 287
287 
Содержание
- Eager vs. Lazy Evaluations: Битва подходов
- Eager Evaluation (Энергичные вычисления)
- Lazy Evaluation (Ленивые вычисления)
- Архитектура ленивости: Трансформации и Действия
- Transformations (Трансформации)
- Actions (Действия)
- От кода к DAG: Сквозной пример использования Lazy Evaluations
- Этап 0: Подготовим стенд для опытов без Hadoop и HDFS (Ubuntu/WSL)
- Этап 1: Написание кода Spark (Scala)
- Этап 2: Что происходит в Spark (Jobs и DAG)
- Магия оптимизации: Catalyst Optimizer
- Преимущества и подводные камни Lazy Evaluation
- Заключение
- Референсные ссылки
Lazy Evaluation (Ленивые вычисления) — это стратегия выполнения программного кода, при которой запуск вычислений откладывается до тех пор, пока их результат не потребуется явно (например, для вывода на экран или сохранения на диск). В экосистеме Big Data (в частности, в Apache Spark) этот подход является фундаментальным: он позволяет системе сначала построить полный направленный ациклический граф задач (DAG), оптимизировать его целиком и только затем выделить ресурсы на обработку данных.
В отличие от классического программирования, где команды выполняются строка за строкой, «ленивый» подход позволяет избегать ненужных вычислений, экономить оперативную память и автоматически восстанавливать потерянные данные при сбоях.
Если вы еще не знакомы с тем, как именно строятся графы задач, рекомендую сначала изучить статью: DAG (Directed Acyclic Graph) в Big Data.
Eager vs. Lazy Evaluations: Битва подходов
Чтобы понять архитектурную необходимость ленивых вычислений в Big Data, нужно сравнить их с традиционной моделью.
Eager Evaluation (Энергичные вычисления)
Это стандартный подход (например, Python Pandas или Java List). Интерпретатор выполняет выражение сразу, как только встречает его в коде.
- Пример: Вы загружаете CSV-файл на 1 ТБ в Pandas.
- Результат: Библиотека немедленно попытается прочитать весь файл в RAM. Программа упадет с ошибкой Out Of Memory еще до того, как вы начнете фильтровать данные.
Lazy Evaluation (Ленивые вычисления)
В этой модели вызов функции не запускает обработку данных, а лишь добавляет запись в «план действий».
- Пример: Вы пишете команду загрузки того же CSV в Apache Spark.
- Результат: Spark не читает файл. Он лишь запоминает метаданные (путь к файлу). Чтение начнется только тогда, когда вы запросите конкретный результат.
Архитектура ленивости: Трансформации и Действия
В Apache Spark код делится на два типа операций. Понимание разницы между ними критично для управления DAG.
Transformations (Трансформации)
Это «ленивые» операции. Они создают новый RDD/DataFrame из существующего. При их вызове ничего не вычисляется. Spark просто обновляет свой внутренний граф задач в соответствии с Lazy Evaluations.
- Примеры: map, filter, flatMap, reduceByKey, join.
- Суть: Мы просто описываем логику преобразований («Взять колонку А», «Отфильтровать Б»).
Actions (Действия)
Это спусковой крючок. Действия заставляют Spark «материализовать» план, запустить вычисления на кластере и вернуть результат.
- Примеры: collect, count, saveAsTextFile, take.
- Суть: Мы требуем готовый результат здесь и сейчас.
От кода к DAG: Сквозной пример использования Lazy Evaluations
Лучший способ понять, как текст превращается в граф — разобрать реальный пример из spark-shell для оценки механизма Lazy eveluations.
Допустим, мы анализируем биржевые данные, чтобы найти максимальный объем торгов (volume) по каждому тикеру (symbol).
