 601
601 
Содержание
- Ключевые компоненты архитектуры MoE
- Эксперты (The Experts)
- Шлюзовая сеть (The Gating Network / Router)
- Принцип работы: "Разреженная активация" (Sparse MoE)
- Преимущества и главные вызовы MoE
- Преимущества
- Вызовы и компромиссы
- MoE в реальном мире: Mixtral, GPT-4 и Google
- MoE ("Разреженные") vs. "Плотные" (Dense) модели
- Заключение
- Референсные ссылки
Mixture of Experts (MoE) — это архитектура нейросети, где несколько специализированных моделей-экспертов работают параллельно, но для каждого запроса активируется только часть из них. Это позволяет создавать огромные модели с относительно небольшими вычислительными затратами. Эта архитектура является одним из ключевых «чит-кодов» современного искусственного интеллекта. Она решает фундаментальный парадокс: как создавать модели с триллионами параметров («знаний»), которые при этом отвечают быстро и не требуют для каждого ответа гигантских вычислительных мощностей.
Чтобы понять эту идею, проще всего использовать аналогию.
- Обычная («плотная») модель (Dense Model): Представьте ее как одного гениального профессора-всезнайку. Вы можете задать ему любой вопрос — по квантовой физике, истории средневековой поэзии или о том, как написать Python-скрипт. Чтобы ответить, профессору приходится «напрячь» всю свою память и все свои знания (все параметры модели). Это очень эффективно с точки зрения «знаний», но очень медленно и энергозатратно для каждого отдельного вопроса.
- MoE-модель (Mixture of Experts): А это — целая «академия» узких специалистов. Здесь есть профессор по физике, профессор по истории, программист, лингвист и так далее. Когда вы задаете вопрос, на входе вас встречает «диспетчер» (Шлюзовая сеть). Он смотрит на ваш вопрос (токен) и мгновенно решает: «Так, это похоже на код и немного на математику. Отправляю запрос к эксперту №3 (программист) и эксперту №7 (математик)».
В этот самый момент все остальные профессора — по истории, поэзии, лингвистике — «отдыхают» и не тратят никаких ресурсов. Ответ формируется только силами двух экспертов. Таким образом, у вас есть «знания» всей академии (огромное общее число параметров), но стоимость каждого ответа очень низкая — как если бы у вас была маленькая модель, состоящая всего из двух специалистов.
Ключевые компоненты архитектуры MoE
Архитектура Mixture of Experts состоит из двух главных компонентов, которые работают в паре. В контексте современных LLM (Large Language Models), таких как Transformer, MoE обычно заменяет стандартный блок Feed-Forward Network (FFN).
Эксперты (The Experts)
Это «мускулы» системы. Каждый «эксперт» — это, по сути, независимая нейросеть со своим собственным набором весов (параметров). В архитектуре Transformer каждый эксперт является стандартным блоком Feed-Forward Network (FFN).
Важно понимать, что каждый эксперт обучается специализироваться. В процессе обучения один эксперт может стать «сильнее» в анализе и написании кода, другой — в следовании инструкциям на естественном языке, третий — в распознавании паттернов в научных текстах. Они не разделены по темам жестко, но такая специализация возникает естественным образом.
Шлюзовая сеть (The Gating Network / Router)
Это «мозг» и «диспетчер» системы. Шлюзовая сеть — это тоже очень маленькая, но критически важная нейросеть. Ее единственная задача — посмотреть на входящий токен (единицу данных, например, слово или часть слова) и принять два решения:
- К каким экспертам отправить этот токен?
- С каким «весом» учесть мнение каждого из них?
Шлюз вычисляет «оценку» для каждого эксперта. Затем он выбирает, например, двух лучших (Top-K, где K=2) и говорит: «Ты, эксперт №3, твое мнение важно на 60%. А ты, эксперт №7, твое — на 40%». Таким образом, шлюз динамически решает, чья «экспертиза» наиболее релевантна для обработки именно этого токена.
