 1113
1113 
Содержание
- Эволюция моделей: От Llama к Llama 3
- Архитектура и принцип работы LLAMA
- Ключевое преимущество: Экономика и контроль при оффлайн-использовании
- Взаимодействие с LLAMA: Работа с собственными данными
- Простой способ: Работа с документами (RAG) или "дать почитать"
- Как это работает на Windows c оффлайн LLAMA :
- Продвинутый способ: Дообучение (Fine-Tuning)
- Как это работает (очень упрощённо):
- Преимущества и ограничения
- Заключение
- Референсные ссылки
LLAMA (Large Language Model Meta AI) — это семейство больших языковых моделей, созданное компанией Meta AI. Эти модели являются фундаментальной технологией в области искусственного интеллекта. Они предназначены для понимания и генерации текста, похожего на человеческий. Ключевой особенностью LLAMA стал её открытый подход. Meta предоставила доступ к весам моделей для широкого круга исследователей и разработчиков. Таким образом, это решение значительно демократизировало доступ к передовым AI-технологиям. Как следствие, оно стимулировало волну инноваций в open-source сообществе, позволив создавать независимые и мощные AI-решения.
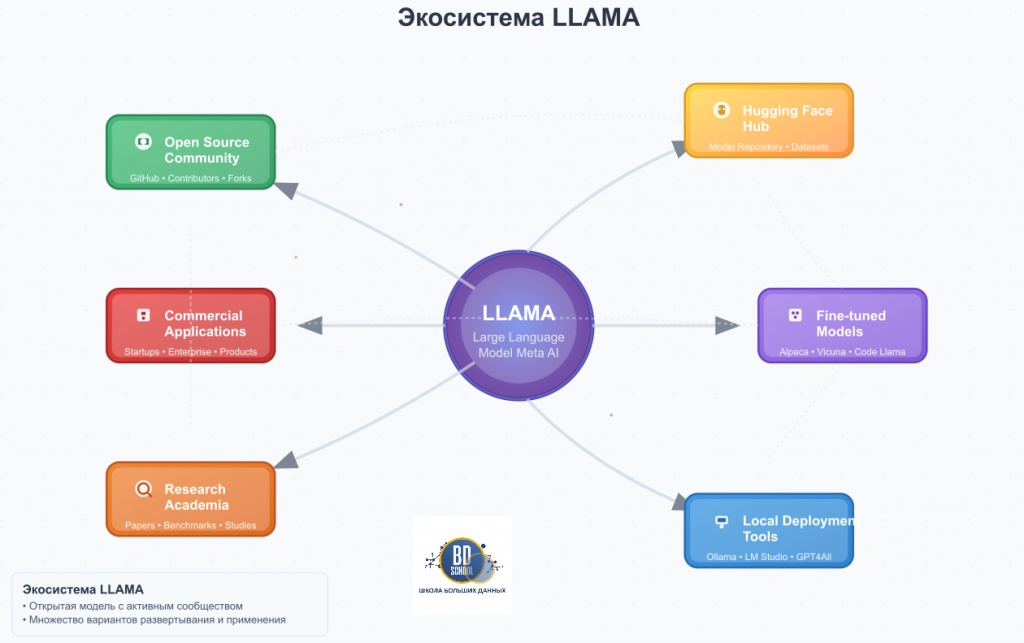
Эволюция моделей: От Llama к Llama 3
Семейство моделей LLAMA непрерывно развивается. Каждая новая версия предлагает значительные улучшения в производительности, эффективности и функциональности. Понимание их эволюции позволяет оценить быстрый прогресс в области открытых языковых моделей. Meta последовательно наращивала возможности своих разработок, делая их более мощными и доступными.
Llama (февраль 2023): Первое поколение было выпущено только для исследовательского сообщества. Оно доказало, что модели меньшего размера могут достигать высокой производительности при обучении на большом объеме данных. Линейка включала модели от 7 до 65 миллиардов параметров.
Llama 2 (июль 2023): Эта версия стала важным шагом вперёд. LLAMA 2 была выпущена по лицензии, разрешающей коммерческое использование. Модели обучались на 40% большем объеме данных и имели удвоенный контекстный окне (4096 токенов). Кроме того, были представлены специализированные версии, дообученные для ведения диалога (Llama Chat).
