 270
270 
Содержание
Model Serving (Сервинг моделей) — это процесс интеграции обученной модели машинного обучения в программную среду для обработки реальных запросов. Это тот самый мост, который соединяет экспериментальный код Data Scientist’а с продакшн-системой бизнеса. Без надежного сервингa даже самая точная нейросеть останется лишь теоретическим экспериментом.
Главная сложность заключается в фундаментальном различии сред. Обучение моделей обычно происходит в статичной, контролируемой среде (например, Jupyter Notebook). Эксплуатация же требует работы в динамичных, высоконагруженных и часто непредсказуемых условиях. Сервинг решает задачу доставки прогнозов пользователю быстро, надежно и безопасно.
Основные паттерны инференса
Выбор архитектуры сервингa напрямую зависит от бизнес-требований к скорости ответа и объемам данных. В индустрии сложилось три основных подхода к организации инференса (получения предсказаний). Рассмотрим ключевые сценарии использования моделей в продакшене.
- Online Inference (Real-time). Клиент отправляет запрос и ожидает немедленного ответа. Это классический паттерн «Запрос-Ответ» (Request-Response). Критически важным показателем здесь является Latency (задержка). Примером служит система рекомендаций на сайте или детектор мошенничества при транзакции.
- Batch Inference (Пакетная обработка). Предсказания генерируются для большого набора данных периодически. Здесь важна не скорость ответа на один запрос, а Throughput (пропускная способность). Система может обрабатывать миллионы записей ночью, чтобы утром выдать отчет. Примером является скоринг клиентской базы банка для предложения кредитов.
- Streaming Inference. Обработка данных происходит по мере их поступления в непрерывном потоке. Модель подключается к шине событий (например, Apache Kafka). Это гибридный подход, требующий высокой пропускной способности и низкой задержки. Применяется в IoT-датчиках или анализе кликстрима пользователей.
Каждый из этих паттернов требует своего набора инструментов и инфраструктурных решений. Ошибка в выборе паттерна может привести к падению сервиса под нагрузкой или неоправданным затратам на облачные ресурсы.
Архитектура современного Model Serving
Превращение скрипта с моделью в микросервис требует внедрения нескольких архитектурных слоев. Нельзя просто запустить Python-скрипт на сервере и ожидать стабильной работы. Современный стандарт де-факто опирается на контейнеризацию и оркестрацию.
Типовая архитектура сервинг-системы включает следующие компоненты
- Model Registry (Реестр моделей). Это централизованное хранилище версий обученных моделей (например, MLflow или DVC). Оно гарантирует, что в продакшн попадет именно тот артефакт, который прошел тестирование.
- Контейнеризация (Docker). Модель упаковывается вместе со всеми зависимостями, библиотеками и драйверами. Это решает проблему «на моем компьютере работало», изолируя среду исполнения.
- Сервер инференса (Inference Server). Специализированное ПО, которое загружает модель в память и предоставляет API (REST или gRPC). Оно управляет потоками запросов и утилизацией ресурсов железа.
- API Gateway. Единая точка входа для внешних запросов. Гейтвей занимается маршрутизацией, аутентификацией и балансировкой нагрузки между репликами моделей.