Этап 0: Подготовим стенд для опытов без Hadoop и HDFS (Ubuntu/WSL)
# Необходима Java и сам Spark (через pip ставится обертка) sudo apt install default-jdk python3-pip # Скачиваем архив (проверьте актуальную версию на сайте, здесь пример для 3.5.0) wget https://archive.apache.org/dist/spark/spark-3.5.0/spark-3.5.0-bin-hadoop3.tgz # Распаковываем tar xvf spark-3.5.0-bin-hadoop3.tgz # Переходим в папку cd spark-3.5.0-bin-hadoop3 #--- готовим данные Dataset # Создаем папку для данных mkdir -p data # Создаем файл с тестовыми данными (без заголовка, чтобы код не упал на .toInt) echo "2024-01-01,AAPL,150,155,149,152,152,5000" > data/stocks.csv echo "2024-01-02,AAPL,152,158,151,157,157,6000" >> data/stocks.csv echo "2024-01-01,GOOGL,100,105,99,102,102,3000" >> data/stocks.csv echo "2024-01-02,GOOGL,102,104,101,103,103,3500" >> data/stocks.csv # --Запуск Spark Shell в локальном режимe ./bin/spark-shell --master "local[*]"
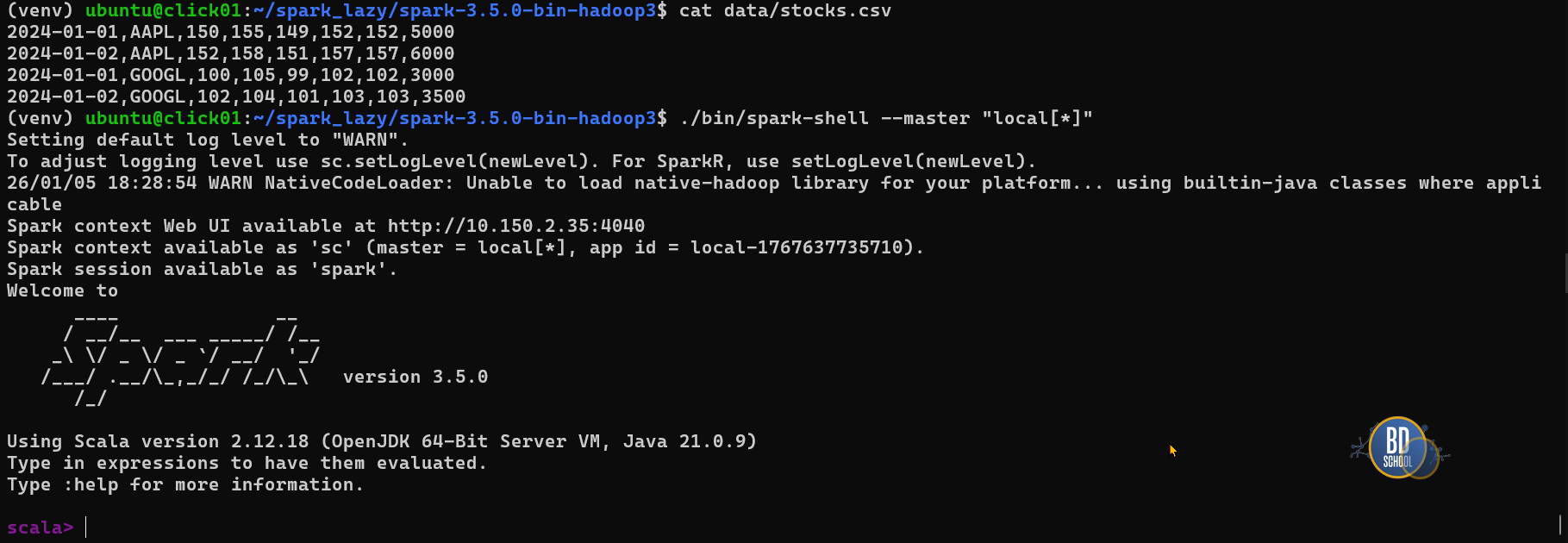
Этап 1: Написание кода Spark (Scala)
