления слоя ODS
Механизм обновления данных — это настоящее сердце всей системы. Существует два основных инженерных подхода к загрузке информации.
- Первый подход называется классическим пакетным (Batch) копированием.
- Второй подход называется современным потоковым (Streaming) чтением.
Сегодня индустрия активно переходит именно на потоковую обработку данных. Пакетная загрузка работает строго по заранее заданному расписанию. Скрипт запускается каждый час или один раз в день. Он долго ищет новые или измененные строки в источнике. Затем он переносит их единым очень большим куском. Это создает высокую пиковую нагрузку на внутреннюю сеть. Кроме того, скачанная информация быстро теряет свою актуальность. Часовая задержка абсолютно неприемлема для многих современных цифровых сервисов.
Поэтому продвинутые инженеры используют технологию Change Data Capture (CDC). Это специальная технология мгновенного захвата изменений данных. База-источник всегда пишет свой внутренний лог транзакций. В популярной PostgreSQL этот механизм называется WAL (Write-Ahead Log). Инструмент вроде платформы Debezium непрерывно читает этот системный лог. Он моментально видит абсолютно любое изменение конкретной строки. Затем он формирует компактное сообщение в формате JSON. Это сообщение сразу отправляется в нужный топик Apache Kafka. Приложение-консьюмер читает свежие сообщения из этого топика. Оно моментально применяет полученные изменения в целевой ODS. Если строка обновилась в источнике, она сразу обновится везде. Задержка такого цикла сокращается до нескольких миллисекунд.

Рассмотрим важные особенности хранения внутри самой целевой базы. Эти внутренние аспекты критичны для поддержания высокой производительности.
Нормализация таблиц. Структура обычно в точности повторяет схему базы-источника.
- Требуется минимальная трансформация данных на лету.
- Существенно ускоряется процесс записи новых событий.
Срок хранения. Исторические версии старых строк здесь никогда не копятся.
- Система хранит только актуальное состояние конкретного объекта.
- Старые неактуальные записи безжалостно удаляются или перезаписываются.
Индексация. Таблицы строго оптимизируются для очень быстрых точечных чтений.
- Специальные индексы создаются по главным ключам сущностей.
- Аналитические агрегации сканируют только небольшие актуальные объемы.
Такой осознанный подход гарантирует максимальную производительность всей системы. Хранилище остается невероятно быстрым даже при сильных пиковых нагрузках.
Сценарии использования
Оперативное хранилище решает исключительно задачи реального времени. Оно совершенно не предназначено для поиска долгих исторических трендов. Его главная цель — показать текущую ситуацию в бизнесе сейчас. Это жизненно необходимо для оперативного управления сложными процессами. Многие современные цифровые приложения просто не могут работать без этого.
Первый популярный сценарий — это единый профиль клиента компании. Маркетологи всего мира называют это подходом Customer 360. Человек делает новый заказ на официальном сайте магазина. Затем он сразу звонит в службу технической поддержки. Оператор должен моментально видеть этот новый созданный заказ. ODS объединяет данные сайта и колл-центра мгновенно. Благодаря этому клиент получает быструю и очень точную помощь.
