 544
544 
Содержание
- Ключевые типы Дрейфа Модели: Concept Drift против Data Drift
- Concept Drift (Дрейф Концепции)
- Data Drift (Дрейф Данных)
- Почему возникает Model Drift: Основные причины
- Как обнаружить Model Drift: Симптомы и мониторинг
- Реактивный подход: Мониторинг метрик
- Проактивный подход: Мониторинг распределений
- Методы борьбы с Model Drift
- Model Drift как центральная задача MLOps
- Практический пример: Дрейф в модели кредитного скоринга
- Заключение
- Референсные ссылки
Model Drift (Дрейф Модели) — это неизбежный процесс снижения производительности и точности модели машинного обучения с течением времени. Это происходит, когда статистические свойства данных, на которых модель работает в реальном мире, начинают отличаться от данных, на которых она изначально обучалась.
Проще говоря, Model Drift — это «старение» модели. Мир вокруг постоянно меняется, а модель, обученная на данных из прошлого, перестает эти изменения понимать.
Представьте, что ваша модель — это навигатор с картами 2020 года. В 2020 году он был идеален. Но в 2025 он не знает о новых дорогах, развязках и измененном одностороннем движении. Навигатор все еще работает, но его «предсказания» (маршруты) становятся все менее точными и полезными. Это и есть Model Drift.
Ключевые типы Дрейфа Модели: Concept Drift против Data Drift
Крайне важно понимать, почему модель начала ошибаться. Model Drift — это общий термин, но он делится на два фундаментально разных типа. Их часто путают, однако причины и способы борьбы с ними различаются.
Concept Drift (Дрейф Концепции)
Concept Drift (Дрейф Концепции) происходит, когда меняются сами «правила игры». Это изменение в отношениях между входными данными (признаками) и тем, что мы пытаемся предсказать (целевой переменной).
- Что это значит: Данные могут выглядеть так же, но их значение или «концепция» изменились.
- Пример: Модель предсказывает, нажмет ли пользователь на рекламу. Раньше синий цвет кнопки давал высокую конверсию. Но из-за нового тренда в дизайне пользователи стали считать синие кнопки «старомодными» и перестали на них нажимать. Признак (цвет_кнопки = синий) остался тем же, но его связь с результатом (нажатие = да) изменилась.
Concept Drift обнаружить сложнее, так как он часто требует анализа «земной правды» (ground truth), то есть реальных размеченных результатов.
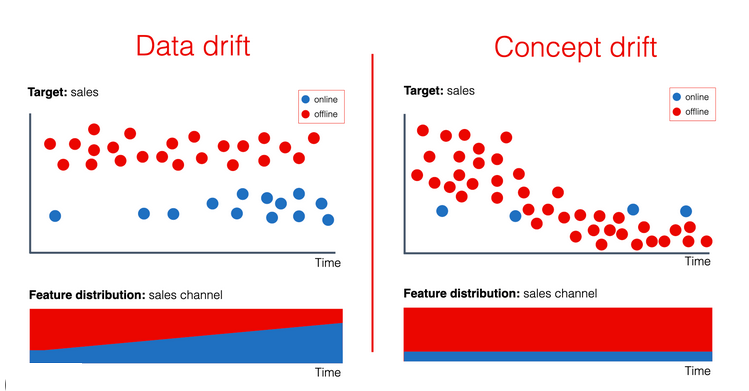
Data Drift (Дрейф Данных)
Data Drift (Дрейф Данных) происходит, когда «правила игры» остаются теми же, но к нам на вход начинают поступать совершенно другие данные. Меняется само статистическое распределение входных признаков.
- Что это значит: Модель просто «не видела» таких данных раньше и не знает, что с ними делать.
- Пример: Модель оценки недвижимости обучалась на данных о квартирах площадью 40-100 кв. метров. Внезапно на рынок вышли новые «микро-студии» по 15 кв. метров. Модель все еще пытается применить старые правила (связь площади и цены), но входные данные (площадь = 15) находятся далеко за пределами того, что она «понимает».
Data Drift обычно обнаружить легче, так как для этого достаточно сравнивать статистику новых входных данных со статистикой данных, на которых модель обучалась.
