 365
365 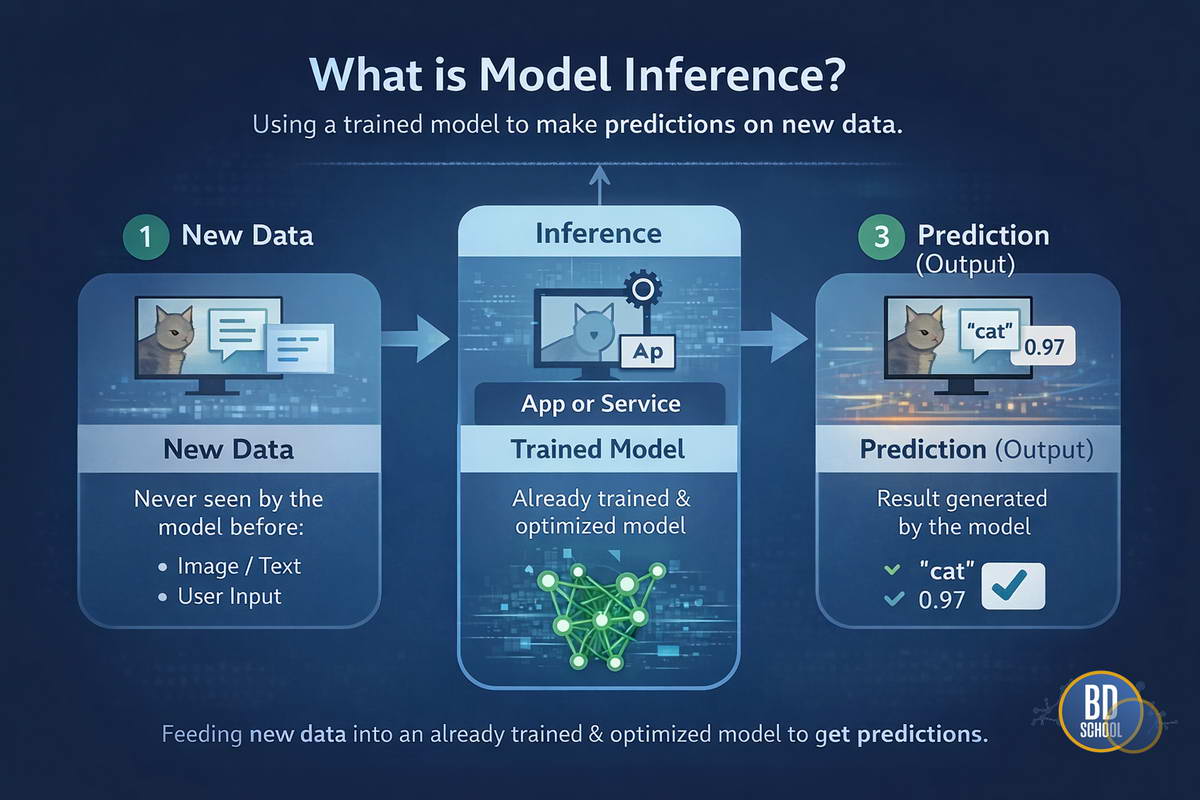
Содержание
- Обучение против Инференса: Фундаментальные различия
- Архитектурные режимы инференса
- Пакетный инференс (Batch Inference)
- Онлайн инференс (Online / Real-time Inference)
- Потоковый инференс (Streaming Inference)
- Edge Inference: Вычисления на периферии
- Оптимизация инференса
- Экосистема и инструменты
- Жизненный цикл и мониторинг инференса модели
- Стратегии развертывания (Deployment Strategies)
- Пример реализации: Простой API на FastAPI
- Этап 1: Обучение (train_model.py)
- Этап 2: Инференс на FastAPI (inference.py)
- Заключение
- Референсные ссылки
Model Inference (Инференс моделей или вывод моделей) — это процесс использования обученной нейронной сети или алгоритма машинного обучения для получения предсказаний на основе новых, ранее не известных данных. Это финальная стадия жизненного цикла ML-модели, когда абстрактная математическая структура начинает приносить реальную пользу бизнесу или пользователю. Без инференса любая, даже самая точная модель, остается лишь набором весов на жестком диске.
