 1032
1032 
Содержание
- Архитектура и ключевые компоненты LakeHouse
- Уровень хранения (Storage Layer)
- Уровень табличных форматов (Table Format Layer)
- Уровень метаданных (Metadata Layer)
- Уровень обработки данных (Processing Engine Layer)
- Уровень API и потребления (API and Consumption Layer)
- Принцип работы LakeHouse: От сырых данных к ценным инсайтам
- Бронзовый уровень (Bronze)
- Серебряный уровень (Silver)
- Золотой уровень (Gold)
- Сценарии использования и отличительные черты LakeHouse
- Взаимодействие с LakeHouse: Управление и обработка данных
- Сравнение LakeHouse с Data Warehouse и Data Lake
- Data Warehouse (Хранилище данных)
- Data Lake (Озеро данных)
- LakeHouse
- Преимущества и вызовы внедрения LakeHouse
- Заключение
- Референсные ссылки
Lakehouse — это архитектурный подход к хранению и обработке данных, который объединяет гибкость Data Lake и надёжность Data Warehouse, обеспечивая единый слой для аналитики, машинного обучения и управления данными без дублирования.
Архитектура Data LakeHouse представляет собой современный подход к управлению данными. Она объединяет лучшие характеристики озер данных (Data Lakes) и корпоративных хранилищ данных (Data Warehouses). Эта концепция была разработана для решения фундаментальной проблемы. Компании были вынуждены использовать две отдельные, разрозненные системы. Озера данных отлично подходили для хранения больших объемов сырых данных. Они использовались для задач машинного обучения. Хранилища данных, в свою очередь, обеспечивали структурированность и надежность для бизнес-аналитики. Такое разделение создавало информационные барьеры, усложняло архитектуру и увеличивало затраты.
LakeHouse устраняет эту двойственность. Он создает единую платформу для хранения, обработки и анализа всех типов данных. В основе лежит идея применения механизмов управления, характерных для хранилищ, непосредственно к недорогим и гибким объектным хранилищам, которые являются основой озер данных. Таким образом, data LakeHouse обеспечивает надежность, производительность и поддержку ACID-транзакций поверх неструктурированных, полуструктурированных и структурированных данных. Это позволяет организациям использовать единый источник правды как для традиционной BI-отчетности, так и для продвинутых задач в области искусственного интеллекта. В результате упрощается общая инфраструктура данных и ускоряется процесс получения ценных инсайтов.
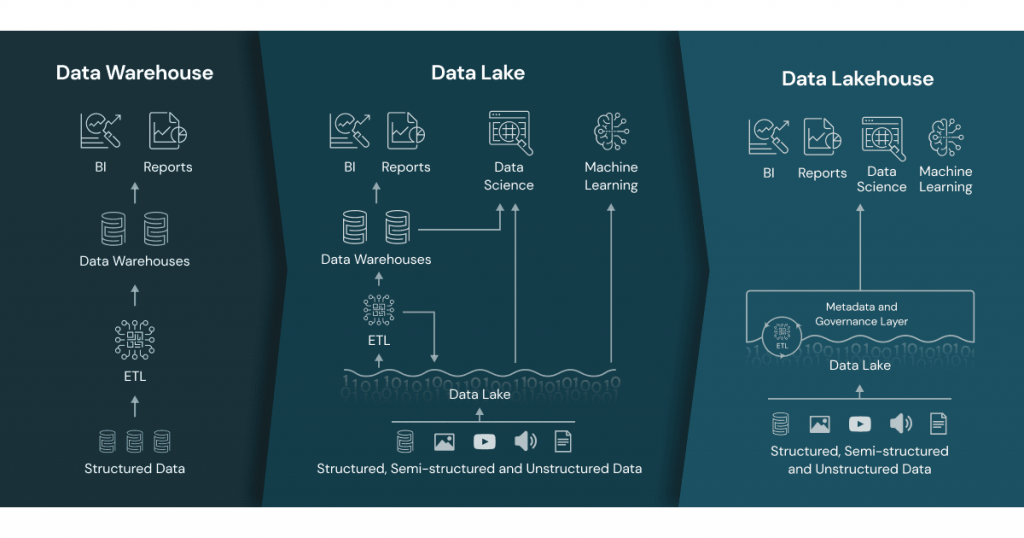
Архитектура и ключевые компоненты LakeHouse
Эффективность архитектуры LakeHouse обеспечивается ее многоуровневой структурой. Каждый уровень выполняет определенную функцию, создавая единую и надежную систему. Эта структура позволяет гибко управлять данными на всех этапах их жизненного цикла, от сырого хранения до конечного потребления. Давайте подробно рассмотрим каждый из этих компонентов.