Разработка и внедрение ML-решений
Код курса
MLOPS
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
Почему возникает Model Drift: Основные причины
Model Drift не происходит в вакууме. Он всегда является следствием изменений в реальном мире, которые не были учтены при обучении.
Вот основные катализаторы этого процесса:
- Изменения во внешнем мире. Это самые частые и мощные факторы. Экономические кризисы, пандемии, новые законы или даже смена времен года (сезонность) могут полностью изменить поведение пользователей и сделать старые паттерны бесполезными.
- Изменения в поведении пользователей. Пользователи адаптируются к вашей системе. Они могут научиться «обманывать» антифрод-систему или просто менять свои предпочтения из-за новых трендов.
- Проблемы с источниками данных. Это техническая, но очень частая причина. Датчик на производстве может начать сбоить и присылать «шум». Внешний API, поставляющий вам курсы валют, может изменить формат данных. Для модели это выглядит как внезапный Data Drift.
Как обнаружить Model Drift: Симптомы и мониторинг
«Поймать» дрейф до того, как он нанесет ущерб бизнесу, — ключевая задача. Существует два основных подхода к обнаружению.
Реактивный подход: Мониторинг метрик
Это самый очевидный способ. Мы просто следим за ключевыми метриками производительности модели (такими как Accuracy, F1-score, RMSE и т.д.).
Как только мы видим, что метрики в production начали падать, — мы обнаружили дрейф.
Проблема этого подхода в том, что он «реактивный». Мы узнаем о проблеме только после того, как модель уже начала принимать неверные решения и, возможно, принесла убытки.
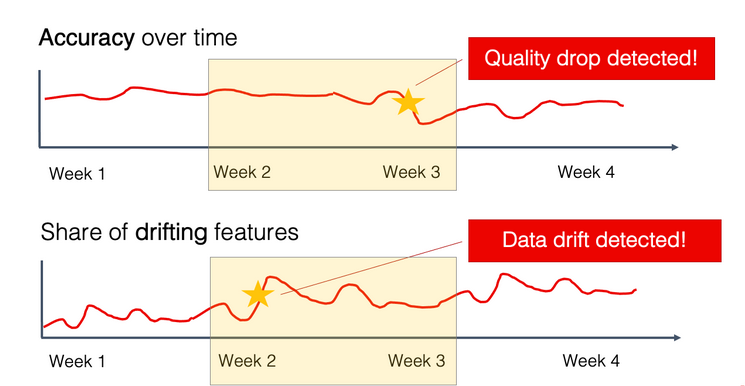
Проактивный подход: Мониторинг распределений
Это более продвинутый метод. Мы не ждем падения итоговых метрик. Вместо этого мы постоянно сравниваем статистические распределения «свежих» входных данных с «эталонными» данными, на которых модель училась.
Для этого используются статистические тесты и метрики:
- Population Stability Index (PSI). Один из самых популярных тестов для измерения скорости изменения распределения.
- Тест Колмогорова-Смирнова. Позволяет проверить, принадлежат ли две выборки (например, старые данные и новые) одному распределению.
- Расстояние Кульбака-Лейблера (KL Divergence). Показывает, насколько сильно одно распределение отличается от другого.
Этот подход позволяет нам заметить Data Drift еще до того, как он приведет к падению точности (то есть до Concept Drift).
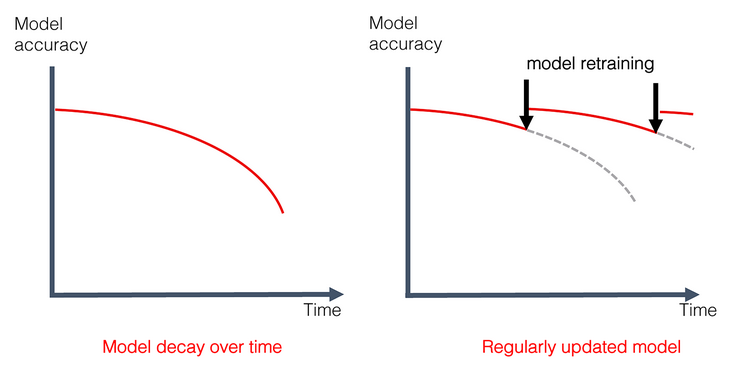
Методы борьбы с Model Drift
Обнаружить дрейф — это половина дела. Вторая половина — правильно на него отреагировать.