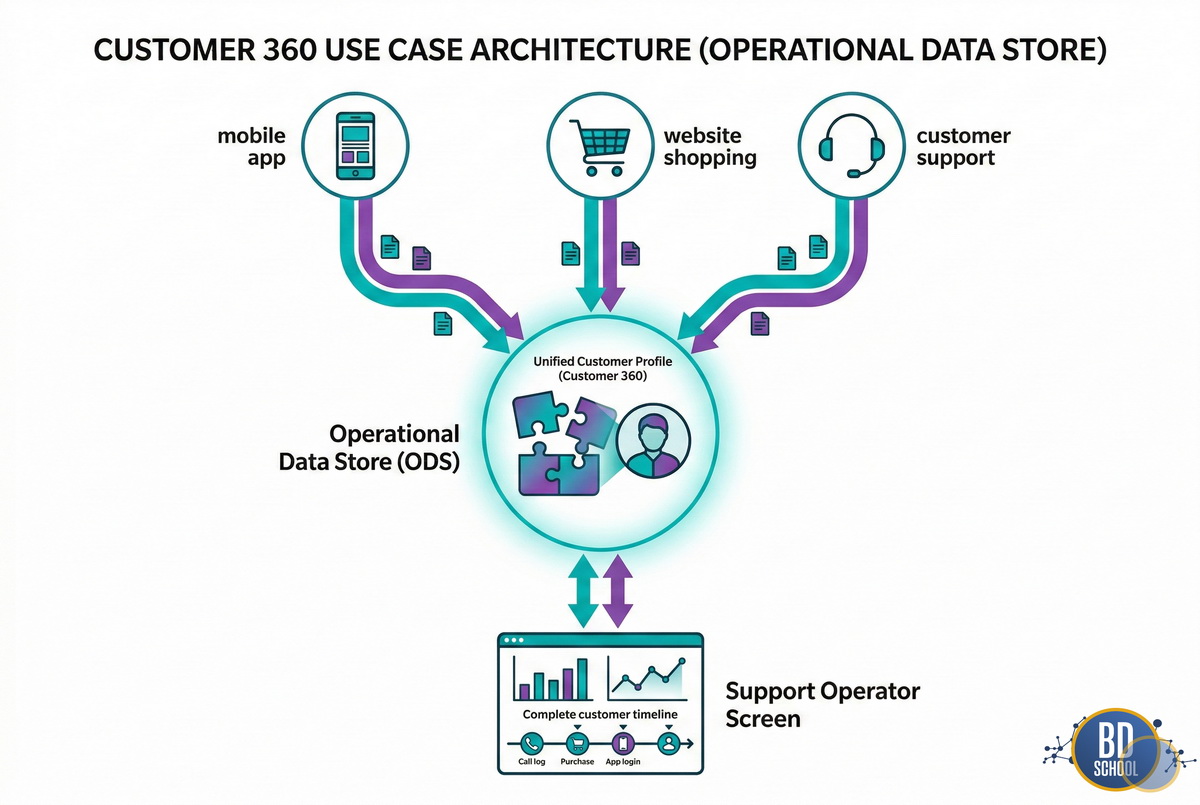
Второй частый сценарий касается оперативной отчетности руководства бизнеса. Менеджерам нужно внимательно следить за выполнением дневного плана продаж. Они открывают красивый дашборд в своей корпоративной BI-системе. Этот рабочий дашборд подключен напрямую к быстрому оперативному слою. Построенные графики обновляются каждую секунду без малейших задержек. Таким образом, руководство может очень быстро принимать управленческие решения.
Третий важный сценарий — это умные триггерные рассылки и алертинг. Система непрерывно мониторит поведение пользователей в реальном времени. Человек положил дорогой товар в корзину и закрыл вкладку. База моментально фиксирует это важное незавершенное действие клиента. Микросервис замечает событие и сразу отправляет push-уведомление на телефон. Это сильно повышает общую финансовую конверсию интернет-магазина.
Выделим основные типы систем, которые активно потребляют эти данные. Интеграция с ними во многом определяет итоговый архитектурный паттерн.
BI-инструменты. Системы визуализации вроде Apache Superset или популярного Metabase.
- Формируют наглядные оперативные дашборды для топ-менеджеров.
- Генерируют короткие и очень быстрые SQL-запросы к базе.
Микросервисы. Внутренние независимые компоненты больших корпоративных IT-платформ.
- Обогащают свои внутренние процессы самыми свежими справочниками.
- Снижают техническую связность между разными командами разработки.
Системы машинного обучения. Модели искусственного интеллекта в режиме реального времени.
- Рассчитывают персональные товарные рекомендации для каждого юзера.
- Оценивают риски возможного мошенничества при банковских транзакциях.
Понимание этих сценариев отлично помогает обосновать высокую стоимость разработки. Инвестиции в инфраструктуру очень быстро окупаются за счет эффективности.
Взаимодействие и код для интеграции Change Data Capture c ODS
Инженеры данных используют различные инструменты для реализации архитектуры. На практике очень часто применяется надежная связка Python и SQL. Язык Python отлично подходит для написания быстрых скриптов потоковой загрузки. Стандартный SQL используется для оперативного извлечения и анализа информации.
Рассмотрим базовый пример перекладки данных в реальном времени. Представим, что у нас есть непрерывный поток логов событий. Эти события лежат в топике популярного брокера Apache Kafka. Нам нужно прочитать их и сразу записать в базу.