Разработка и внедрение ML-решений
Код курса
MLOPS
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
Обучение против Инференса: Фундаментальные различия
Чтобы глубоко понять суть инференса, необходимо четко разграничить его с процессом обучения. Многие новички путают эти понятия, так как оба они используют одни и те же архитектуры нейросетей. Однако их цели, математические операции и требования к вычислительным ресурсам диаметрально противоположны.
Процесс обучения можно сравнить с получением образования в университете. Это долго, ресурсоемко и требует обработки огромных объемов информации для формирования знаний. Инференс же похож на работу профессионала по специальности. Специалист применяет полученные знания для решения конкретных задач в реальном времени, стараясь делать это максимально быстро и эффективно.
Основные различия проявляются в следующих аспектах:
- Цель процесса: Обучение стремится минимизировать функцию потерь и найти оптимальные веса. Инференс использует эти зафиксированные веса для генерации ответов.
- Вычислительная нагрузка: При обучении выполняются проходы вперед (forward pass) и назад (backward propagation). Инференс требует только прямого прохода, что значительно снижает количество операций.
- Потребление памяти: Обучение требует хранения градиентов и промежуточных состояний для каждого слоя. Инференс может работать с оптимизированными структурами, занимая в разы меньше оперативной памяти.
Таким образом, инференс — это эксплуатация модели. Если обучение может длиться недели на кластерах суперкомпьютеров, то инференс часто должен происходить за миллисекунды на обычном процессоре или даже смартфоне.
Архитектурные режимы инференса
Выбор способа реализации инференса зависит от бизнес-требований к скорости ответа и объема данных. Не существует универсального решения, подходящего для всех задач. Архитекторы систем обычно выбирают один из трех основных подходов, либо комбинируют их.
Ниже мы подробно разберем ключевые режимы работы моделей в продакшене.
Пакетный инференс (Batch Inference)
Этот режим используется, когда мгновенный ответ не требуется. Данные накапливаются в хранилище, а затем обрабатываются большими группами (батчами) по расписанию. Это классический подход для аналитических задач, генерации отчетов или маркетинговых рассылок.
Особенности пакетного режима включают:
- Высокая пропускная способность (Throughput): Система обрабатывает миллионы записей за один запуск.
- Эффективность железа: Процессоры и видеокарты работают со 100% загрузкой, не простаивая в ожидании запросов.
- Задержка (Latency) не критична: Результат может быть готов через часы или дни.