Уровень хранения (Storage Layer)
Фундаментом для LakeHouse служат облачные объектные хранилища. К ним относятся Amazon S3, Azure Data Lake Storage Gen2 и Google Cloud Storage. Эти сервисы предлагают практически неограниченную масштабируемость и высокую долговечность данных при низкой стоимости. Важнейшей особенностью является разделение ресурсов хранения и вычислений. Это позволяет независимо масштабировать каждый компонент, оптимизируя затраты и производительность.
Уровень табличных форматов (Table Format Layer)
Это ядро инноваций в LakeHouse. Открытые табличные форматы добавляют функциональность баз данных поверх файлов в озере данных. Они обеспечивают управление транзакциями, версионность и надежность.
- Delta Lake: Разработанный компанией Databricks, этот формат обеспечивает ACID-транзакции, контроль версий (time travel) и унифицированную обработку пакетных и потоковых данных.
- Apache Iceberg: Созданный в Netflix, Iceberg управляет огромными таблицами как набором файлов. Он гарантирует корректность данных даже при параллельных операциях и поддерживает эволюцию схемы без перестройки таблиц.
- Apache Hudi: Разработанный в Uber, Hudi (Hadoop Upserts Deletes and Incrementals) эффективно управляет инкрементальными обновлениями данных, что критически важно для потоковых сценариев.

Уровень метаданных (Metadata Layer)
Этот уровень действует как централизованный каталог для всех данных в LakeHouse. Он хранит метаданные о таблицах, такие как схемы, версии и расположение файлов. Сервисы, например, AWS Glue Data Catalog или Unity Catalog от Databricks, предоставляют единую точку доступа к данным. Они также обеспечивают механизмы контроля доступа и управления данными.
Уровень обработки данных (Processing Engine Layer)
Здесь происходит выполнение запросов и трансформация данных. Различные вычислительные движки могут одновременно работать с одними и теми же данными благодаря открытым форматам.
- Apache Spark: Является де-факто стандартом для крупномасштабной обработки данных в экосистеме LakeHouse благодаря своей производительности и богатому API.
- Trino (ранее PrestoSQL) и Presto: Эти движки предназначены для выполнения быстрых интерактивных SQL-запросов напрямую к источникам данных, включая Lake House.
- Apache Flink: Специализируется на обработке потоковых данных с низкой задержкой, что делает его идеальным для аналитики в реальном времени.
Уровень API и потребления (API and Consumption Layer)
Верхний уровень архитектуры LH предоставляет инструменты для конечных пользователей. Он обеспечивает доступ к данным для аналитиков, дата-сайентистов и бизнес-пользователей. Доступ осуществляется через стандартные интерфейсы, такие как SQL для BI-инструментов (например, Tableau) и программные API (Python, R, Scala) для разработки моделей машинного обучения.
Практическая архитектура данных
Код курса
PRAR
Ближайшая дата курса
20 апреля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Принцип работы LakeHouse: От сырых данных к ценным инсайтам
Принцип работы архитектуры LakeHouse часто описывается с помощью методологии, известной как «Медальонная архитектура». Этот подход организует данные в несколько логических уровней, последовательно повышая их качество и готовность к использованию. Данные проходят путь от сырого состояния до структурированных и агрегированных наборов, готовых для анализа. Такой процесс обеспечивает прозрачность, надежность и воспроизводимость конвейеров обработки данных.