Анализ данных с помощью современного Apache Spark
Код курса
SPARK
Ближайшая дата курса
6 апреля, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
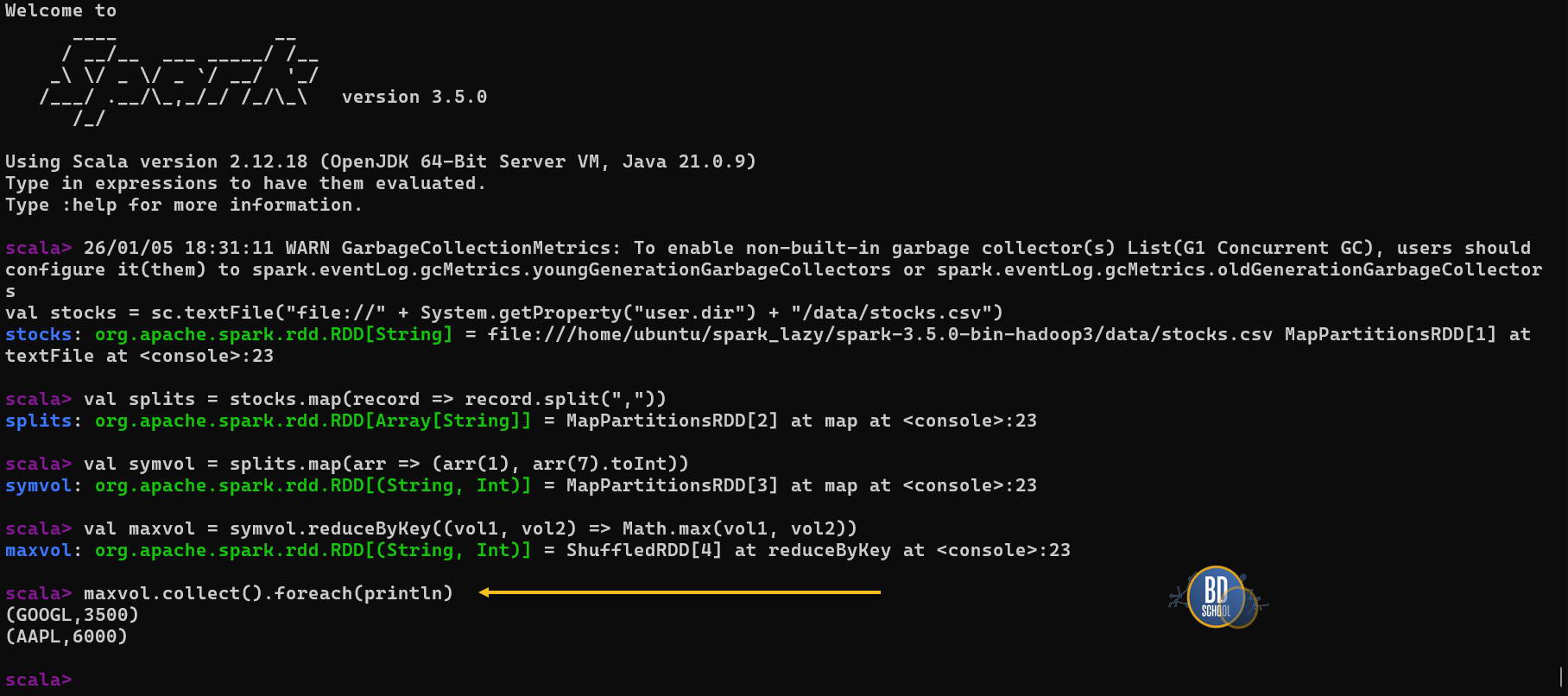
// 1. Читаем локальный файл (обратите внимание на file:///)
val stocks = sc.textFile("file://" + System.getProperty("user.dir") + "/data/stocks.csv")
// 2. Парсим
val splits = stocks.map(record => record.split(","))
// 3. Выделяем Тикер и Объем
val symvol = splits.map(arr => (arr(1), arr(7).toInt))
// 4. Агрегируем (reduceByKey ищет максимум)
val maxvol = symvol.reduceByKey((vol1, vol2) => Math.max(vol1, vol2))
// 5. Выводим результат
maxvol.collect().foreach(println)
Этап 2: Что происходит в Spark (Jobs и DAG)
Как только вы нажали Enter на строке с .collect(), Spark превращает этот код в Job, который состоит из стадий. В Spark UI вы увидите следующий DAG:
Stage 0 (Подготовка):
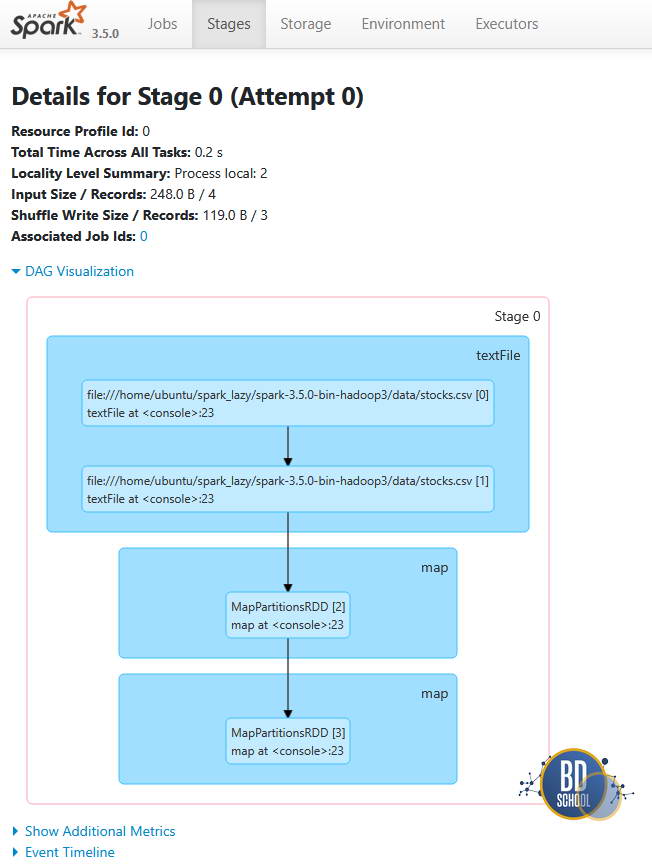
- Spark объединяет операции textFile, первый map (split) и второй map (выбор полей) в один конвейер.