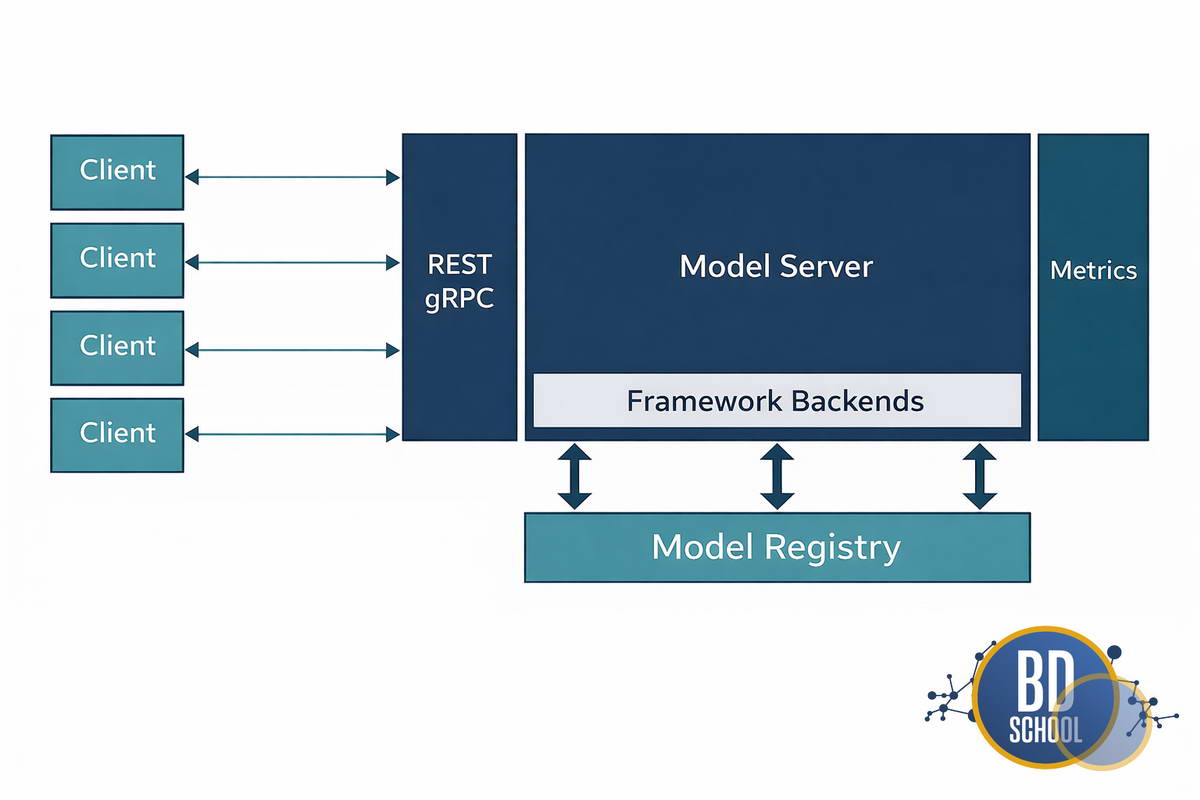
Такая слоистая структура обеспечивает гибкость и масштабируемость. Она позволяет обновлять модели без остановки сервиса (Zero Downtime Deployment) и проводить A/B тесты.
Разработка и внедрение ML-решений
Код курса
MLOPS
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
Обзор инструментов и решений для Model serving
Рынок инструментов для Model Serving огромен. Его можно условно разделить на три категории: от простых самописных решений до мощных промышленных комбайнов. Выбор инструмента зависит от нагрузки и стека технологий компании.
Разберем наиболее популярные категории инструментов
Микрофреймворки (DIY — Do It Yourself).
Использование Flask, FastAPI или Django. Data Scientist сам пишет обертку вокруг метода predict().
- Плюсы: Полный контроль над кодом, простота старта, отсутствие «черных ящиков».
- Минусы: Низкая производительность Python (GIL), сложность реализации батчинга и метрик.
Нативные серверы фреймворков.
Решения от создателей библиотек обучения.
- Примеры: TensorFlow Serving и TorchServe.
- Плюсы: Идеальная совместимость с «родным» форматом моделей, оптимизация под внутренние графы вычислений.
- Минусы: Сложная конфигурация, привязка к конкретному фреймворку (Vendor Lock-in).
