 280
280 
Содержание
- Архитектура и Ключевые особенности NumPy
- Механизм работы NumPy - Взгляд изнутри
- Управление памятью и Strides
- Система типов (Dtypes)
- Принцип Бродкастинга (Broadcasting)
- Сценарии использования пакета NumPy
- Взаимодействие и Код (IPython/Jupyter Tricks)
- Performance Battle - List vs NumPy (Jupyter Magic)
- Подводные камни: Copy vs View
- Заключение
- Референсные ссылки
NumPy (Numerical Python) — это фундаментальная библиотека для языка Python, предназначенная для высокопроизводительных численных вычислений, обеспечивающая работу с многомерными массивами, векторизованными операциями и базовыми инструментами линейной алгебры, статистики и научных расчётов.
Это база, на которой стоит вся экосистема Data Science. Без понимания NumPy невозможно эффективно работать с Pandas, Scikit-learn или TensorFlow, так как все эти инструменты используют массивы NumPy «под капотом» для обмена данными. Библиотека решает главную проблему чистого Python — низкую скорость обработки больших объемов числовых данных.
Архитектура и Ключевые особенности NumPy
Главным строительным блоком библиотеки является объект ndarray (N-dimensional array). В отличие от стандартных списков Python, которые являются просто контейнерами ссылок на объекты в памяти, массив NumPy — это структурированный блок данных. Основные архитектурные отличия, обеспечивающие производительность:
Однородность данных: Все элементы в ndarray должны иметь одинаковый тип данных (например, только int32 или только float64). Это позволяет интерпретатору заранее знать, сколько памяти занимает каждый элемент.
Фиксированный размер: При создании массива выделяется непрерывный блок памяти. Изменение размера массива обычно требует создания новой копии, что дисциплинирует разработчика в вопросах управления ресурсами.
Векторизация (Vectorization): Это способность выполнять математические операции над целыми массивами сразу, без использования явных циклов for в коде Python.
Векторизация переносит вычислительную нагрузку с медленного интерпретатора Python на оптимизированный код C.
- Это делает код не только быстрее, но и чище.
- Операции применяются ко всему набору данных одновременно.
- Снижается вероятность ошибок, связанных с индексацией в циклах.
Таким образом, архитектура NumPy спроектирована для максимальной эффективности при работе с числами, жертвуя гибкостью списков ради скорости и компактности.
Механизм работы NumPy — Взгляд изнутри
Понимание того, как NumPy управляет памятью, отличает новичка от профессионала. Эффективность библиотеки строится на трех китах: непрерывном расположении в памяти, механизме шагов (strides) и типах данных.
Управление памятью и Strides
Когда вы создаете список в Python, интерпретатор создает массив указателей. Каждый указатель ведет на отдельный объект Python (число), который может находиться в любой части оперативной памяти. Процессору приходится «прыгать» по памяти, что убивает кэширование CPU.