Llama 3 (апрель 2024): Актуальное поколение моделей, которое продемонстрировало скачок в производительности. LLAMA 3 была обучена на наборе данных объемом более 15 триллионов токенов. Модели Llama 3 8B и 70B на момент выхода превосходили многие аналогичные по размеру закрытые модели. Ключевые улучшения включают новый, более эффективный токенизатор и повышенное качество ответов.
Архитектура и принцип работы LLAMA
В основе моделей LLAMA лежит усовершенствованная архитектура Transformer. Она стала отраслевым стандартом для задач обработки естественного языка. Однако инженеры Meta внесли ряд улучшений для повышения стабильности и эффективности. Принцип работы модели можно разделить на несколько ключевых этапов, обеспечивающих генерацию связного и релевантного текста.
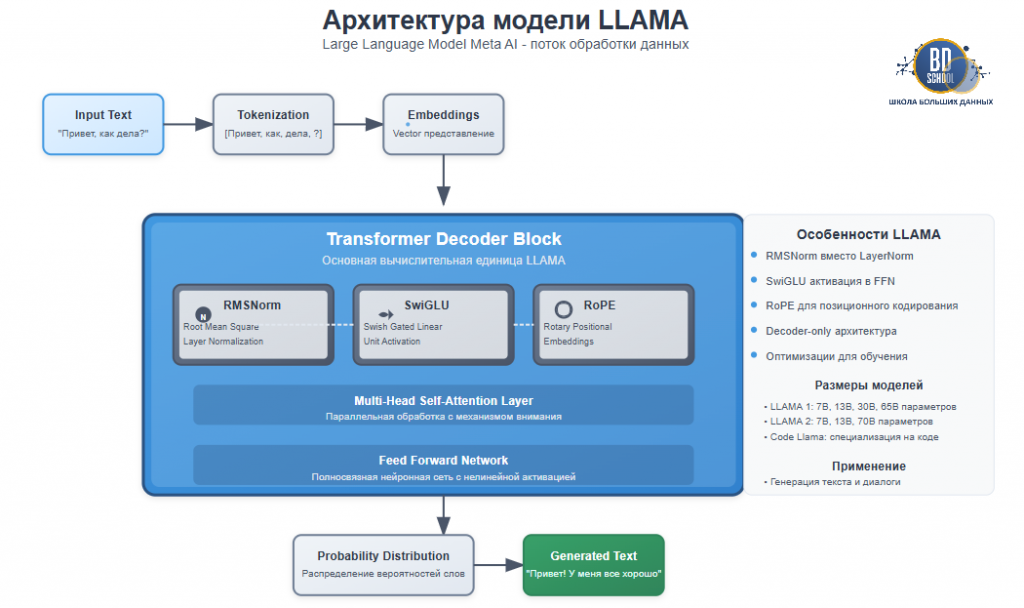
Сначала входной запрос пользователя проходит через токенизатор. Этот компонент разбивает текст на минимальные единицы — токены. Затем каждый токен преобразуется в числовой вектор (эмбеддинг), который несет в себе его семантическое значение. Эти векторы вместе с данными о их позициях поступают в стек декодер-блоков Transformer. Именно здесь происходит основная «магия». Механизмы внимания анализируют взаимосвязи между токенами, позволяя LLAMA понимать сложный контекст. Наконец, после обработки через все слои, модель формирует распределение вероятностей для предсказания следующего наиболее подходящего токена в последовательности. Этот процесс циклично повторяется до полного завершения ответа.
Ключевое преимущество: Экономика и контроль при оффлайн-использовании
Главное стратегическое преимущество LLAMA заключается в возможности локального развертывания. Этот подход коренным образом меняет экономику использования AI для бизнеса. Вместо постоянных операционных расходов (OpEx) на облачные API от коммерческих провайдеров, компании могут инвестировать в собственное оборудование. Такая модель предполагает единовременные капитальные затраты (CapEx), которые в долгосрочной перспективе оказываются значительно выгоднее.

Кроме того, оффлайн-использование LLAMA предоставляет полный контроль над данными. Информация не покидает внутренний контур компании. Это критически важно для отраслей с высокими требованиями к конфиденциальности, таких как финансы, медицина и юриспруденция. Отсутствие зависимости от внешних сервисов также повышает надёжность и стабильность работы приложений. Таким образом, LLAMA позволяет создавать полностью автономные и безопасные AI-системы, снижая риски и затраты.
