 1703
1703 
Содержание
- Ключевые особенности и архитектура LLM
- Масштаб: Ключ к возможностям (параметры и данные)
- Архитектура Трансформер (Transformer)
- Механизм внимания (Self-Attention)
- Как работает LLM: От обучения до генерации
- Этап 1: Предобучение (Pre-training)
- Этап 2: Тонкая настройка (Fine-Tuning)
- Этап 3: Генерация ответа (Inference) и Промптинг
- Основные сценарии использования LLM
- Взаимодействие с LLM: Практические примеры
- Пример 1: Доступ к LLM через API (Python)
- Пример 2: Использование Hugging Face Transformers (Python)
- Вызовы и ограничения LLM
- Будущее LLM
- Заключение
- Референсные ссылки
LLM (Large Language Model) — это тип системы искусственного интеллекта (ИИ), обученный на огромных объемах текстовых данных для понимания, генерации и прогнозирования человеческого языка с высокой точностью. Эти модели являются основой для множества современных приложений. Они могут писать эссе, переводить языки, отвечать на вопросы и даже создавать программный код. По сути, LLM — это сложная статистическая машина. Она анализирует гигабайты текста из интернета, книг и статей. На основе этого анализа модель изучает закономерности, грамматику, стили и факты. В результате она учится «предсказывать» следующее наиболее вероятное слово в предложении. Именно эта способность позволяет ей генерировать осмысленные и связные тексты.
Ключевые особенности и архитектура LLM
Успех LLM обусловлен тремя ключевыми компонентами. Эти компоненты работают вместе, создавая мощные и гибкие системы. Понимание их основ помогает осознать, почему LLM так эффективны.
Масштаб: Ключ к возможностям (параметры и данные)
Главное отличие LLM кроется в их названии — «Large». Этот масштаб проявляется в двух аспектах. Во-первых, это данные для обучения. Модели «читают» практически весь доступный интернет и цифровые библиотеки. Во-вторых, это количество параметров. Параметры — это внутренние переменные модели, которые она настраивает в процессе обучения. Если представить модель как мозг, то параметры — это синапсы. Ранние модели имели тысячи параметров. Современные LLM оперируют сотнями миллиардов или даже триллионами таких параметров. Именно этот гигантский масштаб позволяет им улавливать тонкие нюансы языка.
Архитектура Трансформер (Transformer)
Почти все современные LLM основаны на архитектуре «Трансформер». Она была представлена в 2017 году и произвела революцию в обработке языка. До трансформеров доминировали другие архитектуры, например, RNN и LSTM. Они обрабатывали текст последовательно, слово за словом. Это было медленно и приводило к потере контекста в длинных предложениях. Трансформер же способен обрабатывать все слова в предложении одновременно (параллельно). Это значительно ускорило обучение. Кроме того, он ввел фундаментальный механизм, изменивший правила игры.
Механизм внимания (Self-Attention)
Этот механизм — ядро архитектуры Трансформер. Механизм внимания позволяет модели взвешивать важность разных слов в предложении. Когда модель обрабатывает одно слово, она «смотрит» на все остальные слова. Это помогает ей понять контекст. Например, в предложении «Банк закрыл счет» слово «банк» связано со «счетом». В предложении «Он сел на банк у реки» слово «банк» связано с «рекой». Механизм внимания позволяет LLM уловить эту разницу. Он решает, какие слова в предложении наиболее релевантны друг для друга.
Как работает LLM: От обучения до генерации
Процесс создания и использования LLM можно условно разделить на три этапа. Каждый этап вносит свой вклад в итоговые возможности модели. Этот путь превращает сырые данные в полезный инструмент (информацию).
Этап 1: Предобучение (Pre-training)
Это самый долгий и дорогой этап. Модель получает триллионы слов из общедоступных источников. Ее задача на этом этапе очень проста, но фундаментальна. Чаще всего она сводится к «предсказанию маскированного слова». Выглядит это так: из предложения убирают слово (Я пошел [МАСКА] в магазин). Модель должна угадать, какое слово там было (гулять, завтракать, работать). Делая это миллиарды раз, LLM выстраивает глубокое статистическое понимание языка. Она узнает грамматику, факты о мире и логические связи. Этот этап требует огромных вычислительных мощностей.