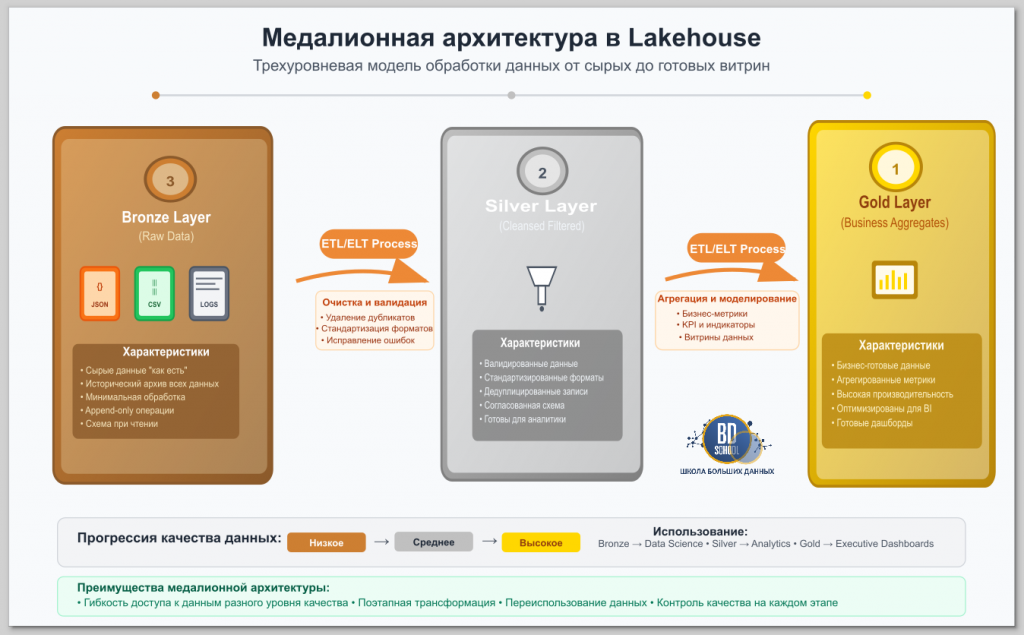
Бронзовый уровень (Bronze)
Это начальная точка для всех данных, поступающих в LakeHouse. На этом уровне данные хранятся в своем исходном, необработанном виде. Основная цель — создать точную копию данных из источников, будь то базы данных, логи приложений или потоки событий. Структура данных здесь максимально приближена к оригиналу. Это позволяет избежать потери информации и обеспечивает возможность повторной обработки в будущем при изменении бизнес-требований. Данные на бронзовом уровне обычно не подвергаются серьезной очистке, за исключением базовой валидации.
Серебряный уровень (Silver)
Данные с бронзового уровня проходят через процессы очистки, фильтрации и обогащения. В результате они попадают на серебряный уровень. Здесь данные приводятся к единому формату, исправляются ошибки и несоответствия, а также могут добавляться новые атрибуты из других источников. Таблицы на этом уровне уже более структурированы и готовы для решения конкретных аналитических задач. Например, разрозненные данные о клиентах из разных систем объединяются в единую клиентскую таблицу. Этот уровень часто служит источником для дата-сайентистов и аналитиков, которым нужны чистые, детализированные данные.
Золотой уровень (Gold)
Это финальный уровень, содержащий данные наивысшего качества. Они полностью готовы для конечного потребления. Таблицы на золотом уровне обычно представляют собой агрегированные витрины данных, оптимизированные под конкретные бизнес-задачи или BI-отчетность. Например, здесь могут храниться данные о продажах, агрегированные по дням, регионам и продуктам. Эти данные легко потребляются BI-инструментами, такими как Tableau или Power BI, и служат основой для ключевых бизнес-метрик. Благодаря высокой степени готовности, золотой уровень позволяет бизнес-пользователям работать с данными напрямую, без необходимости в сложных запросах.
Таким образом, «Медальонная архитектура» внутри LHouse создает логичный и управляемый поток данных, который гарантирует их высокое качество и доступность для широкого круга пользователей и приложений.