Примером может служить система рекомендаций видеосервиса. Она пересчитывает персональные подборки для всех пользователей каждую ночь. Утром пользователь видит обновленный список фильмов, даже если расчет занял 4 часа.
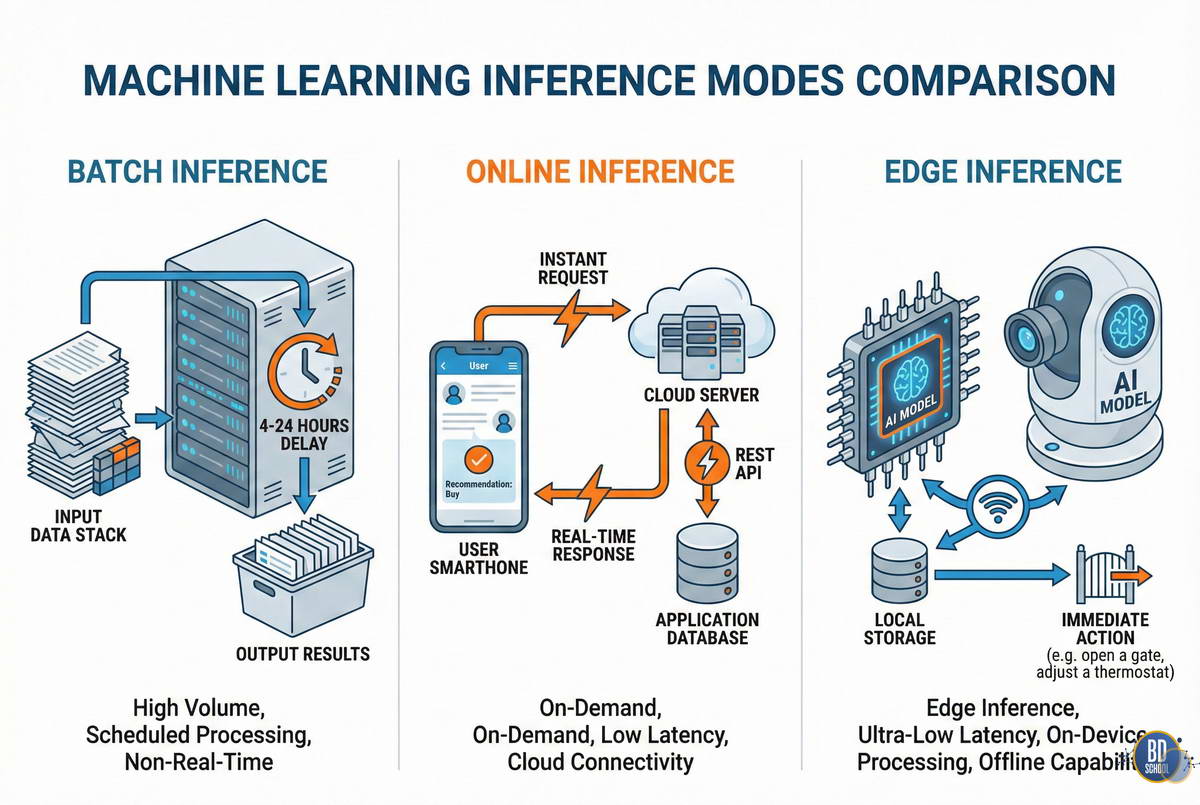
Онлайн инференс (Online / Real-time Inference)
Здесь модель работает как веб-сервис. Пользователь или другая система отправляет запрос и ожидает мгновенного ответа. Это самый распространенный сценарий для интерактивных приложений, чат-ботов и систем обнаружения мошенничества при транзакциях.
Ключевые характеристики онлайн-режима:
- Низкая задержка (Low Latency): Это главный KPI. Ответ должен прийти за 50–200 миллисекунд.
- Проблема «холодного старта»: Модель должна быть постоянно загружена в память, даже если запросов нет.
- Масштабируемость: Система должна уметь автоматически добавлять серверы при резком наплыве пользователей.
В этом сценарии модель обычно оборачивается в REST API или gRPC сервис. Она принимает JSON с данными, проводит расчет и возвращает JSON с предсказанием.
Потоковый инференс (Streaming Inference)
Этот режим похож на онлайн-инференс, но работает с непрерывным потоком событий. Он часто реализуется через шины данных, такие как Apache Kafka или RabbitMQ. Модель «слушает» поток и реагирует на каждое сообщение асинхронно.
Преимущества потокового подхода:
- Асинхронность: Отправитель не ждет ответа, что разгружает клиентское приложение.
- Устойчивость: Если сервис инференса упадет, сообщения сохранятся в очереди и будут обработаны позже.
- Сглаживание пиков: Очередь выступает буфером при резких скачках нагрузки.
Такой подход идеален для систем интернета вещей (IoT). Тысячи датчиков шлют данные непрерывно, и модель обрабатывает их по мере поступления.
Edge Inference: Вычисления на периферии
Отдельного внимания заслуживает тренд переноса инференса с облачных серверов непосредственно на устройства пользователей. Это называется Edge AI или периферийные вычисления. Модели запускаются на смартфонах, камерах видеонаблюдения, умных колонках или промышленных контроллерах.
Перенос вычислений на устройство решает несколько критических проблем.
- Во-первых, это конфиденциальность. Данные (например, фото лица или голос) не покидают устройство пользователя, что снижает риски утечек.
- Во-вторых, это независимость от сети. Автопилот автомобиля или медицинский прибор должны работать, даже если интернет пропал.
- В-третьих, это экономия трафика и денег. Пересылка терабайтов видео с камер в облако стоит дорого, выгоднее обрабатывать поток на месте и отправлять только метаданные.