Взаимодействие с LLAMA: Работа с собственными данными
Работа с LLAMA может варьироваться от простых диалогов до глубокой адаптации модели под специфические задачи. Современные инструменты позволяют пользователям даже без глубоких знаний в программировании использовать и настраивать эти мощные модели. Рассмотрим три основных уровня взаимодействия.
Базовый уровень: Запуск и диалог. Самый простой способ начать — использовать инструменты командной строки, такие как Ollama. После установки достаточно одной команды, чтобы скачать и запустить модель для интерактивного диалога прямо в терминале.
ollama run llama3
Эта команда делает передовые технологии доступными на персональном компьютере за считанные минуты. Либо вы можете скачать свою версию с сайта ollama для своей версии операционной системы и начать работать с оффлан версией LLAMA после загрзки библиотеки ~ 12Gb
Представьте, что модель Llama — это очень умный, но не знающий конкретно вашей темы сотрудник. Вы хотите, чтобы он начал разбираться в документации вашей компании, ваших юридических документах или просто в содержании 1000 книг, которые вы скачали.
Есть два принципиально разных способа это сделать: простой (дать «почитать на месте») и продвинутый (отправить на «курсы повышения квалификации»).
Простой способ: Работа с документами (RAG) или «дать почитать»
Чтобы LLAMA могла отвечать на вопросы по вашим внутренним документам, используется технология RAG (Retrieval-Augmented Generation). Она не изменяет саму модель, а работает по принципу «открытой книги».
- Принцип работы: Специальная программа-индексатор «прочитывает» ваши файлы (PDF, DOCX, TXT). Когда вы задаете вопрос, система сначала находит наиболее релевантные фрагменты в документах, а затем передает их модели вместе с вашим вопросом.
- Инструменты: Программы для Windows, такие как LM Studio или Jan, предоставляют удобный графический интерфейс для реализации RAG без необходимости писать код.
Как это работает на Windows c оффлайн LLAMA :
- Выбираем инструмент: Проще всего использовать программы с графическим интерфейсом, например, LM Studio, Jan или GPT4All. Они бесплатны и работают на Windows.
- Создаём «базу знаний»: В этих программах есть функция, которую можно назвать «Chat with your documents» или «Local RAG». Вы просто указываете папку на вашем компьютере, где лежат ваши файлы (PDF, DOCX, TXT и т.д.).
- Программа «сканирует» документы: Инструмент сам «читает» все эти файлы и создаёт специальный индекс для быстрого поиска (превращает текст в векторы). Этот процесс происходит один раз и может занять некоторое время.
- Задаём вопрос: Когда вы пишете свой вопрос к Llama, программа сначала ищет по вашей базе знаний самые релевантные фрагменты текста, а затем незаметно для вас добавляет их в запрос к модели.
Ваш запрос: «Какая ответственность предусмотрена за нарушение пункта 5.1 нашего договора?»
Что на самом деле получает Llama: «Основываясь на этом тексте: […тут программа вставляет текст пункта 5.1 и связанных с ним статей из вашего документа…], ответь на вопрос: Какая ответственность предусмотрена за нарушение пункта 5.1 нашего договора?»
Плюсы:
- Просто: Не нужно программировать, всё делается через интерфейс программы.
- Быстро: Настройка занимает минуты.
- Недорого: Не требует мощной видеокарты для «обучения», только для работы самой Llama.
- Надёжно: Модель не врёт (не галлюцинирует), так как ссылается на конкретные фрагменты из ваших документов.
Минусы:
- Модель не «учится» новому стилю общения или новой логике. Она просто цитирует и обобщает то, что ей дали.
Продвинутый способ: Дообучение (Fine-Tuning)
Это уже настоящее «обучение», которое изменяет саму модель. Вы как будто бы отправляете сотрудника на полноценные курсы, где он изучает новую тему, выполняет упражнения и в итоге получает новые знания, которые становятся частью его опыта. Он сможет отвечать на вопросы, уже не заглядывая в шпаргалку. Это процесс реального изменения модели для адаптации её под уникальный стиль или логику. Он похож на «повышение квалификации».
- Концепция: Вместо переобучения всей многомиллиардной модели используется эффективный метод LoRA (Low-Rank Adaptation). Он позволяет создать небольшую «надстройку», которая модифицирует поведение базовой LLAMA.
- Требования: Этот подход требует технических знаний, подготовленного набора данных (обычно в формате «инструкция-ответ») и мощной видеокарты NVIDIA с большим объемом видеопамяти (VRAM).