Сценарии использования и отличительные черты LakeHouse
Гибридная природа архитектуры LakeHouse делает ее универсальным решением для широкого спектга задач. Она эффективно устраняет барьеры между командами аналитиков и специалистов по данным. Это позволяет строить сквозные процессы, от сбора сырых данных до развертывания моделей машинного обучения, на единой платформе. Рассмотрим основные сценарии, где LakeHouse демонстрирует свои главные преимущества.
Бизнес-аналитика (BI) и корпоративная отчетность
Lake House позволяет выполнять высокопроизводительные SQL-запросы напрямую к данным в озере. Аналитики могут использовать привычные BI-инструменты, такие как Tableau или Microsoft Power BI, для создания интерактивных дашбордов и отчетов. При этом они работают с самыми актуальными и полными данными, хранящимися в золотых таблицах. Это исключает необходимость в переносе данных в отдельные, дорогостоящие хранилища.
Машинное обучение (ML) и наука о данных (Data Science)
Специалисты по данным получают прямой доступ ко всем данным, от сырых до очищенных, в одном месте. Они могут использовать такие инструменты, как Apache Spark, TensorFlow и PyTorch, для исследования данных, инжиниринга признаков и обучения моделей машинного обучения. Благодаря версионности данных, обеспечиваемой форматами вроде Delta Lake, они могут легко воспроизводить эксперименты и отслеживать происхождение данных (data lineage).
Обработка потоковых данных в реальном времени
Современные табличные форматы поддерживают унифицированную обработку как пакетных, так и потоковых данных (Lambda и Kappa архитектуры). Это позволяет создавать приложения для аналитики в реальном времени, например, для мониторинга мошеннических транзакций, анализа логов или отслеживания пользовательского поведения на веб-сайтах. Данные из потоков могут непрерывно записываться и сразу становиться доступными для запросов.
Создание единого источника правды (Single Source of Truth)
Объединяя все данные организации в одной системе, LakeHouse становится центральным источником достоверной информации. Это устраняет несогласованность данных между различными отделами и системами. Все пользователи, от бизнес-аналитиков до инженеров данных, работают с одними и теми же проверенными данными. Это повышает доверие к аналитике и упрощает управление данными и их безопасность.
Взаимодействие с LakeHouse: Управление и обработка данных
Работа с данными в Lake House осуществляется с помощью стандартных и широко распространенных инструментов. Основными способами взаимодействия являются декларативный язык SQL и программные API, доступные в языках программирования, таких как Python, Scala и R. Это позволяет как аналитикам, так и инженерам данных эффективно решать свои задачи на единой платформе. SQL идеально подходит для запросов и базовых манипуляций, в то время как программный доступ открывает возможности для сложных трансформаций и машинного обучения.
Ниже приведены примеры кода, иллюстрирующие основные операции с данными в среде Lake House с использованием SQL и Python (PySpark).
Использование SQL для манипуляции данными:
SQL остается основным языком для аналитиков. Платформы Lake House предоставляют мощную поддержку SQL, включая DML-операции (Data Manipulation Language) для изменения данных.
-- Создание таблицы для хранения информации о клиентах
CREATE TABLE customers (
customer_id INT,
first_name STRING,
last_name STRING,
email STRING,
registration_date DATE
) USING delta;
-- Вставка новых записей в таблицу
INSERT INTO customers
VALUES (101, 'Alice', 'Williams', 'alice@example.com', '2023-05-10'),
(102, 'Bob', 'Johnson', 'bob@example.com', '2023-06-15');
-- Обновление данных существующего клиента
UPDATE customers
SET email = 'robert.johnson@example.com'
WHERE customer_id = 102;
-- Удаление записи из таблицы
DELETE FROM customers
WHERE customer_id = 101;
-- Чтение данных из таблицы
SELECT * FROM customers;
Для сложных ETL-процессов и задач машинного обучения чаще используется программный доступ. Apache Spark, через его Python API (PySpark), является стандартом для таких операций.