В качестве оперативного слоя мы используем реляционную PostgreSQL. Написанный ниже код будет выполнять роль простого и надежного консьюмера.
import json
import psycopg2
from kafka import KafkaConsumer
# Настройка подключения к брокеру потоковых сообщений
consumer = KafkaConsumer(
'orders_topic',
bootstrap_servers=['localhost:9092'],
value_deserializer=lambda m: json.loads(m.decode('utf-8'))
)
# Настройка подключения к нашей целевой базе данных ODS
conn = psycopg2.connect(
dbname="ods_db",
user="data_engineer",
password="secure_password",
host="localhost"
)
cursor = conn.cursor()
# Постоянное чтение потока событий в реальном времени
for message in consumer:
data = message.value
order_id = data.get('order_id')
status = data.get('status')
# Обновление записи (Upsert) в таблице хранилища
insert_query = """
INSERT INTO ods_orders (order_id, status, updated_at)
VALUES (%s, %s, NOW())
ON CONFLICT (order_id) DO UPDATE
SET status = EXCLUDED.status,
updated_at = NOW();
"""
cursor.execute(insert_query, (order_id, status))
conn.commit()
Этот скрипт работает непрерывно в фоновом режиме сервера. Он постоянно обеспечивает абсолютную актуальность информации в целевой таблице. Операция ON CONFLICT в базах данных называется умным апсертом (Upsert). Она просто обновляет статус, если такой заказ уже существует. Это классический технический паттерн для любого оперативного слоя. Теперь бизнес-аналитик может быстро сделать нужный оперативный срез. Ему нужно узнать точное количество заказов со статусом успешной доставки. Аналитический запрос выполняется напрямую к нашей обновляемой горячей таблице.

SELECT
status,
COUNT(order_id) AS total_orders
FROM ods_orders
WHERE updated_at >= CURRENT_DATE
GROUP BY status
ORDER BY total_orders DESC;
Этот легкий запрос отработает буквально за доли секунды. Базе данных совершенно не нужно сканировать глубокую историю за год. Она обрабатывает только текущее актуальное состояние на сегодняшний день.
Практическая архитектура данных
Код курса
PRAR
Ближайшая дата курса
20 апреля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Главные отличия ODS vs DWH vs Data Lake
Новички в инженерии часто путают различные сложные архитектурные концепции. Важно очень четко разграничивать эти три совершенно разные сущности. Каждая из систем решает свои уникальные инженерные и бизнесовые проблемы. Главная разница всегда заключается во внутренней структуре и жизненном цикле. Озеро данных (Data Lake) собирает абсолютно все подряд без разбора. Там бесконтрольно лежат неструктурированные файлы, сырые логи и даже картинки. Озеро никогда не гарантирует высокого качества и чистоты данных. В свою очередь, корпоративное хранилище (DWH) содержит выверенную историческую правду. Там лежат строго агрегированные финансовые показатели за многие прошлые годы. Это хранилище специально оптимизировано для тяжелых сводных аналитических отчетов.
В отличие от них, ODS живет только настоящим моментом. Он принципиально не хранит долгую историю изменений одной сущности. Если клиент внезапно сменил фамилию, старая фамилия просто бесследно затирается. Оперативная база содержит только текущую финальную версию профиля пользователя. Кроме того, общая глубина хранения здесь всегда строго и жестко ограничена. Часто совсем старые записи автоматически архивируются или полностью удаляются скриптами.
Сравним ключевые параметры этих трех популярных архитектурных паттернов. Это обязательно поможет выбрать правильный инструмент для вашей текущей задачи.
Уровень внутренней нормализации. Выбранная структура жестко диктует скорость работы с базой.
- ODS: Высокая степень нормализации (очень похоже на базу-источник).
- DWH: Денормализованные удобные схемы типа «звезда» или «снежинка».
- Data Lake: Полное отсутствие схемы при записи (подход Schema-on-Read).
Допустимая глубина хранения. Параметр определяет требуемые объемы используемых жестких дисков.
- ODS: Хранение данных длится дни, недели или максимум месяцы.
- DWH: Исторические данные надежно хранятся долгие годы и десятилетия.
- Data Lake: Бесконечное хранение абсолютно всех сырых данных компании навсегда.
Типичная системная задержка. Время от генерации события до его доступности аналитику.