Как это работает (очень упрощённо):
- Подготовка «учебников»: Вы не можете просто дать модели папку с файлами. Нужно подготовить специальный датасет. Обычно это файл в формате вопрос-ответ или инструкция-результат.
- Пример записи:
{"instruction": "Обобщи следующий текст о Windows", "input": "Windows - это операционная система...", "output": "Windows является популярной ОС от Microsoft..."}. - Таких записей нужны тысячи, чтобы модель чему-то научилась.
- Пример записи:
- Выбор метода: Чтобы не обучать всю гигантскую модель с нуля (что требует целого дата-центра), используют технологию LoRA (Low-Rank Adaptation). Она похожа на «патч» или «мод» для игры. Вы обучаете только маленькую «надстройку» к основной модели, что в разы дешевле и быстрее.
- Запуск обучения: На Windows это сложнее. Обычно требуется:
- Мощная видеокарта NVIDIA: С большим объёмом видеопамяти (VRAM), минимум 12-16 ГБ, а лучше 24 ГБ.
- Специальные инструменты: Например, Oobabooga’s Text Generation WebUI (имеет вкладку для обучения LoRA) или использование скриптов на Python через WSL (подсистема Linux для Windows).
- Использование: После обучения вы получаете этот маленький LoRA-файл, который можно «подключать» к основной модели Llama для выполнения ваших специфических задач.
Плюсы дообучения модели:
- Глубокое знание: Модель не просто ищет информацию, а «впитывает» её. Она может научиться новому стилю (например, говорить как юрист) или новой логике.
- Скорость ответа: При ответе ей не нужно каждый раз искать информацию, она уже всё «знает».
Минусы:
- Очень сложно: Требует технических знаний, подготовки данных и настройки.
- Дорого: Нужна мощная и дорогая видеокарта.
- Риск «забывания»: При неправильном обучении модель может забыть то, что умела раньше (например, разучиться говорить на общие темы).
Итог: что выбрать?
- Если вам нужно, чтобы Llama отвечала на вопросы по вашим документам, знала ваши данные и могла их цитировать — ваш выбор на 99% простой путь (RAG). Начните с LM Studio.
- Если вам нужно, чтобы Llama научилась новому поведению, стилю речи или специфической логике, которой нет в её базовых знаниях — тогда придётся идти по продвинутому пути (дообучение).
Преимущества и ограничения
Несмотря на свою мощь, LLAMA является инструментом, который имеет как сильные стороны, так и определенные ограничения. Для эффективного применения технологии необходимо понимать этот баланс.
Преимущества:
- Контроль и конфиденциальность: Локальное развертывание обеспечивает полный суверенитет над данными, что исключает риски утечек через сторонние сервисы.
- Экономическая выгода: Отсутствие лицензионных платежей и платы за API-запросы при оффлайн-использовании снижает общую стоимость владения.
- Гибкость и кастомизация: Возможность тонкой настройки (fine-tuning) позволяет адаптировать LLAMA под узкоспециализированные задачи.
- Сильное сообщество: Активное open-source сообщество обеспечивает поддержку, создает новые инструменты и постоянно улучшает модели.

Ограничения:
- Высокие требования к ресурсам: Для работы и дообучения моделей требуются значительные вычислительные мощности, в частности дорогие видеокарты.
- Сложность эксплуатации: Установка, настройка и поддержка локально развернутой LLAMA требуют серьезных технических компетенций.
- Ответственность: Вся ответственность за генерируемый контент и его соответствие этическим нормам ложится на пользователя.
Заключение
Таким образом, LLAMA — это не просто технология, а катализатор фундаментальных изменений в индустрии искусственного интеллекта. Предоставив открытый доступ к своим мощным моделям, Meta позволила тысячам разработчиков и компаний по всему миру создавать собственные AI-решения. Главная ценность LLAMA заключается в её способности обеспечивать технологическую независимость, контроль над данными и экономическую эффективность. Она стала фундаментом для построения нового поколения автономных, безопасных и кастомизированных интеллектуальных систем, формируя более открытое и конкурентное будущее для всей отрасли.
Референсные ссылки
- Официальный блог с анонсами от разработчика https://ai.meta.com/blog/
- Центральный репозиторий для скачивания моделей https://huggingface.co/meta-llama
- Технический доклад о модели L 3 https://arxiv.org/pdf/2404.11082