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, year
# Инициализация Spark-сессии
spark = SparkSession.builder.appName("Lake HouseExample").getOrCreate()
# Чтение данных из таблицы 'customers' (серебряный уровень)
customers_df = spark.read.format("delta").table("customers")
# Пример трансформации: добавление колонки с годом регистрации
customers_with_year_df = customers_df.withColumn("registration_year", year(col("registration_date")))
# Фильтрация данных
recent_customers_df = customers_with_year_df.filter(col("registration_year") >= 2023)
# Вывод результата
recent_customers_df.show()
# Запись обработанных данных в новую таблицу (золотой уровень)
recent_customers_df.write.format("delta").mode("overwrite").saveAsTable("recent_customers_gold")
# Завершение Spark-сессии
spark.stop()
Эти примеры демонстрируют гибкость Lake House. Простые задачи решаются с помощью привычного SQL, а сложные — с помощью мощных инструментов обработки больших данных, таких как Spark.
Сравнение LakeHouse с Data Warehouse и Data Lake
Чтобы полностью понять ценность LakeHouse, необходимо сравнить эту архитектуру с ее предшественниками: традиционными хранилищами данных (Data Warehouse) и озерами данных (Data Lake). Каждая из этих систем была разработана для решения определенных задач, но имела свои ограничения. LakeHouse стремится объединить их сильные стороны, минимизируя недостатки.

Data Warehouse (Хранилище данных)
- Структура данных: Работает исключительно со структурированными, предварительно обработанными данными. Схема определяется на этапе записи (schema-on-write).
- Основные рабочие нагрузки: Оптимизирован для бизнес-аналитики (BI) и выполнения быстрых SQL-запросов. Отлично подходит для создания отчетов и дашбордов.
- Надежность данных: Высокая надежность благодаря поддержке ACID-транзакций, что гарантирует целостность данных.
- Производительность: Очень высокая производительность для аналитических запросов за счет строгой структуры, индексации и кэширования.
- Стоимость: Высокая стоимость хранения и вычислений из-за использования проприетарных форматов и тесной связи вычислений и хранения.
- Гибкость: Низкая гибкость. Не подходит для хранения неструктурированных данных (видео, текст, аудио) и для задач машинного обучения.
Data Lake (Озеро данных)
- Структура данных: Хранит данные любого типа — структурированные, полуструктурированные и неструктурированные — в их исходном формате. Использует подход схемы на этапе чтения (schema-on-read).
- Основные рабочие нагрузки: Идеально подходит для задач Data Science, машинного обучения и обработки больших объемов сырых данных.
- Надежность данных: Низкая надежность. Отсутствие поддержки транзакций часто приводит к проблемам с качеством данных и несогласованности, превращая озеро в «болото данных» (data swamp).
- Производительность: Производительность аналитических запросов обычно ниже, чем у хранилищ, так как данные не оптимизированы для этого.
- Стоимость: Очень низкая стоимость хранения благодаря использованию стандартных облачных объектных хранилищ.
- Гибкость: Очень высокая гибкость в хранении и обработке разнообразных данных.
LakeHouse
- Структура данных: Поддерживает все типы данных, как и Data Lake, но добавляет уровень управления метаданными и транзакционности.
- Основные рабочие нагрузки: Универсальная архитектура, поддерживающая как BI-аналитику, так и задачи машинного обучения и потоковую обработку на одной копии данных.
- Надежность данных: Высокая надежность. Реализует ACID-транзакции непосредственно над файлами в озере данных с помощью открытых табличных форматов (Delta Lake, Iceberg, Hudi).
- Производительность: Высокая производительность, сравнимая с хранилищами, благодаря механизмам оптимизации, таким как кэширование, индексация и компактизация данных.
- Стоимость: Низкая стоимость хранения, унаследованная от озер данных. Общая стоимость владения снижается за счет устранения необходимости в отдельных системах.
- Гибкость: Сочетает гибкость Data Lake с надежностью и производительностью Data Warehouse.
Таким образом, LakeHouse является эволюционным развитием, которое устраняет компромисс между гибкостью, стоимостью и надежностью, характерный для предыдущих архитектур.