Однако Edge Inference накладывает жесткие ограничения на размер и сложность моделей. Мобильный процессор не потянет огромную нейросеть, поэтому здесь критически важны методы оптимизации.
Оптимизация инференса
В реальном мире ресурсы всегда ограничены. Запуск «сырой» модели после обучения часто бывает слишком дорогим или медленным. Инженеры используют специальные техники для сжатия и ускорения моделей без существенной потери точности.
Основные методы оптимизации включают:
- Квантование (Quantization): При обучении веса модели обычно хранятся в формате 32-битных чисел с плавающей точкой (FP32). Квантование переводит их в более компактные форматы, например, в 16-битные (FP16) или даже 8-битные целые числа (INT8). Это уменьшает размер модели в 2-4 раза и значительно ускоряет вычисления на современном железе, поддерживающем векторные инструкции.
- Прунинг (Pruning): Этот метод заключается в удалении «лишних» связей в нейросети. Исследования показывают, что многие нейроны имеют веса, близкие к нулю, и почти не влияют на результат. Прунинг обрезает эти связи, делая сеть разреженной (sparse). Это снижает количество вычислений и экономит память.
- Дистилляция знаний (Knowledge Distillation): Мы берем огромную, точную «модель-учителя» и обучаем маленькую «модель-ученика» повторять её поведение. Ученик получается компактным и быстрым, но сохраняет большую часть знаний учителя. Это популярный способ создания моделей для мобильных устройств.
- Слияние операторов (Operator Fusion): Фреймворки инференса анализируют граф вычислений и объединяют несколько математических операций в одну. Например, умножение матрицы и функцию активации можно выполнить за один проход по памяти. Это снижает накладные расходы на обращение к оперативной памяти.
Использование этих методов позволяет ускорить инференс в десятки раз.
Экосистема и инструменты
Для промышленного запуска моделей недостаточно простого Python-скрипта. Существует класс специализированного ПО, называемого Model Serving Solutions. Эти инструменты обеспечивают версионирование, мониторинг и эффективное управление ресурсами.
Наиболее популярные решения на рынке:
- TensorFlow Serving: Стандарт де-факто для моделей TensorFlow. Высокопроизводительный сервер от Google, написанный на C++. Поддерживает горячую замену моделей без остановки сервиса.
- TorchServe: Аналогичное решение для экосистемы PyTorch, разработанное AWS и Facebook. Позволяет легко разворачивать модели PyTorch в продакшене.
- Triton Inference Server: Мощный сервер от NVIDIA. Он универсален и поддерживает любые фреймворки (TensorFlow, PyTorch, ONNX). Умеет эффективно распределять нагрузку между CPU и GPU.
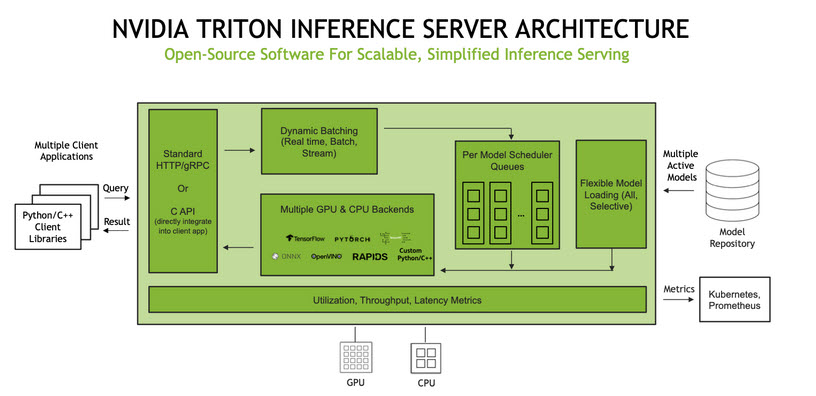
- ONNX Runtime: Кроссплатформенный движок для запуска моделей в формате ONNX. Он работает быстрее стандартных фреймворков и позволяет запускать одну и ту же модель на разном железе, от серверов до браузеров.
Выбор инструмента зависит от стека компании и требований к производительности.
