 765
765 
Содержание
- Ключевые компоненты архитектуры LangChain
- Принцип работы LChain: Цепочки и Агенты
- Сценарии использования LangChain
- Взаимодействие с LangChain: пример RAG
- LangChain Expression Language (LCEL)
- Экосистема LangChain: LangSmith и LangServe
- Ключевые альтернативы LangChain и их сравнение
- Заключение
- Референсные ссылки
LangChain — это фреймворк с открытым исходным кодом для разработки приложений на базе больших языковых моделей (LLM). Его главная цель — решить фундаментальную проблему изолированности LLM. По умолчанию языковые модели, такие как GPT или Claude, ограничены статичными данными своего обучения. Они не могут получать актуальную информацию из интернета или взаимодействовать с частными базами данных и API. LangChain предоставляет набор инструментов и интерфейсов, выступая в роли «оркестратора». Он позволяет надежно связывать LLM с этими внешними источниками. Таким образом, фреймворк дает возможность создавать «контекстно-зависимые» (context-aware) и «способные к действию» (action-capable) приложения, превращая LLM в мощных автономных агентов.
Ключевые компоненты архитектуры LangChain
Мощь LangChain заключается в его продуманной модульной архитектуре. Фреймворк не является монолитной системой. Он состоит из набора независимых, но легко компонуемых «строительных блоков». Эта философия позволяет разработчикам гибко комбинировать компоненты. Они могут создавать как простые пайплайны, так и чрезвычайно сложные системы. Глубокое понимание каждого основного модуля является ключом к эффективному использованию LangChain.
Рассмотрим детально основные компоненты, формирующие ядро фреймворка.
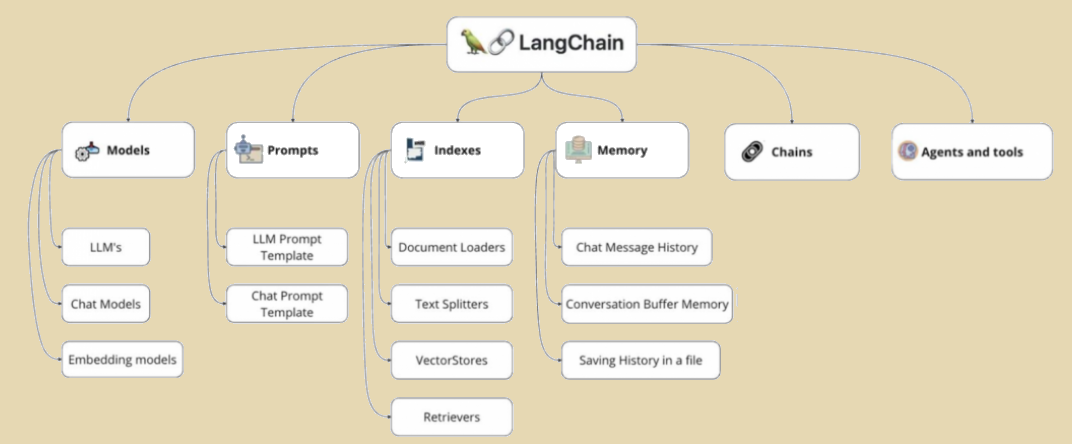
- Models. Этот модуль обеспечивает унифицированный интерфейс для взаимодействия с различными моделями. Важно понимать, что LangChain сам не предоставляет LLM. Вместо этого он интегрируется с десятками провайдеров (OpenAI, Anthropic, Hugging Face и др.). Компонент разделяет модели на три типа. LLMs — классические модели завершения текста. Chat Models — более современные модели, работающие со списком сообщений (System, Human, AI). Embedding Models — модели, преобразующие текст в числовые векторы.
- Prompts (Промпты). Управление промптами — это основа взаимодействия с LLM. Модуль Prompts позволяет создавать динамические шаблоны. Эти шаблоны форматируют ввод для модели на основе переменных. Например, PromptTemplate может принимать запрос пользователя и историю чата. Это позволяет создавать сложные и адаптивные инструкции для LLM.