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Преимущества и вызовы внедрения LakeHouse
Переход на архитектуру LakeHouse предлагает значительные выгоды для организаций, стремящихся к созданию современной и эффективной платформы данных. Однако, как и любая масштабная технологическая трансформация, этот процесс сопряжен с определенными сложностями и вызовами. Важно трезво оценивать как положительные стороны, так и потенциальные трудности перед началом внедрения.
Преимущества:
- Упрощенная архитектура и единый источник правды: LakeHouse устраняет необходимость поддерживать отдельные озера и хранилища данных. Это снижает сложность инфраструктуры, сокращает затраты на ETL-процессы и создает единый, достоверный источник данных для всей компании.
- Снижение общей стоимости владения (TCO): Использование недорогих облачных объектных хранилищ и открытых форматов данных значительно сокращает расходы. Отсутствие необходимости дублировать данные в нескольких системах также приводит к экономии.
- Поддержка разнообразных рабочих нагрузок: Одна и та же платформа может использоваться для BI-аналитики, машинного обучения и потоковой обработки. Это способствует лучшему взаимодействию между командами аналитиков, инженеров и специалистов по данным.
- Открытость и гибкость: В основе Lake House лежат открытые стандарты и форматы (например, Parquet, Delta Lake, Iceberg). Это предотвращает привязку к одному поставщику (vendor lock-in) и обеспечивает широкую совместимость с различными инструментами и движками обработки.
- Высокая надежность и качество данных: Внедрение ACID-транзакций и механизмов управления схемами непосредственно в озере данных решает проблему «болота данных», гарантируя целостность и высокое качество данных.
Вызовы и недостатки:
- Сложность внедрения и настройки: Развертывание и правильная конфигурация архитектуры LakeHouse требуют глубоких технических знаний. Необходимо правильно выбрать и настроить все компоненты: от табличного формата до движка обработки и системы каталогизации.
- Необходимость в новых компетенциях: Работа с LakeHouse требует от команд новых навыков. Инженерам данных и аналитикам нужно освоить новые инструменты и подходы, такие как Apache Spark и современные табличные форматы.
- Относительная новизна технологии: Экосистема LakeHouse все еще активно развивается. Некоторые инструменты и функции могут быть менее зрелыми по сравнению с традиционными хранилищами данных, которые существуют на рынке десятилетиями.
- Потенциальные проблемы с производительностью: Хотя LH может достигать высокой производительности, это требует тщательной оптимизации. Неправильное проектирование таблиц, партиционирование или управление мелкими файлами может привести к деградации скорости выполнения запросов.
- Управление безопасностью и доступом: В единой системе, где хранятся все данные, от сырых до конфиденциальных, крайне важно правильно настроить гранулярный контроль доступа и политики безопасности. Это может быть сложной задачей в больших организациях.
Заключение
В заключение, архитектура LakeHouse представляет собой не просто технологическое усовершенствование, а фундаментальный сдвиг в парадигме управления данными. Она успешно решает исторический компромисс между гибкостью озер данных и надежностью хранилищ, предлагая единую, экономически эффективную платформу. Объединяя поддержку BI, машинного обучения и потоковой аналитики на одной копии данных, LakeHouse разрушает информационные барьеры внутри организаций. Это позволяет компаниям ускорить инновации и принимать решения на основе полных и достоверных данных. Несмотря на определенные вызовы, связанные с новизной технологии и необходимостью адаптации, стратегические преимущества делают LakeHouse ключевым элементом современной экосистемы данных. Можно с уверенностью сказать, что эта архитектура будет определять будущее аналитических платформ на долгие годы вперед.
Референсные ссылки
- Технический обзор архитектуры от AWS https://aws.amazon.com/blogs/big-data/build-a-data-Lake House-on-aws/
- Сравнение табличных форматов от Dremio https://www.dremio.com/learn/data-lake/table-formats
- Статья Мартина Фаулера о шаблонах данных https://martinfowler.com/articles/data-monolith-to-mesh.html
- Обзор Apache Iceberg от его создателей https://iceberg.apache.org/