 338
338 
Содержание
- Архитектура и Ключевые особенности
- Принцип работы и Механизм
- Главные игроки: Redis, Memcached, ZooKeeper
- Redis: Швейцарский нож
- Memcached: Простой молоток
- Apache ZooKeeper: Дирижер оркестра
- Сценарии использования (Use Cases)
- Взаимодействие и Код (Python + Redis)
- Шаг 1: Подготовка окружения (Запуск сервера Key Value store REDIS )
- Шаг 2: Python Script
- Проблема вытеснения данных (Eviction Policies)
- Теорема CAP в контексте хранения Ключ-Значение
- Заключение
- Референсные ссылки:
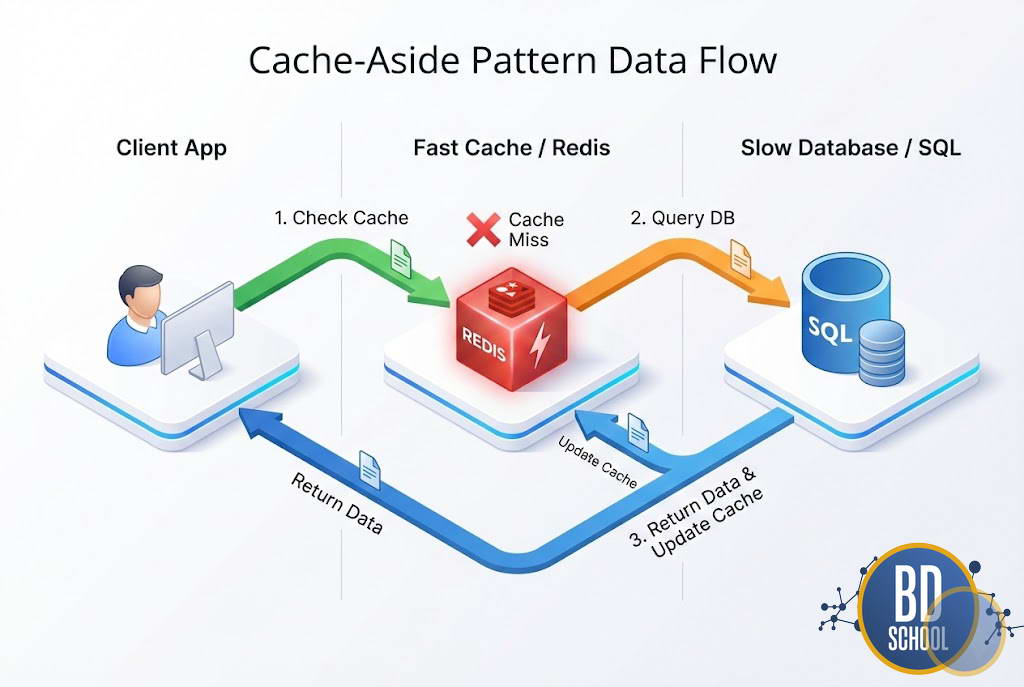
Key-Value Store (хранилище «ключ-значение») — это модель хранилища данных, в которой информация сохраняется в виде пар «ключ–значение», обеспечивающих быстрый доступ к данным по уникальному ключу, простоту масштабирования и минимальные ограничения на структуру значения.
Представьте гардероб в театре. Номерок — это Ключ. Ваше пальто — это Значение. Вы отдаете номерок, гардеробщик мгновенно находит пальто. Ему неважно, что лежит в карманах (структура данных). Ему важна только скорость выдачи. Именно так работают Key-Value хранилища. Они жертвуют сложностью запросов ради экстремальной производительности.
В современной Big Data архитектуре реляционные базы данных часто не справляются с потоком запросов. Им требуется время на проверку схемы, связей и блокировок. Хранилища «ключ-значение» убирают эти барьеры. Они обеспечивают доступ к данным за константное время. Это делает их незаменимыми для кэширования, хранения сессий и обработки событий в реальном времени.
Архитектура и Ключевые особенности
В основе архитектуры лежит предельно простая модель данных. Она состоит всего из двух элементов, что отличает её от табличных баз данных. Эта простота позволяет масштабировать систему горизонтально практически бесконечно.
Ключевые компоненты архитектуры включают:
- Ключ (Key): Уникальный идентификатор записи. Это может быть строка, путь к файлу или хэш. По ключу происходит поиск.