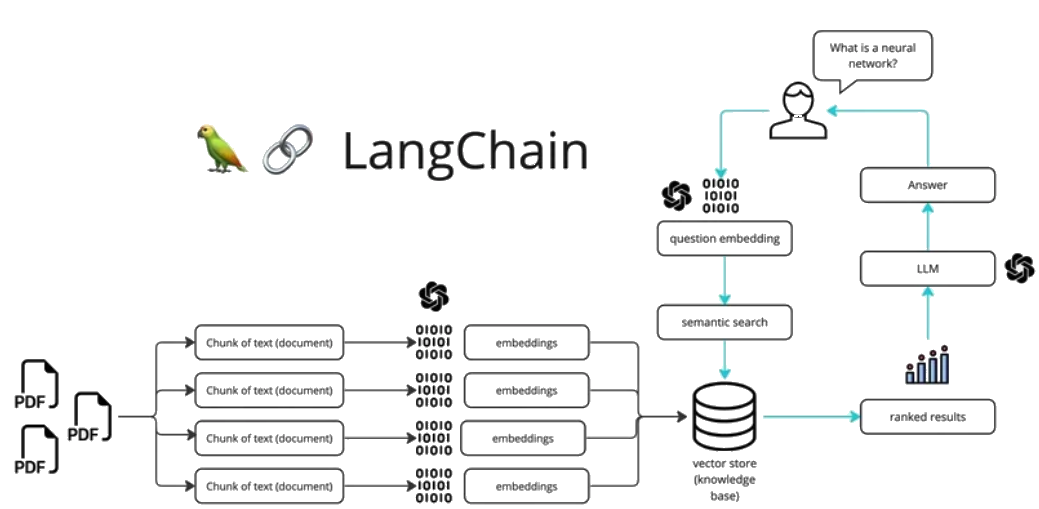
- Retrievers (Извлекатели). Этот компонент отвечает за получение данных. Извлекатели служат интерфейсом для поиска и загрузки релевантной информации. Чаще всего они работают в связке с Vector Stores (векторными хранилищами). Сначала документы (PDF, TXT, HTML) загружаются, делятся на части и векторизуются. Затем извлекатель по запросу пользователя находит наиболее похожие фрагменты данных.
- Output Parsers (Парсеры вывода). LLM возвращают ответ в виде сырой текстовой строки. Для приложений часто требуется структурированный формат, например, JSON или список Python. Парсеры вывода обрабатывают сырой ответ модели. Они извлекают информацию и приводят ее к нужному формату, включая обработку ошибок.
- Memory (Память). По своей природе LLM не имеют состояния (stateless). Они не помнят предыдущие взаимодействия в диалоге. Модуль Memory решает эту проблему. Он предоставляет механизмы для сохранения и извлечения истории чата. LangChain предлагает разные стратегии, от простого буфера до сложных сводных отчетов.
Эти компоненты являются фундаментальной основой для двух главных концепций оркестрации.
Принцип работы LChain: Цепочки и Агенты
Компоненты LangChain редко используются поодиночке. Их истинная сила раскрывается, когда они объединяются в единый процесс. LangChain предлагает два основных механизма для такой оркестрации. Это Chains (Цепочки) и Agents (Агенты).
Цепочки представляют собой заранее определенную, жесткую последовательность шагов. Это наиболее распространенный способ использования LangChain. Цепочка гарантирует, что операции выполняются в строгом порядке. Классический пример — это RAG-цепочка. Она последовательно выполняет шаги. Сначала извлекает документы с помощью Retriever. Затем форматирует промпт, вставляя в него документы и вопрос. После этого она отправляет промпт в LLM. Наконец, она получает ответ и передает его пользователю. LangChain позволяет создавать сложные последовательности, где вывод одной цепочки служит вводом для следующей.
Агенты — это гораздо более сложный и мощный механизм. В отличие от цепочек, агент не следует заранее заданному скрипту. Агент использует LLM для принятия динамических решений «на лету». Он сам решает, какое действие предпринять для достижения цели. В основе работы агента лежит ReAct (Reasoning and Acting). Это итеративный цикл «Мысль-Действие-Наблюдение».
- Мысль (Thought): LLM анализирует запрос пользователя и решает, что нужно сделать.
- Действие (Action): Агент выбирает один из доступных ему Инструментов (Tools). Инструментом может быть поисковик Google, калькулятор, API погоды или даже другая цепочка LangChain.
- Наблюдение (Observation): Агент получает результат выполнения инструмента.
Этот цикл повторяется. Агент анализирует результат и генерирует новую «Мысль». Он продолжает работать до тех пор, пока не сочтет задачу решенной. Управляет этим процессом специальный модуль AgentExecutor. Таким образом, агенты LangChain могут выполнять сложные, многошаговые задачи.
ИИ-агенты для оптимизации бизнес-процессов
Код курса
AGENT
Ближайшая дата курса
18 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
Сценарии использования LangChain
Гибкая и модульная архитектура LangChain открыла дорогу для множества сценариев. Фреймворк быстро стал отраслевым стандартом для прототипирования. Сейчас он все активнее используется для создания полнофункциональных production-систем.
Ниже перечислены наиболее распространенные и важные сценарии применения LangChain.