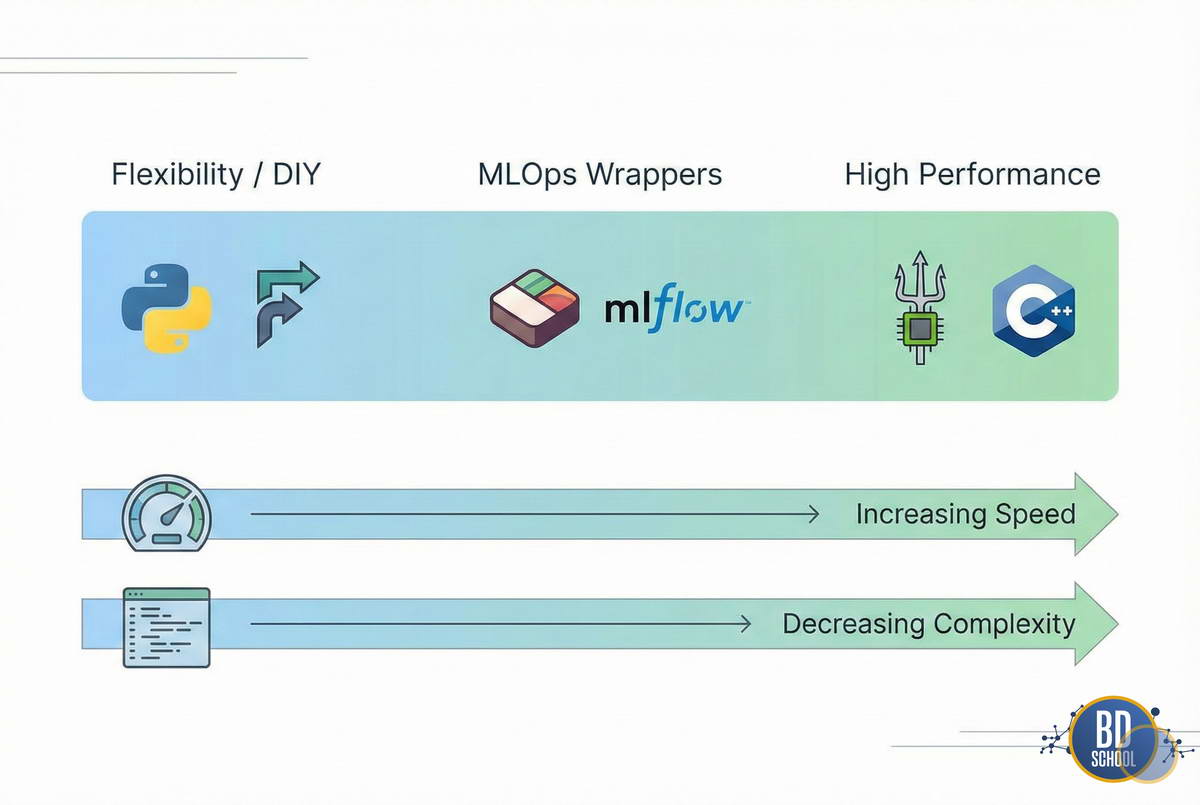
Универсальные Inference-серверы.
Лидером здесь является NVIDIA Triton Inference Server. Он поддерживает множество форматов (ONNX, PyTorch, TensorFlow, TensorRT).
- Плюсы: Экстремальная производительность на GPU, динамический батчинг, управление памятью.
- Минусы: Высокий порог входа, избыточность для простых задач.
MLOps-обертки и фреймворки.
Инструменты, упрощающие упаковку и деплой.
- Яркие представители: BentoML, Seldon Core, KServe.
- Плюсы: Стандартизация процесса, автоматическая генерация Docker-образов, интеграция с Kubernetes.
- Минусы: Дополнительная абстракция, которую нужно изучать.
Правильный выбор инструмента часто важнее самой архитектуры нейросети. Использование тяжелого Triton Server для простой линейной регрессии так же неэффективно, как использование Flask для высоконагруженного Computer Vision.
Сравнение FastAPI и Triton Inference Server
Часто возникает вопрос: зачем изучать сложные инструменты, если есть удобный FastAPI? Ведь Python-код пишется за 10 минут. Однако дьявол кроется в деталях производительности и конкурентности. Сравним эти два подхода в контексте высоконагруженных систем.
- Управление конкурентностью. FastAPI (и Python в целом) ограничен Global Interpreter Lock (GIL). Даже при использовании async/await, вычислительно тяжелые задачи (инференс) блокируют поток. Triton написан на C++. Он умеет выполнять модели параллельно на разных ядрах CPU или стримах GPU без блокировок.
- Динамический батчинг (Dynamic Batching). GPU любят большие матрицы. Обработка одного запроса на GPU неэффективна. Triton умеет «на лету» собирать одиночные запросы от пользователей в пачки (батчи). Он отправляет их на GPU скопом, а затем раздает ответы. Реализовать такую логику на чистом Python крайне сложно и чревато ошибками.
- Поддержка моделей. FastAPI требует загрузки модели в Python-процесс. Это потребляет много памяти. Triton может выгружать и загружать модели из памяти GPU по требованию. Это позволяет держать сотни моделей на одном сервере.
Если ваш сервис обрабатывает 5 запросов в секунду (RPS), FastAPI будет идеальным выбором. Но если нагрузка достигает тысяч RPS или требуется жесткий SLA по задержке, переход на C++ бэкенды (Triton) неизбежен.
Оптимизация производительности сервингa моделей
Просто запустить модель недостаточно. Для снижения затрат на инфраструктуру и ускорения ответов применяют техники оптимизации. Эти методы позволяют выжать максимум из доступного железа. Ключевые техники ускорения инференса включают.