Разработка и внедрение ML-решений
Код курса
MLOPS
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
Жизненный цикл и мониторинг инференса модели
Инференс — это не разовое действие, а процесс, требующий постоянного наблюдения. После деплоя работа инженера не заканчивается. Модели имеют свойство «деградировать» со временем, даже если код не менялся.
В продакшене необходимо отслеживать следующие метрики:
- Технические метрики: Latency (задержка ответа), Throughput (количество запросов в секунду), потребление CPU/GPU и памяти, количество ошибок (5xx коды).
- Data Drift (Дрейф данных): Ситуация, когда распределение входных данных меняется. Например, модель обучали на летних фото, а зимой она перестает узнавать людей в шапках.
- Concept Drift (Дрейф концепции): Ситуация, когда меняется сама зависимость между данными и целевой переменной. Например, модель скоринга кредитов может устареть из-за изменения экономической ситуации в стране.
Для борьбы с дрейфом настраивают системы мониторинга (Prometheus, Grafana, Evidently AI). При обнаружении отклонений модель отправляют на дообучение (retraining) на свежих данных.
Стратегии развертывания (Deployment Strategies)
Выкатывать новую версию модели сразу на 100% пользователей рискованно. Если новая модель окажется хуже старой, бизнес понесет убытки. Поэтому в инференсе применяют безопасные стратегии обновления.
Основные стратегии включают:
- Shadow Deployment (Теневое развертывание): Новая модель запускается параллельно со старой. Она получает реальные запросы, делает предсказания, но ее ответы не показываются пользователю. Инженеры сравнивают результаты старой и новой модели. Это самый безопасный способ проверки.
- Canary Deployment (Канареечный релиз): Новую модель включают только для маленькой части пользователей (например, 1% или 5%). Если метрики в норме, трафик постепенно переключают на новую версию.
- A/B тестирование: Трафик делится пополам между старой и новой моделью. Это позволяет статистически достоверно сравнить бизнес-метрики (например, конверсию или кликабельность) и выбрать победителя.
Грамотная стратегия деплоя страхует от фатальных ошибок.
Пример реализации: Простой API на FastAPI
Рассмотрим, как выглядит простейший микросервис для инференса. Мы будем использовать библиотеку FastAPI, так как она быстрая, современная и автоматически генерирует документацию. В реальных проектах код будет сложнее, но структура остается похожей.
Разберем полный цикл на Python. Чтобы сервис заработал, нам нужно два этапа:
-
Обучение: Создать модель и сохранить её в файл.
-
Инференс: Загрузить этот файл и отвечать на запросы.
Этап 1: Обучение (train_model.py)
#--- Предварительно установите библиотеки в venv среде python3 -m venv venv/ source venv/bin/activate pip3 install scikit-learn fastapi uvicorn joblib pandas
Сначала создадим «мозги» нашей системы. Обучим простую логистическую регрессию на классическом датасете ирисов и сохраним её.
import joblib
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
# 1. Загружаем данные
iris = load_iris()
X, y = iris.data, iris.target
# 2. Обучаем модель
print("Начинаю обучение...")
model = LogisticRegression(max_iter=200)
model.fit(X, y)
# 3. Сохраняем (сериализуем) модель в файл
joblib.dump(model, "iris_model.pkl")
print("Готово! Файл 'iris_model.pkl' создан.")
Для запуска скрипта просто выполните команду python3 train_model.py
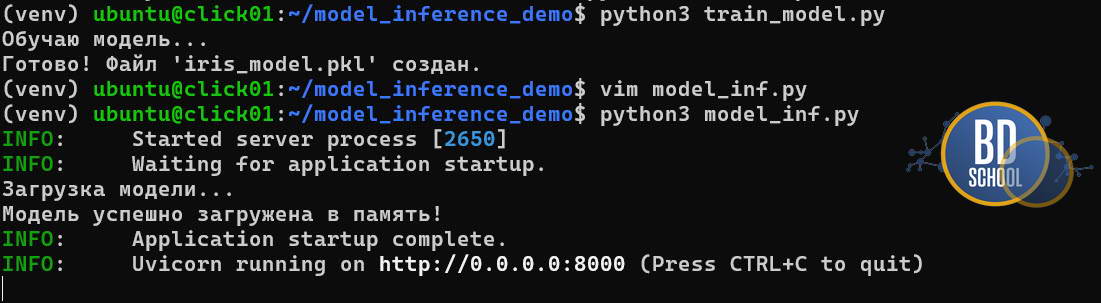
Этап 2: Инференс на FastAPI (inference.py)
Теперь напишем веб-сервис. Мы используем современный механизм lifespan для загрузки модели. Это критически важно: модель загружается в память один раз при старте сервера, а не при каждом запросе пользователя.