- Retrieval-Augmented Generation (RAG). Это самый популярный сценарий. LangChain позволяет LLM отвечать на вопросы, основываясь на частных, внешних документах. Фреймворк берет на себя всю тяжелую работу. Он загружает документы, делит их на фрагменты (чанки), векторизует и сохраняет в базе. Во время запроса он находит релевантные фрагменты и «дополняет» ими промпт.
- Автономные агенты. Эта концепция позволяет создавать ИИ-помощников. Они могут выполнять сложные задачи, требующие планирования. Например, агент-аналитик может получить доступ к API компании. Он может самостоятельно строить отчеты, анализировать метрики и отвечать на бизнес-вопросы.
- Чат-боты с памятью. Используя модуль Memory, LangChain значительно упрощает создание ботов. Они способны вести осмысленный, контекстный диалог. Боты помнят, о чем шла речь ранее, что делает общение естественным.
- Анализ структурированных данных. LangChain предоставляет агентов для работы с SQL, CSV и Pandas. Пользователь может задать вопрос на естественном языке. Например, «Покажи мне топ-5 клиентов по объему выручки за прошлый квартал». Агент самостоятельно напишет SQL-запрос, выполнит его в базе данных и интерпретирует результат.
- Суммаризация и извлечение данных. Фреймворк включает специализированные цепочки. Они предназначены для обработки очень длинных документов, которые не помещаются в контекстное окно LLM. Они могут извлечь ключевые тезисы или структурировать неформатированный текст в JSON.
Этот список не является исчерпывающим. Настоящая сила LangChain проявляется в том, что эти сценарии можно комбинировать.
Взаимодействие с LangChain: пример RAG
Рассмотрим практический пример. Мы создадим базовый RAG-пайплайн. Он позволит LLM отвечать на вопросы по нашему собственному тексту. Мы будем использовать современный синтаксис LangChain Expression Language (LCEL). Сначала необходимо установить все требуемые библиотеки.
# Установка основных библиотек LangChain и интеграций pip install langchain langchain-openai langchain-community faiss-cpu
Этот код установит ядро LangChain, интеграцию с OpenAI (для модели и эмбеддингов) и FAISS (для локального векторного хранилища).
Теперь напишем Python-скрипт. Он реализует полный цикл RAG от загрузки данных до получения ответа.
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
# --- Шаг 1: Подготовка данных ---
# Это наши "внешние" знания
text_data = """
LangChain - это фреймворк для разработки LLM-приложений.
Его ключевые компоненты - Модели, Промпты и Парсеры.
LangChain был создан в 2022 году для упрощения работы с LLM.
LCEL - это декларативный синтаксис для построения цепочек.
LangSmith используется для отладки и мониторинга приложений.
"""
# Разделяем текст на небольшие фрагменты (чанки)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
docs = text_splitter.create_documents([text_data])
# --- Шаг 2: Векторизация и хранение ---
# Создаем эмбеддинги и индексируем документы в FAISS
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(docs, embeddings)
# Создаем Retriever - интерфейс для поиска релевантных документов
retriever = vectorstore.as_retriever()
# --- Шаг 3: Определение цепочки (LCEL) ---
# Создаем шаблон промпта
template = """
Ты - ассистент, отвечающий на вопросы.
Используй только предоставленный контекст для ответа.
Контекст: {context}
Вопрос: {question}
Ответ:
"""
prompt = ChatPromptTemplate.from_template(template)
# Инициализируем модель
model = ChatOpenAI()
# Собираем RAG-цепочку с помощью LCEL
# Этот пайплайн будет выполнен последовательно
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
# --- Шаг 4: Выполнение запроса ---
query = "Для чего используется LangSmith в LangChain?"
response = rag_chain.invoke(query)
print(response)
# Ожидаемый ответ: 'LangSmith используется для отладки и мониторинга приложений.'
Этот пример наглядно демонстрирует оркестрацию. LangChain сначала параллельно вызывает retriever и передает исходный вопрос. Затем он форматирует промпт. Наконец, он вызывает модель и парсит ее вывод.
LangChain Expression Language (LCEL)
LangChain Expression Language (LCEL) представляет собой фундаментальное изменение. Он изменил парадигму построения приложений на LangChain. Ранее разработчики использовали императивные классы (например, LLMChain). Теперь LCEL предлагает декларативный, «пайп-подобный» синтаксис. Он использует оператор | (пайп), знакомый по Unix-шелл. Этот подход делает код более чистым, читаемым и, что важнее, компонуемым.
Однако LCEL — это не просто синтаксический сахар. Он добавляет критически важные production-ready возможности «из коробки».
Вот ключевые преимущества, которые дает LCEL.
- Потоковая передача (Streaming). Любая цепочка, созданная на LCEL, автоматически поддерживает стриминг. Это позволяет передавать ответ от LLM токен за токеном.