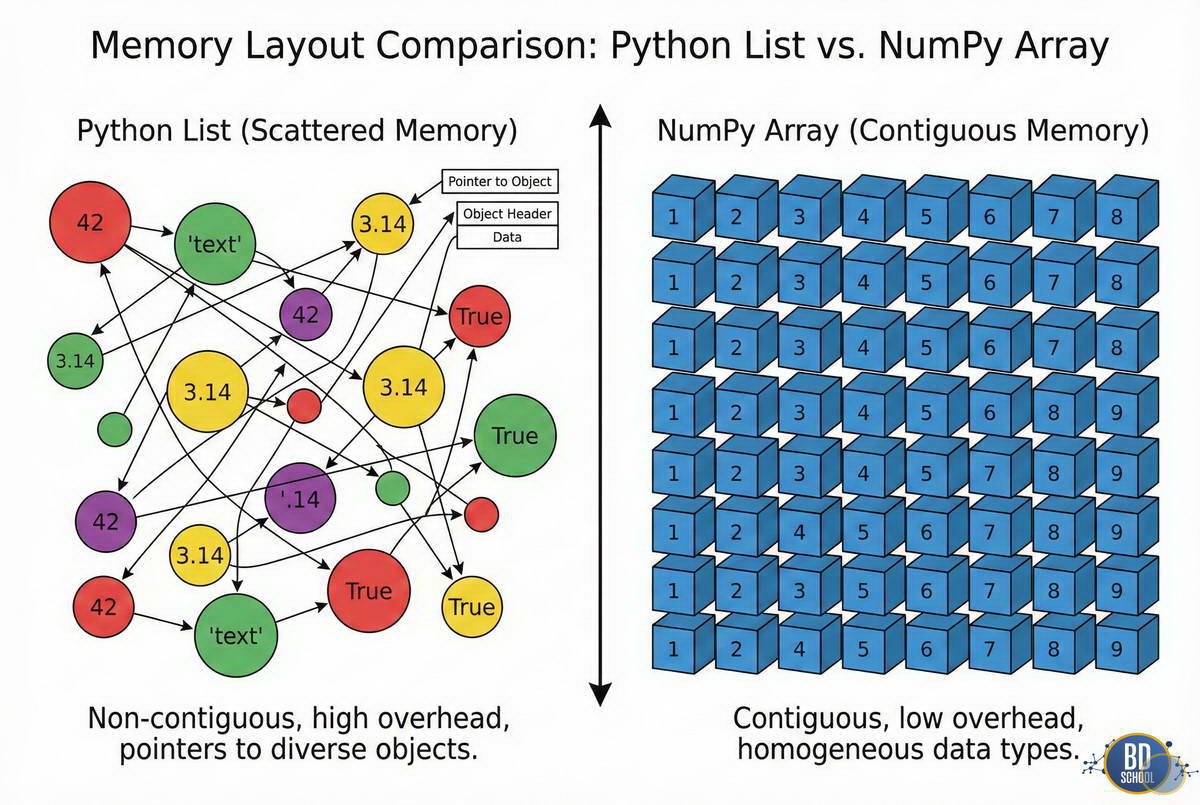
NumPy делает иначе:
- Contiguous Memory Layout: Данные лежат в памяти единым плотным блоком.
- CPU Cache Friendly: Процессор загружает данные в кэш целыми линиями, что ускоряет доступ в десятки раз.
- Strides (Шаги): Это метаданные, которые говорят NumPy, сколько байт нужно пропустить, чтобы перейти к следующему элементу по каждому измерению.
Благодаря механизму Strides, многие операции (например, транспонирование матрицы или взятие среза) вообще не копируют данные. NumPy просто создает новое «представление» (View) с измененными шагами, указывающее на тот же участок памяти. Это происходит мгновенно, даже для гигабайтных массивов.
Система типов (Dtypes)
Python динамически типизирован, но NumPy требует статической типизации внутри массивов. Библиотека предоставляет свои типы данных, которые напрямую соответствуют машинным типам C:
- np.int8, np.int16, np.int32, np.int64 — знаковые целые числа.
- np.uint8 — беззнаковые (от 0 до 255), идеально для изображений.
- np.float32, np.float64 — числа с плавающей точкой.
Правильный выбор типа данных критически важен для Big Data. Использование float32 вместо стандартного float64 сокращает потребление оперативной памяти ровно в два раза без существенной потери точности в задачах глубокого обучения.
Принцип Бродкастинга (Broadcasting)
Бродкастинг — это мощный механизм, позволяющий выполнять арифметические операции над массивами разных форм (shapes). Это избавляет от необходимости вручную копировать и растягивать данные, чтобы привести их к одному размеру.
Правила бродкастинга работают строго по алгоритму. NumPy сравнивает измерения двух массивов, начиная с последнего (справа налево). Измерения совместимы, если
- Они равны.
- Одно из них равно 1.
Если измерение равно 1, NumPy виртуально «растягивает» массив вдоль этой оси, копируя значения, чтобы соответствовать размеру второго массива.