Принцип работы: «Разреженная активация» (Sparse MoE)
Вся магия MoE заключается в концепции «разреженной активации» (Sparse Activation). Это то, что отличает ее от «плотных» (Dense) моделей. Вот пошаговый процесс обработки каждого токена в MoE-модели:
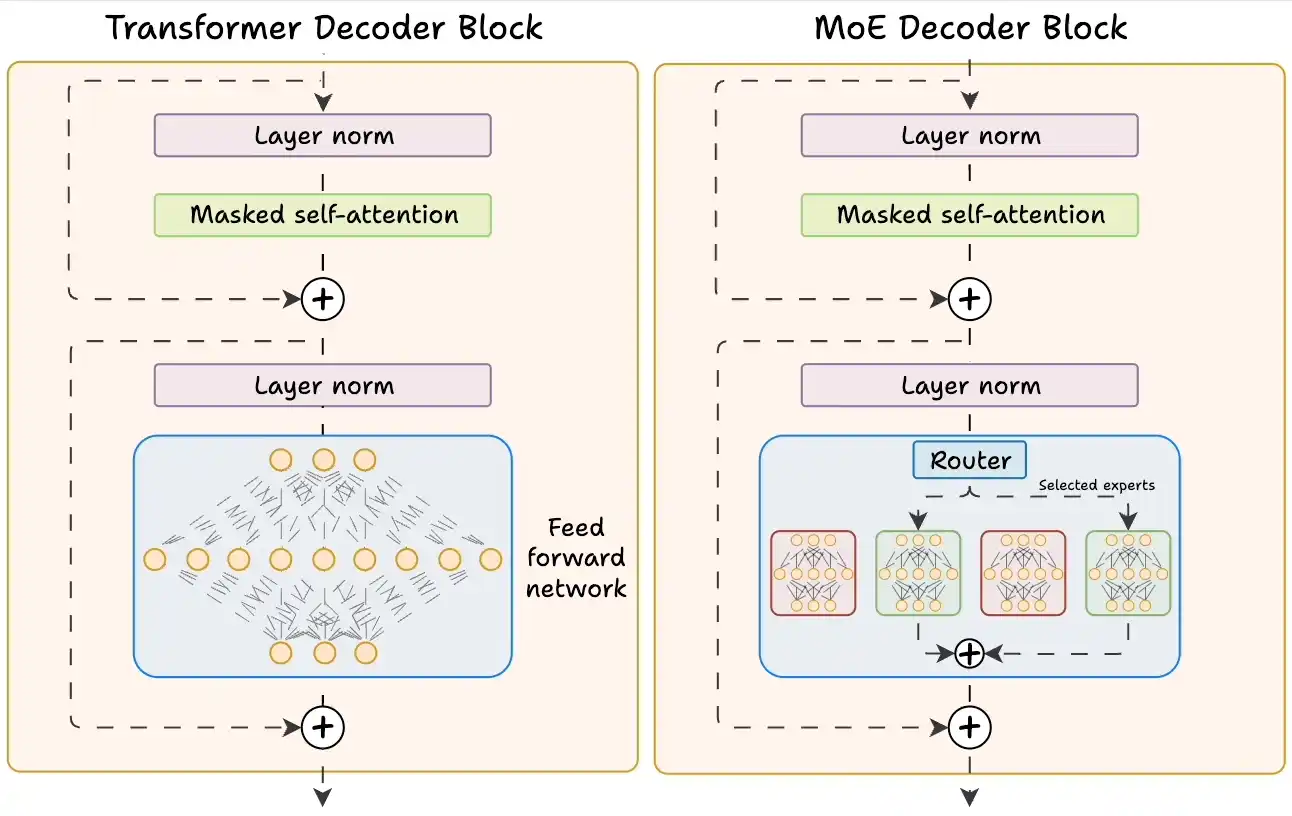
- Маршрутизация (Routing): Токен (например, слово import в коде) поступает на вход MoE-слоя. Он немедленно передается в Шлюзовую сеть (Router).
- Выбор (Selection): Шлюз вычисляет оценки для всех доступных экспертов (например, для 8 экспертов). Он видит, что эксперт №3 (специалист по коду) получает оценку 0.6, а эксперт №1 (общие знания) — 0.4. Остальные получают почти нулевые оценки.
- Обработка (Processing): Шлюз выбирает «Top-K» (обычно K=2) экспертов. В нашем случае это эксперты №3 и №1. Токен копируется и отправляется на обработку только этим двум экспертам. Важно, что это происходит параллельно.
- Смешивание (Mixing): Результаты (выходные векторы) от эксперта №3 и эксперта №1 возвращаются. Шлюз «смешивает» их в соответствии с назначенными весами: (Результат_3 * 0.6) + (Результат_1 * 0.4).
Полученный смешанный вектор и является итоговым выходом MoE-слоя для этого токена. В этот момент 6 из 8 экспертов вообще не выполняли никаких вычислений. Именно поэтому модель называется «разреженной»: для каждого токена активируется лишь малая, разреженная часть от общего числа параметров.
Преимущества и главные вызовы MoE
Архитектура Mixture of Experts предлагает революционные преимущества, но за них приходится платить свою цену.
ML Практикум: от теории к промышленному использованию
Код курса
PYML
Ближайшая дата курса
30 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
Преимущества
- Масштабирование параметров: MoE позволяет «наращивать» общее число параметров модели до триллионов. Больше параметров, как правило, означает больше «знаний», лучшее понимание нюансов и более высокое качество ответов.
- Вычислительная эффективность (FLOPS): Это главный плюс. Несмотря на гигантское общее число параметров, количество вычислений (FLOPS) для обработки одного токена остается постоянным и низким. Оно равно стоимости небольшой модели, состоящей только из k активированных экспертов. Это позволяет моделям-гигантам работать (проводить инференс) очень быстро.