- Квантование (Quantization).
Перевод весов модели из формата float32 (32 бита) в int8 (8 бит). Это уменьшает размер модели в 4 раза и ускоряет вычисления. Современные процессоры и GPU имеют специальные инструкции для работы с целочисленной арифметикой. Потеря точности при этом часто составляет менее 1%. - Дистилляция (Knowledge Distillation).
Обучение маленькой модели («ученика») повторять поведение большой модели («учителя»). В продакшн идет легкий «ученик», который работает значительно быстрее. - Конвертация в оптимизированные форматы.
Использование ONNX Runtime или TensorRT. Эти движки перестраивают граф вычислений модели. Они объединяют операции (operator fusion) и удаляют неиспользуемые узлы. Это дает прирост скорости от 20% до 500% по сравнению со стандартным PyTorch/TensorFlow. - Использование gRPC и Protobuf.
REST API передает данные в текстовом формате JSON. Это удобно для людей, но медленно для машин. Бинарный протокол gRPC (Google Remote Procedure Call) сжимает данные эффективнее. Это критично при передаче больших тензоров или изображений.
Оптимизация — это всегда компромисс между точностью, скоростью и сложностью разработки. Начинать стоит с конвертации в ONNX, так как это самый «дешевый» способ получить прирост производительности.
Практический пример: Сервинг моделей с BentoML
BentoML — это фреймворк, который объединяет простоту Python и мощь промышленных решений. Он позволяет описать сервис в несколько строк кода и автоматически упаковать его в Docker.
Рассмотрим пример создания сервиса для классификации изображений. Сначала мы сохраняем модель в локальное хранилище BentoML.
import bentoml
import torch
import torchvision
# Загружаем предобученную модель (например, ResNet)
model = torchvision.models.resnet50(pretrained=True)
model.eval()
# Сохраняем модель в формате BentoML
saved_model = bentoml.pytorch.save_model(
"resnet50_classifier",
model,
signatures={"__call__": {"batchable": True}}
)
print(f"Model saved: {saved_model}")
Затем создаем файл service.py, который описывает логику обработки
import bentoml
from bentoml.io import Image, JSON
# Получаем ссылку на сохраненную модель
runner = bentoml.pytorch.get("resnet50_classifier:latest").to_runner()
# Создаем сервис
svc = bentoml.Service("image_classifier", runners=[runner])
@svc.api(input=Image(), output=JSON())
async def classify(img):
# Препроцессинг: приводим картинку к нужному тензору
import torchvision.transforms as T
preprocess = T.Compose([T.Resize(256), T.CenterCrop(224), T.ToTensor()])
tensor = preprocess(img).unsqueeze(0)
# Асинхронный вызов раннера (поддерживает батчинг)
prediction = await runner.async_run(tensor)
return {"class_id": prediction.argmax().item()}
Этот код автоматически реализует микросервисную архитектуру. Флаг batchable=True включает динамический батчинг. Команда bentoml build создаст готовый Docker-образ, который можно деплоить в Kubernetes. Это избавляет инженера от написания сотен строк конфигураций Dockerfile и YAML.
Разработка и внедрение ML-решений
Код курса
MLOPS
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
Заключение
Model Serving перестал быть просто задачей «запуска скрипта». Это дисциплина, требующая понимания архитектуры, сетевых протоколов и особенностей железа.
Нет единственно верного инструмента для всех задач. Для MVP стартапа достаточно FastAPI. Для корпоративного Computer Vision нужен Triton или TensorRT. Для стандартизации ML-процессов в компании идеально подходят BentoML или KServe.
Главный совет: начинайте с простого. Не стройте сложную архитектуру на Kubernetes, пока ваша модель не приносит реальной пользы. Эволюционируйте сервинг моделей вместе с ростом нагрузки и требований бизнеса.
Референсные ссылки
- [Model Serving Patterns and Architecture] (https://martinfowler.com/articles/cd4ml.html)
- [NVIDIA Triton Inference Server Documentation] (https://developer.nvidia.com/triton-inference-server)
- [BentoML Documentation: Introduction] (https://docs.bentoml.org/en/latest/)
- [Serving ML Models: A Guide to Architecture] (https://christophergs.com/machine%20learning/2019/03/17/how-to-deploy-machine-learning-models/)