import uvicorn
from fastapi import FastAPI
from contextlib import asynccontextmanager
from pydantic import BaseModel
import joblib
import pandas as pd
# Импорт sklearn нужен, чтобы joblib правильно восстановил объект
import sklearn
# Глобальное хранилище для модели
ml_models = {}
# Логика жизненного цикла приложения
@asynccontextmanager
async def lifespan(app: FastAPI):
# Код до yield выполняется при запуске
try:
ml_models["iris"] = joblib.load("iris_model.pkl")
print("✅ Модель успешно загружена в память")
except FileNotFoundError:
print("❌ Ошибка: Файл модели не найден. Сначала запустите train_model.py")
ml_models["iris"] = None
yield # Здесь работает приложение
# Код после yield выполняется при выключении
ml_models.clear()
print("🛑 Память очищена")
app = FastAPI(lifespan=lifespan)
# Описание формата входных данных
class IrisFeatures(BaseModel):
sepal_length: float
sepal_width: float
petal_length: float
petal_width: float
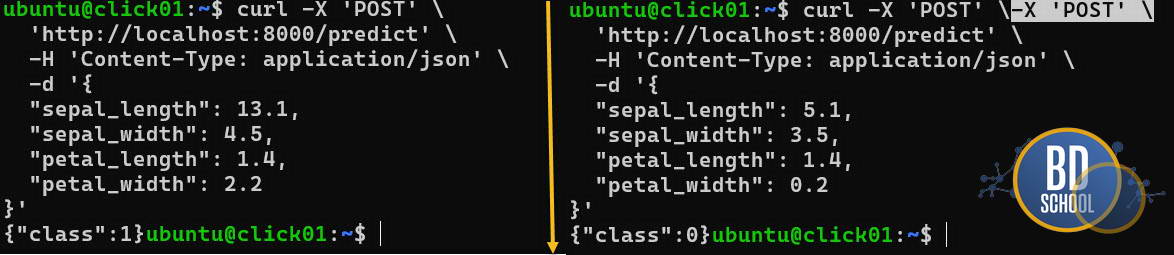
@app.post("/predict")
def predict(features: IrisFeatures):
if not ml_models["iris"]:
return {"error": "Model is not loaded properly"}
# Преобразуем JSON в DataFrame (как при обучении)
data = pd.DataFrame([features.dict().values()])
# Сам инференс (предсказание)
prediction = ml_models["iris"].predict(data)
return {"class_id": int(prediction[0])}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
Этот код создает полноценный веб-сервер. Он принимает HTTP-запросы, передает данные модели и возвращает результат.
Заключение
Инференс моделей — это технологический мост между Data Science и реальным миром. Именно на этом этапе алгоритмы начинают приносить прибыль, оптимизировать процессы и улучшать пользовательский опыт.
Понимание нюансов инференса отличает зрелого специалиста от новичка. Важно не просто уметь обучить модель с высокой точностью, но и знать, как встроить её в существующую инфраструктуру, сделать быстрой, дешевой и надежной. Будущее за оптимизированными моделями, периферийными вычислениями и автоматизированными пайплайнами доставки ML-решений.
Референсные ссылки
- [Machine Learning Inference Explained] (https://aws.amazon.com/what-is/machine-learning-inference/)
- [NVIDIA Triton Inference Server Documentation] (https://developer.nvidia.com/triton-inference-server)
- [TensorFlow Serving Architecture] (https://www.tensorflow.org/tfx/guide/serving)
- [Concept Drift in Machine Learning] (https://evidentlyai.com/blog/machine-learning-monitoring-concept-drift)