- Значение (Value): Сами данные. Для базы данных это часто «черный ящик». Хранилищу все равно, лежит там число, JSON-объект или картинка.
- Пространство имен (Bucket): Логический контейнер для группировки ключей. Аналог таблицы в реляционных базах, но без жесткой структуры.
Эта архитектура называется Schema-less (без схемы). Вам не нужно заранее объявлять типы данных. Вы можете сохранить число по одному ключу и сложный объект по другому.
Другая важная особенность — это использование Хэш-таблиц. База данных вычисляет хэш от ключа. Этот хэш указывает на конкретный адрес в памяти. Благодаря этому сложность поиска составляет $O(1)$. Это означает, что время поиска не зависит от общего количества записей в базе. Поиск среди миллиона записей и среди миллиарда займет одинаковое время.
Таким образом, архитектура Key-Value хранилищ заточена под одну цель — скорость. Отказ от связей (JOIN) и транзакций ACID (в их полном понимании) — это осознанная плата за производительность.
Принцип работы и Механизм
Механика работы Key-Value хранилищ строится на минимализме операций. В отличие от SQL с его богатым языком запросов, здесь правит бал простота. Взаимодействие с базой напоминает работу со словарем (dictionary) в Python или Map в Java.
Базовый набор операций сводится к концепции CRUD, но в урезанном виде:
- PUT (Set): Записать значение по ключу. Если ключ существует, значение перезаписывается.
- GET: Получить значение по ключу. Это самая частая операция.
- DELETE: Удалить пару ключ-значение.
Большинство высокопроизводительных хранилищ (например, Redis или Memcached) держат данные в оперативной памяти (In-Memory). Доступ к оперативной памяти в тысячи раз быстрее доступа к жесткому диску. Однако память энергозависима. При перезагрузке сервера данные исчезнут. Чтобы решить эту проблему, используются механизмы персистентности (Snapshots или AOF-логи), которые периодически сбрасывают данные на диск.
Для обработки огромных объемов данных применяется Партиционирование (Sharding). Данные разбиваются на части и распределяются по разным узлам кластера.
Процесс распределения обычно выглядит так:
- Хэширование: Система берет ключ и применяет к нему хэш-функцию.
- Выбор узла: Полученный хэш делится по модулю на количество серверов.
- Маршрутизация: Клиент обращается сразу к нужному серверу, минуя центральный координатор.
Этот подход позволяет линейно наращивать мощность. Нужно больше памяти? Просто добавьте новые узлы в кластер. Умные клиенты или прокси-серверы сами поймут, куда отправлять запросы.
Главные игроки: Redis, Memcached, ZooKeeper
На рынке существует множество решений, но три из них стали стандартами де-факто. Каждый инструмент занимает свою нишу и решает специфические задачи. Нельзя просто заменить один другим без анализа требований.
Redis: Швейцарский нож
Redis (Remote Dictionary Server) — самое популярное Key-Value хранилище. Его главная особенность — он знает, что лежит внутри «Значения». Redis поддерживает сложные структуры данных: списки, множества, хэш-таблицы и даже гео-индексы. Он умеет выполнять операции над этими данными на стороне сервера. Это позволяет использовать его не только как кэш, но и как брокер сообщений или базу данных для аналитики. Redis может сохранять данные на диск, обеспечивая надежность.
Memcached: Простой молоток
Memcached — это чистый кэш объектов в оперативной памяти. Он проще, чем Redis. Он поддерживает только строковый тип данных (или сериализованные объекты). Memcached идеально подходит для кэширования результатов тяжелых SQL-запросов или рендеринга HTML-страниц. Его архитектура многопоточна, что позволяет эффективно использовать мощные многоядерные процессоры. Однако он не умеет сохранять данные на диск. Перезагрузка сервера означает полную потерю кэша (эффект «холодного старта»).
Apache ZooKeeper: Дирижер оркестра
ZooKeeper технически является Key-Value хранилищем, но его назначение иное. Он не предназначен для хранения больших объемов данных пользователей. Его задача — координация распределенных систем. Он хранит конфигурации, информацию о статусе узлов и блокировки. ZooKeeper гарантирует строгую согласованность и надежность. Если Redis — это про скорость, то ZooKeeper — это про надежность и порядок в кластере.