Вызовы и компромиссы
- Требования к VRAM (Памяти): Это главный компромисс MoE. Во время работы (инференса) вы можете использовать только 2 эксперта из 8. Однако все 8 экспертов должны быть загружены в видеопамять (VRAM) вашего GPU. Они должны быть «наготове». Таким образом, MoE-модели экономят на вычислениях (FLOPS), но «пожирают» память (VRAM).
- Балансировка нагрузки (Load Balancing): При обучении возникает очевидная проблема: что, если Шлюзовая сеть «полюбит» одного-двух экспертов и будет отправлять все токены только им? Эти эксперты станут перегружены, а остальные — «ленивыми» и бесполезными. Чтобы решить эту проблему, вводится специальный «штраф» (auxiliary loss). Он заставляет Шлюз распределять токены как можно более равномерно по всем экспертам, обеспечивая их сбалансированное обучение.
MoE в реальном мире: Mixtral, GPT-4 и Google
Технология MoE — это не просто теория. Это основа, на которой работают самые передовые модели, доступные сегодня.
- Mixtral 8x7B (от Mistral AI). Это самая известная и мощная open-source MoE-модель на сегодняшний день. Ее название «8x7B» расшифровывается так. В модели 8 специализированных FFN-экспертов. Каждый эксперт имеет около 7B параметров.
- Top-2. Для каждого токена Шлюз выбирает 2 лучших эксперта. Общее число параметров этой модели — около 47 миллиардов. Однако благодаря MoE вычислительная стоимость ее работы (инференса) эквивалентна модели всего на ~12.9 миллиардов параметров. Это позволяет Mixtral 8x7B превосходить по качеству «плотную» модель LLaMA 2 70B, работая при этом в разы быстрее.
- GPT-4 (от OpenAI). Хотя OpenAI не раскрывает архитектуру, в индустрии широко предполагается, что GPT-4 является массивной MoE-моделью. По слухам, она может состоять из 16 экспертов с общим числом параметров ~1.8 триллиона. Если это так, то именно архитектура Mixture of Experts объясняет, как GPT-4 может обладать таким огромным объемом «знаний», но при этом генерировать ответы с приемлемой скоростью.
- Google (GLaM, GShard). Именно Google был пионером в применении MoE к трансформерам в больших масштабах. Их работы, такие как GShard и GLaM (Google Language Model), продемонстрировали, что «возмутительно большие» (outrageously large) MoE-модели могут достигать нового уровня качества, оставаясь при этом вычислительно управляемыми.
MoE («Разреженные») vs. «Плотные» (Dense) модели
Чтобы окончательно закрепить материал, давайте напрямую сравним два подхода на примере популярных моделей.
«Плотная» (Dense) модель (например, LLaMA 2 70B)
- Общие параметры: 70 миллиардов.
- Активные параметры (на токен): 70 миллиардов.
- Как работает: Все 70 миллиардов параметров активируются для обработки каждого токена.
- Итог: Качество высокое, но вычислительные затраты (FLOPS) и требования к VRAM очень высоки.
«Разреженная» (Sparse) MoE-модель (например, Mixtral 8x7B)
- Общие параметры: ~47 миллиардов.
- Активные параметры (на токен): ~12.9 миллиардов.
- Как работает: Только ~12.9B параметров активируются для обработки каждого токена.
- Итог: Качество очень высокое (сравнимо с 70B моделью), требования к VRAM высокие (нужно вместить 47B), но вычислительные затраты (FLOPS) — низкие (как у 13B модели).
Mixture of Experts — это гениальный компромисс. Он позволяет получить «знания» (качество) большой модели, сохраняя при этом «скорость» (вычислительные затраты) маленькой модели. Ценой этого компромисса является повышенный расход видеопамяти.
Разработка и внедрение ML-решений
Код курса
MLOPS
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
Заключение
Mixture of Experts (MoE) — это не просто «больше» параметров, это умный способ их использования. Эта архитектура стала доминирующим подходом для построения передовых и самых мощных языковых моделей. Она меняет правила игры, позволяя масштабировать AI-модели до триллионов параметров. MoE позволяет отделить общее «знание» модели (все параметры) от «стоимости» ее использования (активные параметры), эффективно торгуя VRAM (памятью) в обмен на колоссальное снижение вычислительных затрат.
Референсные ссылки
- Блог Mistral AI о Mixtral 8x7B (Официальный анонс) — https://mistral.ai/news/mixtral-of-experts/
- GShard: Scaling Giant Models with Conditional Computation (Оригинальная статья Google) — https://arxiv.org/abs/2006.16668
- Outrageously Large Neural Networks: The Sparsely-Gated MoE Layer (Ключевая статья Google) — https://arxiv.org/abs/1701.06538
- Разбор MoE от Hugging Face (Технический блог) — https://huggingface.co/blog/moe