Этап 2: Тонкая настройка (Fine-Tuning)
После предобучения LLM знает язык, но не умеет выполнять конкретные задачи. Она не знает, что такое «ответ на вопрос» или «перевод». На этапе тонкой настройки модель дообучают на более узком наборе данных. Эти данные специально подготовлены. Например, они состоят из пар «вопрос-ответ». Этот процесс «объясняет» модели, как должен выглядеть полезный результат. Существует также продвинутый метод настройки, известный как RLHF. Он использует обратную связь от людей для улучшения качества ответов.
Этап 3: Генерация ответа (Inference) и Промптинг
Это этап, на котором мы взаимодействуем с LLM. Когда вы задаете модели вопрос, вы создаете «промпт» (запрос). Модель анализирует ваш промпт. Затем она начинает генерировать ответ слово за словом. Каждое следующее слово — это ее статистический прогноз. Она выбирает наиболее вероятное слово, которое должно идти после уже сгенерированного текста. Этот процесс называется «инференс» (вывод). Качество ответа сильно зависит от качества вашего промпта.
Основные сценарии использования LLM
LLM уже изменили многие сферы. Их гибкость позволяет применять их для решения разнообразных задач. Ниже приведены наиболее распространенные примеры.
Мы рассмотрим несколько ключевых областей:
- Генерация контента. LLM могут писать маркетинговые тексты, посты для блогов и даже стихи.
- Создание и анализ кода. Модели помогают программистам писать код быстрее. Они находят ошибки и предлагают варианты оптимизации.
- Чат-боты и ассистенты. Современные службы поддержки часто используют LLM для ответов на вопросы клиентов.
- Перевод. Модели обеспечивают качественный и контекстуальный перевод между десятками языков.

- Суммаризация. LLM способны быстро извлечь суть из длинных документов. Они могут сократить статью или отчет до нескольких абзацев.
- Анализ настроений (Sentiment Analysis). Бизнес использует LLM для анализа отзывов. Модели определяют, довольны клиенты продуктом или нет.

Эти сценарии демонстрируют лишь часть возможностей. По мере развития технологии появляются новые способы применения.
Взаимодействие с LLM: Практические примеры
Для IT-специалиста важно понимать, как работать с LLM на практике. Чаще всего это происходит через API или с помощью специализированных библиотек. Рассмотрим два популярных способа на языке Python.
Пример 1: Доступ к LLM через API (Python)
Многие крупные компании (OpenAI, Google, Anthropic) предоставляют доступ к своим LLM через API. Вы отправляете текстовый запрос на сервер и получаете готовый ответ. Это самый простой способ интеграции.