Выбор между ними зависит от задачи. Нужен сложный кэш и структуры данных? Берите Redis. Нужно простое кэширование HTML? Memcached подойдет. Строите распределенную систему? Вам понадобится ZooKeeper.
Сценарии использования (Use Cases)
Key-Value хранилища применяются везде, где важна низкая задержка (low latency). Они снимают нагрузку с основных реляционных баз данных. Рассмотрим типовые паттерны использования в продакшене.
Основные сценарии включают:
- Кэширование данных: Самый популярный кейс. Результат тяжелого запроса к MySQL сохраняется в Redis. При следующем запросе данные берутся из памяти мгновенно.
- Управление сессиями: Данные о логине пользователя и его корзине в интернет-магазине. Эти данные нужны часто, но живут недолго.
- Счетчики и аналитика: Подсчет лайков, просмотров или кликов в реальном времени. Реляционные базы плохо переносят частые обновления одной строки (блокировки). KV-хранилища делают инкремент атомарно и быстро.
- Корзина покупок: Даже если пользователь не залогинен, его корзина должна сохраняться быстро и надежно до момента оплаты.
Специфическим сценарием является хранение профилей пользователей в играх или социальных сетях. Быстрый доступ по ID пользователя критичен для отрисовки интерфейса. Здесь Key-Value выступает как «горячее» хранилище профиля.
Также стоит упомянуть Deduplication (дедупликацию). Хранение хэшей уже обработанных файлов или сообщений позволяет мгновенно проверять дубликаты. Это критично для систем обработки потоковых данных.
Практическое применение Big Data аналитики для решения бизнес-задач
Код курса
PRUS
Ближайшая дата курса
20 апреля, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Взаимодействие и Код (Python + Redis)
Чтобы работать с Key-Value хранилищем, нам нужно два компонента: запущенный сервер и клиентская библиотека (драйвер). Рассмотрим процесс на примере самой популярной связки: Redis и Python.
Шаг 1: Подготовка окружения (Запуск сервера Key Value store REDIS )
Перед написанием кода нужно поднять сервер Redis. Самый простой способ сделать это без установки лишнего софта в систему — использовать контейнеры.
Вариант А: Docker (Рекомендуемый) Если у вас установлен Docker, выполните одну команду в терминале. Она скачает официальный образ и запустит Redis на стандартном порту.
docker run --name local-redis -p 6379:6379 -d redis
Вариант Б: WSL (Windows Subsystem for Linux) Если вы используете Ubuntu внутри Windows, установка выполняется через стандартный пакетный менеджер.
# Обновляем списки пакетов и ставим сервер sudo apt update sudo apt install redis-server # Запускаем службу sudo service redis-server start
Теперь ваш локальный сервер Redis готов к работе и слушает порт 6379.
Шаг 2: Python Script
Python имеет отличную библиотеку redis-py. Она предоставляет интерфейс, максимально похожий на нативные команды Redis. Сначала установите её:
#--запускаем venv python3 -m venv venv/ source venv/bin/activate pip3 install redis
Ниже приведен пример базового взаимодействия. Мы подключимся к локальному серверу, запишем данные (SET), прочитаем их (GET) и используем механику TTL.
import redis
import time
# 1. Подключение
# decode_responses=True позволяет получать строки вместо байтов (b'...')
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
try:
r.ping()
print("✅ Соединение с Redis установлено!")
except redis.ConnectionError:
print("❌ Ошибка: Не удалось подключиться. Проверьте Docker.")