Пример логики бродкастинга (правило работает справа налево):
-
Выравнивание (Alignment):
-
У нас есть массив A с формой
(4, 3). -
У нас есть массив B с формой
(3,). -
NumPy выравнивает их по правому краю.
-
-
Добавление недостающих измерений (Prepending 1s):
-
Поскольку у B меньше измерений, чем у A (1 против 2), NumPy автоматически добавляет
1слева к форме B. -
Теперь B виртуально имеет форму
(1, 3).
-
-
Сравнение и Растяжение (Stretching):
-
Сравниваем измерения справа налево:
-
Ось 1 (столбцы): У A —
3, у B —3. Они равны → ОК. -
Ось 0 (строки): У A —
4, у B —1. Одно из них равно 1 → ОК (NumPy растянет B по этой оси).
-
-
-
Результат: Массив B (который был строкой
[x, y, z]) копируется 4 раза вниз, чтобы стать матрицей(4, 3), и затем складывается с A.
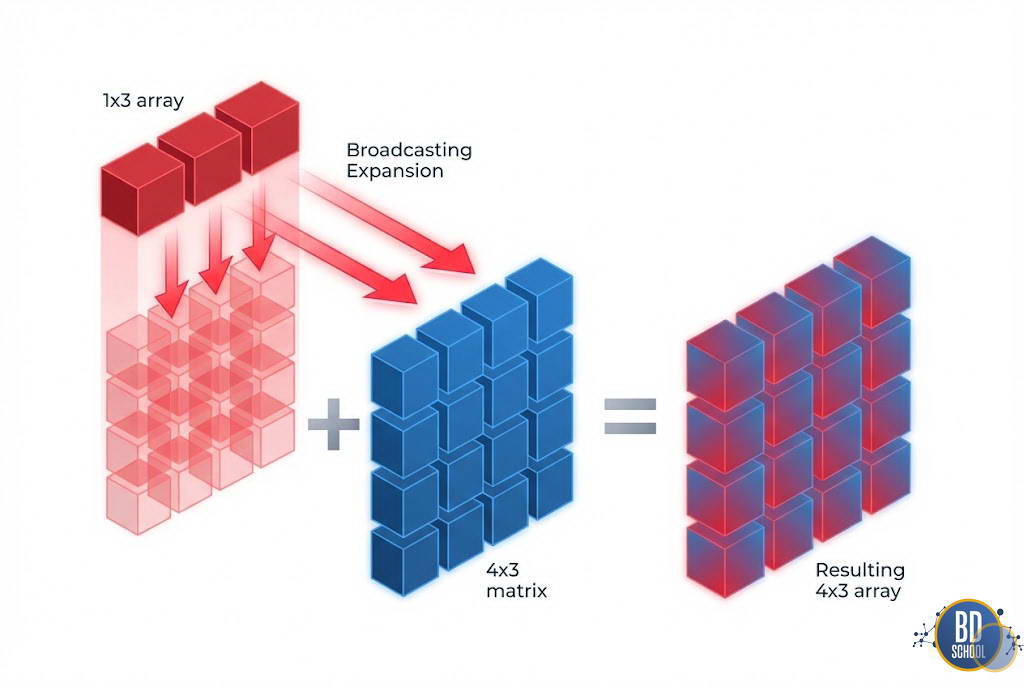
Этот механизм является основой лаконичного синтаксиса NumPy, позволяя писать сложные математические формулы в одну строку кода.
Пример кода для иллюстрации
import numpy as np
A = np.ones((4, 3)) # Матрица 4x3 из единиц
B = np.array([10, 20, 30]) # Вектор (3,)
# Операция работает!
C = A + B
print(f"Shape A: {A.shape}")
print(f"Shape B: {B.shape}")
print(f"Result shape: {C.shape}")
# Вывод: (4, 3)
print(C)
# Каждая строка A увеличилась на [10, 20, 30]
# [[11., 21., 31.],
# [11., 21., 31.],
# [11., 21., 31.],
# [11., 21., 31.]]
Сценарии использования пакета NumPy
NumPy редко используется в вакууме, но он присутствует везде, где есть числа. Можно выделить несколько ключевых направлений, где библиотека незаменима.