# Убедитесь, что у вас установлена библиотека: pip install openai
from openai import OpenAI
import os
# Ключ берём из переменной окружения:
# export OPENAI_API_KEY="sk-..."
client = OpenAI()
try:
resp = client.chat.completions.create(
model="gpt-4o-mini", # вместо снятого gpt-3.5-turbo
messages=[
{"role": "system", "content": "Ты полезный ассистент."},
{"role": "user", "content": "Объясни, что такое 'Трансформер' в ИИ, в двух предложениях."}
],
)
print(resp.choices[0].message.content)
except Exception as e:
# Расширенный вывод для отладки
import traceback, json
print("Ошибка запроса:", e)
traceback.print_exc()
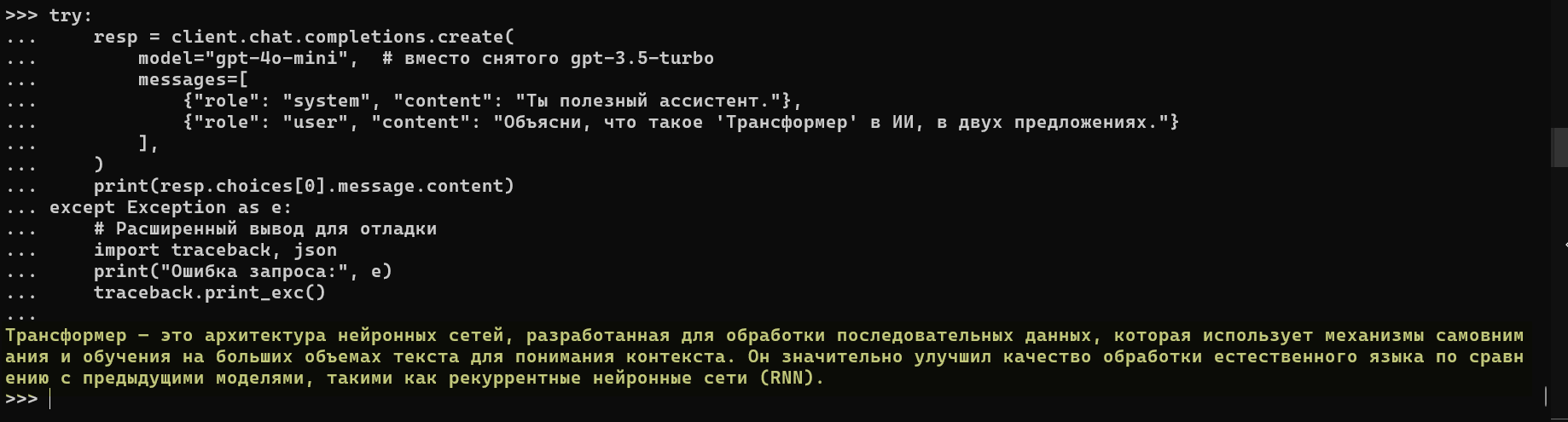
Этот код показывает базовый запрос к LLM. Он демонстрирует, как легко получить мощный ответ от модели.
Пример 2: Использование Hugging Face Transformers (Python)
Для тех, кто хочет больше контроля, существует библиотека transformers. Она позволяет запускать LLM локально (на вашем компьютере или сервере). Это дает гибкость и контроль над данными. Hugging Face является стандартом в сообществе.
# Установите необходимые библиотеки: pip install transformers torch
from transformers import pipeline
# 1. ПОДКЛЮЧЕНИЕ (ЗАГРУЗКА МОДЕЛИ)
# Загружаем pipeline для задачи "генерация текста"
# Модель будет загружена автоматически при первом запуске
# "gpt2" - это одна из известных LLM, доступных на Hugging Face
try:
generator = pipeline('text-generation', model='gpt2')
# 2. СОЗДАНИЕ ЗАПРОСА (ПРОМПТА)
prompt = "LLM (Large Language Model) — это"
# 3. ПОЛУЧЕНИЕ И ВЫВОД ОТВЕТА
# Генерируем текст на основе промпта
# max_length - максимальная длина ответа
# num_return_sequences - сколько вариантов ответа сгенерировать
result = generator(prompt, max_length=50, num_return_sequences=1)
print(result[0]['generated_text'])
except Exception as e:
print(f"Произошла ошибка при загрузке модели или генерации: {e}")
print("Убедитесь, что у вас есть стабильное интернет-соединение для загрузки модели.")
Этот пример иллюстрирует запуск LLM локально. Он требует больше ресурсов, но идеально подходит для экспериментов.