- Асинхронность (Async). LCEL предоставляет единый API для синхронного (invoke) и асинхронного (ainvoke) выполнения. Это необходимо для высоконагруженных приложений.
- Пакетная обработка (Batching). Фреймворк может автоматически обрабатывать запросы пакетами (batch). Это значительно повышает эффективность при больших нагрузках.
- Интеграция с LangSmith. LCEL-цепочки автоматически отправляют данные о трассировке. Это обеспечивает полную прозрачность выполнения для отладки.
Таким образом, LCEL стал мостом. Он превратил LangChain из инструмента для прототипирования в мощный production-фреймворк.
Экосистема LangChain: LangSmith и LangServe
По мере роста LC эволюционировал из простой библиотеки в полноценную платформу. Вокруг ядра фреймворка выросла мощная экосистема. Два ключевых продукта в ней — это LangSmith и LangServe.
LangSmith решает одну из главных проблем LLM-разработки: отладку и непредсказуемость. Приложения на LangChain, особенно агенты, могут быть сложными «черными ящиками». LangSmith — это платформа для трассировки, мониторинга и тестирования. Она визуализирует каждый шаг выполнения цепочки. Разработчик видит точные промпты, вызовы инструментов и задержки. Кроме того, LangSmith позволяет создавать наборы данных. На них можно запускать тесты для оценки качества ответов.
LangServe решает проблему развертывания (deployment). Часто разработчик создает отличную цепочку в Jupyter Notebook. Но перенос ее в production требует написания API-сервера. LangServe позволяет превратить любую LCEL-цепочку в готовый REST API. Это делается буквально одной командой. Он автоматически генерирует эндпоинты, обрабатывает параллельные запросы и следует стандартам API.
Ключевые альтернативы LangChain и их сравнение
LangChain доминирует в экосистеме, но он не является единственным решением. На рынке существуют мощные альтернативы. У каждой из них своя философия и фокус.
Рассмотрим основных конкурентов LangChain и их ключевые отличия.
- LlamaIndex. Это главный «конкурент», который часто используется вместе с LangChain. LlamaIndex имеет другой фокус. Если LangChain — это фреймворк для оркестрации, то LlamaIndex — это фреймворк для данных. LlamaIndex предлагает гораздо более продвинутые и сложные стратегии индексации. Он специализируется на RAG.
- Haystack (от deepset.ai). Это зрелый фреймворк. Он был популярен еще до бума LangChain. Haystack ориентирован на production-ready поисковые системы. Он использует концепцию явных «Пайплайнов» (Pipelines). Он отлично подходит для гибридного поиска (классический + векторный).
- Microsoft Semantic Kernel. Это «корпоративная» альтернатива от Microsoft. Его главное преимущество — нативная поддержка C# и Java. Это делает его идеальным выбором для интеграции в .NET или Java-стек. Его концепция «Планировщика» (Planner) похожа на агентов LangChain.
| Фреймворк | Основной фокус | Лучше всего подходит для… | Ключевая особенность |
| LangChain | Гибкая оркестрация (Chains, Agents) | Быстрое прототипирование, сложные агенты, Python-экосистема. | Гибкость и Интеграции |
| LlamaIndex | Индексация и поиск данных (RAG) | Задачи с интенсивным RAG, работа с большими объемами документов. | Оптимизация под RAG |
| Haystack | Production-ready Поисковые Пайплайны | Корпоративные QA-системы, семантический поиск по документам. | Стабильность в Поиске |
| Semantic Kernel | Интеграция в enterprise-логику | Microsoft/Azure стеки, .NET/C# проекты, B2B-приложения. | Поддержка C# / Java |
Выбор фреймворка зависит от задачи. LangChain остается лидером по гибкости, количеству интеграций и размеру сообщества.
Заключение
LangChain за короткое время прошел путь от простой библиотеки до комплексной платформы. Он фундаментально изменил ландшафт разработки. Фреймворк решил ключевую проблему LLM — их изоляцию. Он предоставил разработчикам «клей» для соединения моделей с внешним миром. Введение LCEL и экосистемы LangSmith решило проблемы отладки и развертывания. LangChain успешно перешел от инструмента для прототипов к production-ready решению. Сегодня он является основой для тысяч сложных, контекстно-зависимых и автономных ИИ-приложений.
Референсные ссылки
- [Обзор Microsoft Semantic Kernel] (https://learn.microsoft.com/ru-ru/semantic-kernel/overview/)
- [Документация LlamaIndex] (https://docs.llamaindex.ai/en/stable/)
- [Фреймворк Haystack от deepset] (https://docs.haystack.deepset.ai/docs)