- Pipelining: Данные считываются с диска, парсятся и фильтруются за один проход, не сохраняясь промежуточно.
- Эта стадия заканчивается подготовкой к отправке данных по сети (Shuffle Write).
Stage 1 (Агрегация):
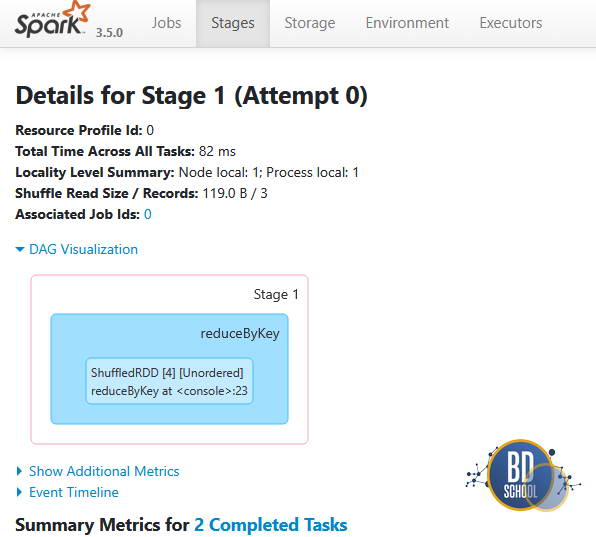
- Эта стадия начинается после перемешивания данных (Shuffle Read).
- Здесь выполняется логика reduceByKey (поиск максимума).
- Результат отправляется на драйвер (collect).
Важно: Обратите внимание, что граница между стадиями проходит именно по reduceByKey. Ленивые вычисления позволяют Spark «схлопнуть» все map операции в Stage 0, но Shuffle всегда разрывает цепочку.
Магия оптимизации: Catalyst Optimizer
Главное преимущество ленивости — возможность Spark увидеть весь алгоритм целиком до запуска. Это позволяет применить глобальные оптимизации через движок Catalyst:
- Predicate Pushdown (Проталкивание фильтров): Если бы мы добавили .filter(arr(1) == «AAPL») перед reduceByKey, Spark не стал бы агрегировать все акции. Он переместил бы фильтр в самое начало, отбросив лишние данные сразу при чтении.
- Column Pruning (Отсечение колонок): Хотя в CSV файле может быть 100 колонок, Spark видит, что нам нужны только индексы 1 и 7. Физически с диска будут прочитаны только они ( в случае хранения данных в columnar format — Parquet/ORC).
Анализ данных с помощью современного Apache Spark
Код курса
SPARK
Ближайшая дата курса
6 апреля, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Преимущества и подводные камни Lazy Evaluation
Плюсы:
- Отказоустойчивость (Fault Tolerance): Если сервер упадет во время расчета maxvol, Spark знает по DAG (Lineage), что данные можно восстановить, перечитав файл и повторив map. Ему не нужно начинать всё приложение с нуля.
- Эффективность: Минимизация операций ввода-вывода (I/O).
Минусы:
- Сложность отладки: Если в вашем файле в 7-й колонке окажется буква вместо цифры, ошибка NumberFormatException вылетит не на строке val symvol = …, а на строке maxvol.collect(). Это часто сбивает новичков с толку: ошибка указывается там, где она «всплыла», а не там, где была запрограммирована.
Заключение
Ленивые вычисления превращают Spark из простого калькулятора в умного планировщика. Когда вы пишете код на Spark или PySpark, вы не двигаете данные руками — вы строите чертеж (DAG).
В следующий раз, запустив collect() или write(), обязательно откройте Spark UI (вкладка DAG Vizualization). Если вы увидите там свои стадии, соответствующие логике кода (как в примере с stocks), значит, вы начали мыслить как инженер Big Data.
Референсные ссылки
- Apache Spark Architecture Explained (Apache Documentation, 2024)
- RDD Programming Guide (Apache Documentation, 2024)
- Understanding Spark’s Logical and Physical Plans (Databricks Blog, 2024)