Существует несколько основных стратегий для борьбы с «состарившимися» моделями:
- Регулярное переобучение (Retraining). Это самый распространенный метод. Мы просто берем свежие, актуальные данные и обучаем на них нашу модель заново. Главный вопрос здесь — как часто? Раз в день, раз в неделю или раз в квартал? Это зависит от того, как быстро меняется ваша среда.
- Онлайн-обучение (Online Learning). Этот подход используется в системах, где данные меняются с огромной скоростью (например, в биржевом трейдинге или рекомендациях в реальном времени). Модель «дообучается» на каждом новом примере или небольшой пачке данных, постоянно адаптируясь к изменениям.
- Создание более устойчивых моделей (Robust Models). Иногда можно заранее спроектировать модель так, чтобы она была менее чувствительна к небольшим изменениям. Например, использовать меньше признаков, которые могут быстро «протухнуть», или применять техники регуляризации.
Model Drift как центральная задача MLOps
Вся современная дисциплина MLOps (Machine Learning Operations) во многом построена вокруг идеи борьбы с дрейфом.
Раньше жизненный цикл модели выглядел так: «обучил -> развернул -> забыл». Model Drift доказал, что этот подход не работает.
Современный MLOps-подход — это CI/CD/CT (Continuous Integration / Continuous Delivery / Continuous Training). «Непрерывное Обучение» (CT) признает, что развертывание модели — это не конец, а только начало ее жизненного цикла. Система должна быть построена как конвейер, который постоянно мониторит данные, обнаруживает дрейф и автоматически запускает процесс переобучения.
ИИ-агенты для оптимизации бизнес-процессов
Код курса
AGENT
Ближайшая дата курса
18 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
Практический пример: Дрейф в модели кредитного скоринга
Давайте рассмотрим очень наглядный пример.
- Модель: Банк обучает модель кредитного скоринга для одобрения заявок.
- Обучение: Модель обучается на данных с 2015 по 2019 год. Она «выучила», что стабильная работа в офисе и частые поездки за границу — это признаки надежного заемщика.
- Событие: В 2020 году наступает пандемия и экономический кризис.
- Data Drift (Дрейф Данных): В банк резко пошли заявки от людей, которые раньше никогда не брали кредиты. Распределение «типичного» клиента изменилось. Признак «поездки за границу» у всех стал равен нулю.
- Concept Drift (Дрейф Концепции): Сами «правила» надежности изменились. Работа в офисе перестала быть гарантией стабильности (многие попали под сокращение), а курьеры (раньше «ненадежный» сегмент) стали одними из самых стабильных работников.
Итог: Модель, обученная на данных «старого мира», становится абсолютно бесполезной в новой реальности. Она будет массово отказывать надежным заемщикам и одобрять кредиты рискованным. Единственный выход — полный сбор новых данных и переобучение.
Заключение
Model Drift (Дрейф Модели) — это не ошибка аналитика и не баг в коде. Это фундаментальное свойство реального мира, который всегда будет меняться быстрее, чем наши модели.Ключ к успешному внедрению машинного обучения в production — это принять дрейф как данность. Модель — это не «статуя», которую высекли из камня один раз и на века. Модель — это «живой организм», который требует постоянного ухода, мониторинга и адаптации. Построение систем для этого мониторинга и автоматического обновления и есть главная задача MLOps.
Референсные ссылки
- Что такое Model Drift? (https://research.aimultiple.com/model-drift/)
- Оценка дрейфа данных (https://docs.aws.amazon.com/wellarchitected/latest/machine-learning-lens/mlper-14.html)
- Data Drift vs. Concept Drift: В чем разница? (https://www.dataversity.net/articles/data-drift-vs-concept-drift-what-is-the-difference/)
- Мониторинг ML-моделей в BigQuery (https://cloud.google.com/blog/products/data-analytics/monitor-ml-model-skew-and-drift-in-bigquery)
- Дрейф данных — не настоящая проблема (https://towardsdatascience.com/data-drift-is-not-the-actual-problem-your-monitoring-strategy-is/)