Основные области применения:
- Линейная алгебра и ML: Матричное умножение, поиск собственных векторов, разложение матриц (SVD, PCA). Все веса нейронных сетей — это тензоры (многомерные массивы) NumPy.
- Обработка изображений: Любое изображение для компьютера — это массив. Черно-белое фото — 2D массив (высота x ширина), цветное — 3D (высота x ширина x 3 канала RGB).
- Обработка сигналов: Анализ временных рядов, преобразование Фурье, фильтрация аудиоданных.
- Генерация данных: Создание синтетических наборов данных с заданным распределением (нормальное, равномерное) для тестирования гипотез.
Понимание этих сценариев помогает инженеру данных видеть за сухими таблицами реальные математические структуры.
Нейронные сети на Python
Код курса
PYNN
Ближайшая дата курса
10 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
Взаимодействие и Код (IPython/Jupyter Tricks)
Работа с NumPy в среде Jupyter Notebook дает огромные преимущества благодаря интерактивности и специальным «магическим» командам.
Создание и базовые операции
import numpy as np # Создание массива из списка arr = np.array([1, 2, 3, 4, 5], dtype='int32') # Генерация последовательности (аналог range, но быстрее и может быть дробным) # Создаст массив от 0 до 10 с шагом 0.5 grid = np.arange(0, 10, 0.5) # Линейное пространство: 5 точек, равномерно распределенных от 0 до 1 points = np.linspace(0, 1, 5)
Пример Векторизации
Вместо цикла for мы применяем операцию ко всему объекту.
# Обычный Python (плохо для больших данных)
data = [1, 2, 3, 4, 5]
result = []
for x in data:
result.append(x * 2)
# NumPy (векторизация)
arr = np.array([1, 2, 3, 4, 5])
result_np = arr * 2 # Умножает каждый элемент мгновенно
Булева индексация (Маски)
Это один из самых частых паттернов в анализе данных — фильтрация без циклов.
# Создаем случайный массив data = np.random.randn(1000) # Фильтр: оставляем только положительные значения # data > 0 создает маску [True, False, True...], которая применяется к массиву positive_data = data[data > 0]
Использование таких конструкций делает код читаемым и близким к математической записи условий.
Performance Battle — List vs NumPy (Jupyter Magic)
В Jupyter Notebook есть встроенная команда %timeit, которая запускает код множество раз и вычисляет среднее время выполнения. Это лучший способ убедиться в превосходстве NumPy.
Сравним поэлементное перемножение двух больших массивов (1 миллион элементов):
# Подготовка данных size = 1_000_000 list_a = list(range(size)) list_b = list(range(size)) arr_a = np.arange(size) arr_b = np.arange(size)
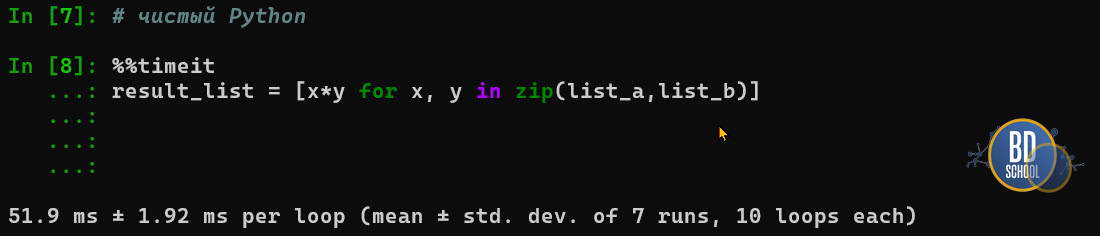
Тест 1: Чистый Python
%%timeit # List comprehension - самый быстрый способ в чистом Python result_list = [x * y for x, y in zip(list_a, list_b)]
Результат: ~80 ms per loop (зависит от железа).