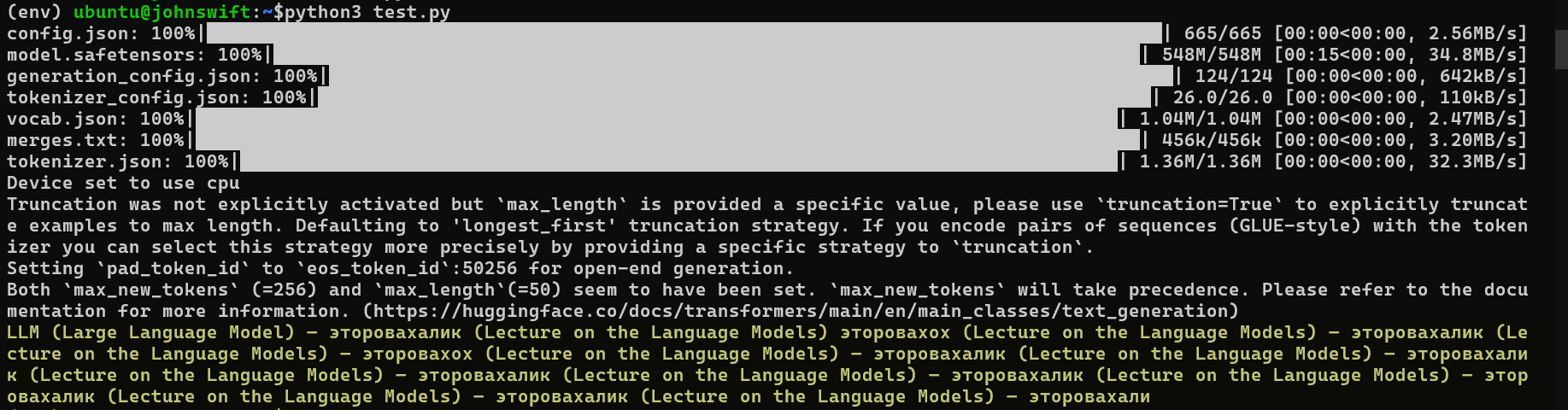
Как вы видите модель не очень корректно работает с руским языком потому как не обучалась на русских источниках ( попробуйте заменить модель на sberbank-ai/rugpt3small_based_on_gpt2 или ai-forever/rugpt3medium_based_on_gpt2 🙂
Вызовы и ограничения LLM
Несмотря на впечатляющие возможности, LLM имеют серьезные ограничения. Важно понимать их при работе с технологией. LLM не «думают» в человеческом смысле. Они являются сложными «попугаями», повторяющими выученные шаблоны.
Одним из главных вызовов являются «галлюцинации». Это случаи, когда LLM уверенно генерирует ложную или бессмысленную информацию. Модель не имеет реального понимания мира. Она просто предсказывает следующее слово. Другая проблема — предвзятость (bias). Модели обучаются на текстах из интернета. Если эти тексты содержат стереотипы или предрассудки, LLM их выучит и будет воспроизводить. Кроме того, LLM требуют огромных затрат. Их обучение и работа потребляют колоссальное количество энергии. Это создает как экономические, так и экологические барьеры.
Будущее LLM
Технология LLM развивается невероятно быстро. Исследователи работают над решением текущих проблем. Одно из направлений — создание более эффективных моделей. Они будут требовать меньше данных и энергии для обучения. Другое важное направление — мультимодальность. Будущие LLM смогут оперировать не только текстом. Они уже учатся понимать изображения, аудио и видео. Это позволит создавать ассистентов, которые видят мир так же, как люди.
Ожидается, что LLM станут меньше и быстрее. Это позволит запускать их на персональных устройствах, таких как смартфоны. Это повысит конфиденциальность, так как данные не будут покидать устройство. LLM — это не просто инструмент. Они становятся платформой для создания новых продуктов и сервисов.
Заключение
LLM — это фундаментальная технология. Она изменила наш подход к обработке информации и взаимодействию с компьютерами. Мы рассмотрели ее ключевые компоненты: от масштаба до архитектуры Трансформер. Мы поняли этапы ее работы: предобучение, настройка и генерация. Примеры кода показывают, что технология доступна для разработчиков. Однако важно помнить об ограничениях LLM, таких как галлюцинации. Будущее этих моделей обещает еще более впечатляющие возможности. Понимание LLM сегодня — это ключ к успешной работе в IT завтра.
Референсные ссылки
- Официальная документация библиотеки Transformers (Hugging Face) (https://huggingface.co/docs/transformers/index)
- Научная статья «Attention Is All You Need» (arXiv.org) (https://arxiv.org/abs/1706.03762)
- Обзорная статья «Large language model» (Wikipedia) (https://en.wikipedia.org/wiki/Large_language_model)