- ODS: Строго миллисекунды или максимум секунды (настоящий Real-time).
- DWH: Обычно часы или даже целые сутки (ночная Batch-загрузка).
- Data Lake: Зависит исключительно от настроенных внутренних конвейеров загрузки.
Следовательно, эти мощные системы вовсе не заменяют друг друга. Они органично и эффективно дополняют современную платформу данных любой компании.
Практическое применение Big Data аналитики для решения бизнес-задач
Код курса
PRUS
Ближайшая дата курса
20 апреля, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Технологический стек для построения ODS
Выбор конкретной технологии всегда зависит от строгих требований бизнеса. В природе просто не существует одной идеальной базы для всех случаев. Инженеры обязательно учитывают ожидаемые объемы трафика и сложность моделей данных. Иногда архитекторы используют сразу несколько разных решений в единой связке.
Реляционные базы исторически остаются самым популярным и надежным выбором. Классическая PostgreSQL отлично справляется с умеренными и средними нагрузками. Она из коробки поддерживает строгую консистентность и очень сложные транзакции. Если структура данных часто и непредсказуемо меняется, инженеры используют NoSQL. Документоориентированная база MongoDB позволяет легко сохранять сложные вложенные JSON-объекты. Это навсегда избавляет разработчиков от необходимости писать тяжелые миграции схем.
Для экстремально быстрых задач часто применяют продвинутые In-Memory решения. Популярный Redis хранит всю нужную информацию прямо в оперативной памяти сервера. Любые запросы к нему выполняются за фантастические доли микросекунд. Однако серверная оперативная память стоит довольно дорого, поэтому объемы сильно ограничены.
Рассмотрим основные популярные инструменты для построения надежных потоков данных. Транспортный уровень играет решающую роль в успешности всей архитектуры.
Брокер Apache Kafka. Признанный индустриальный стандарт для корпоративных очередей сообщений.
- Гарантирует надежную доставку событий без малейших потерь данных.
- Легко и горизонтально масштабируется при резком росте потока.
Платформа Debezium. Абсолютный лидер среди инструментов для захвата изменений (CDC).
- Легко интегрируется с большинством популярных реляционных баз данных.
- Быстро переводит бинарные логи транзакций в читаемый текстовый формат.
Фреймворк Apache Flink. Мощный фреймворк для очень сложной потоковой обработки данных.
- Позволяет гибко обогащать события прямо на лету без задержек.
- Умеет объединять разные независимые потоки до записи в базу.
Грамотный и осознанный выбор стека определяет финальный успех всего проекта. Правильно спроектированная архитектура позволяет экономить миллионы рублей на серверном оборудовании.
Заключение
Подводя итоги, оперативное хранилище данных — это исключительно важный архитектурный инструмент. Он эффективно устраняет болезненный разрыв между быстрыми транзакциями и медленной аналитикой. Без него современные цифровые компании быстро теряют гибкость управления процессами. Рабочие системы начинают сильно тормозить от тяжелых и неоптимизированных аналитических запросов. Руководители отделов получают устаревшие сводные отчеты с недопустимо большими опозданиями. Однако внедрение ODS всегда требует серьезных финансовых и инженерных ресурсов. IT-компания должна постоянно поддерживать сложную разветвленную инфраструктуру потоковой передачи данных. Приходится дополнительно нанимать дорогих дата-инженеров и опытных администраторов баз данных.
Поэтому малому и начинающему бизнесу этот подход часто бывает избыточен. Им вполне достаточно поднять простую реплику основной базы для базовой отчетности. Таким образом, эта сложная технология нужна преимущественно средним и крупным предприятиям. Тем бизнесам, кому критически важно принимать обоснованные решения в реальном времени. Первоначальные инвестиции быстро окупаются за счет стабильности работы всех сервисов. Кроме того, заметно растет общий уровень удовлетворенности конечных пользователей вашего приложения.
Референсные ссылки:
- [What is an Operational Data Store: A Complete Guide for 2024] (https://atlan.com/what-is/operational-data-store/)
- [What Happened to the Operational Data Store?] (https://materialize.com/blog/operational-data-store/)
- [What is Operational Data Stores? — GeeksforGeeks] (https://www.geeksforgeeks.org/software-testing/what-is-operational-data-stores/)