Тест 2: NumPy
%%timeit # Векторное умножение result_arr = arr_a * arr_b
Результат: ~1-2 ms per loop.

Разница составляет 50-100 раз. Если добавить сложные математические функции (синус, логарифм), разрыв может достигать 300-400 раз. Именно поэтому в Big Data никто не пишет математику на чистом Python.
Подводные камни: Copy vs View
Одна из самых коварных ловушек NumPy для новичков — это управление памятью при срезах (slicing). В стандартном Python срез списка list[:] создает его копию. В NumPy срез создает View (Представление). Это означает, что новый массив ссылается на те же данные в памяти, что и старый.
Пример опасной ситуации:
arr = np.array([1, 2, 3, 4, 5]) slice_arr = arr[0:2] # Берем первые два элемента slice_arr[0] = 999 # Меняем элемент в СРЕЗЕ print(arr)
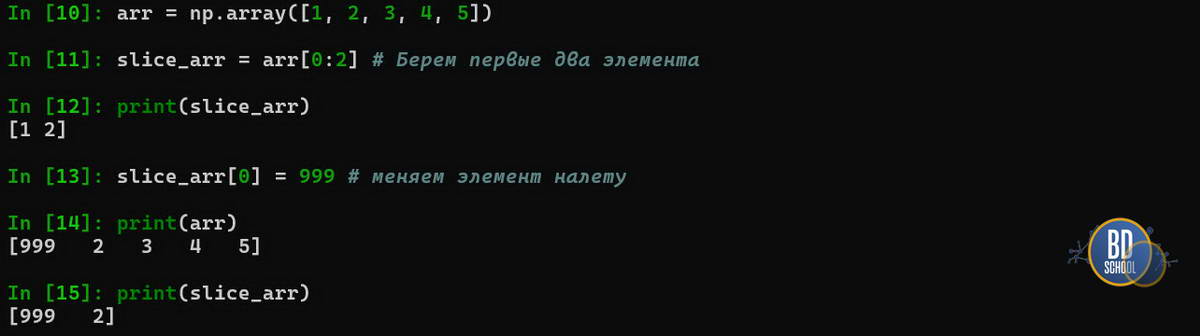
Это сделано для производительности: копирование гигабайтного массива занимало бы слишком много времени.
Как избежать проблем:
Если вам нужна независимая копия данных, используйте метод .copy():
slice_arr_safe = arr[0:2].copy() slice_arr_safe[0] = 777 # Исходный arr останется без изменений
Понимание разницы между представлением и копией спасает от часов отладки «необъяснимых» изменений данных.
Еще больше примеров вы сможете увидеть в видео про основы работы с библиотекой NumPy, которое является частью бесплатного видео курса записанного преподавателями «Школы больших данных» и доступного на сайте нашего проекта «Школы Питон».
ML Практикум: от теории к промышленному использованию
Код курса
PYML
Ближайшая дата курса
30 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
Заключение
NumPy — это не просто библиотека, а стандарт де-факто для вычислений в Python. Она обеспечивает мост между высокоуровневым удобным синтаксисом Python и низкоуровневой производительностью C.
Освоение NumPy дает вам:
- Понимание того, как данные хранятся в памяти.
- Навык писать векторизованный код без лишних циклов.
- Базу для перехода к более сложным инструментам, таким как Pandas (для табличных данных) или PyTorch (для нейросетей).
Следующим логическим шагом в обучении будет изучение Pandas, который добавляет к массивам NumPy метки строк и столбцов, превращая их в мощные аналитические таблицы.
Референсные ссылки
- [NumPy Official Documentation: The absolute basics for beginners] (https://numpy.org/doc/stable/user/absolute_beginners.html)
- [100 numpy exercises] (https://github.com/rougier/numpy-100)
- [From Python to Numpy (Nicolas P. Rougier)] (https://www.labri.fr/perso/nrougier/from-python-to-numpy/)