exit()
# --- СЦЕНАРИЙ 1: Обычная запись ---
print("\n--- [1] Запись данных ---")
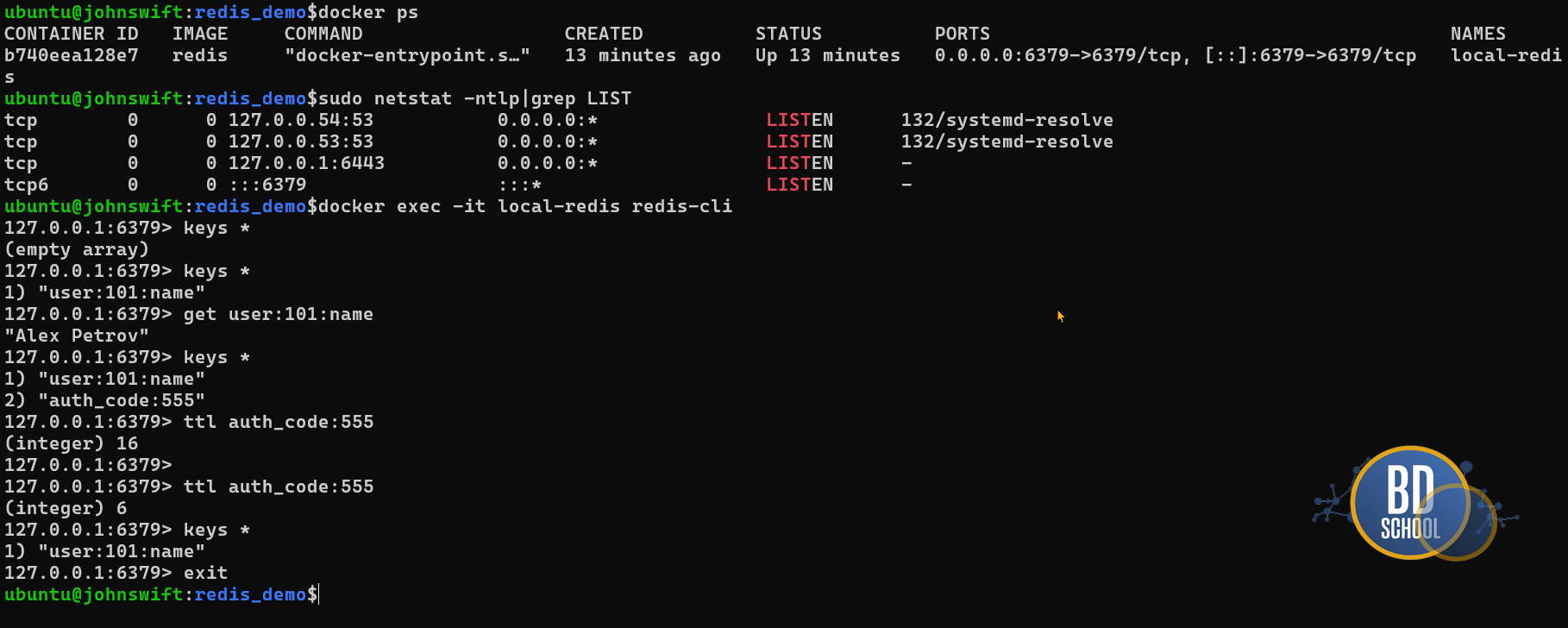
r.set('user:101:name', 'Alex Petrov')
print("Python: Ключ 'user:101:name' записан.")
# ПАУЗА ДЛЯ ПРОВЕРКИ
print("\n🛑 Скрипт на паузе. Откройте новый терминал и введите команду:")
print("👉 docker exec -it local-redis redis-cli get user:101:name")
input("Нажмите [Enter] в этой консоли, чтобы продолжить...")
# --- СЦЕНАРИЙ 2: TTL (Время жизни) ---
print("\n--- [2] Тест TTL (Time To Live) ---")
# Записываем ключ, который проживет 30 секунд
r.setex('auth_code:555', 30, 'SUPER_SECRET')
print("Python: Временный ключ 'auth_code:555' создан на 30 секунд.")
print("\n🛑 Скрипт на паузе. Быстро проверьте ключ в терминале:")
print("👉 docker exec -it local-redis redis-cli ttl auth_code:555")
print("(Вы увидите, как уменьшается число секунд)")
input("Нажмите [Enter], когда будете готовы проверить удаление...")
print("Python: Ждем остаток времени...")
time.sleep(5) # Небольшая задержка для надежности
val = r.get('auth_code:555')
if val is None:
print("✅ Успех: Ключ исчез (вернулся None). Redis удалил его автоматически.")
else:
print(f"⚠️ Ключ все еще жив: {val}. Возможно, вы нажали Enter слишком быстро.")
# --- СЦЕНАРИЙ 3: Атомарный счетчик ---
print("\n--- [3] Инкремент ---")
r.set('counter', 0)
r.incr('counter')
r.incr('counter')
print(f"Python: Значение счетчика внутри скрипта: {r.get('counter')}")
print("\n🎉 Тест завершен.")
Воспользуемся проверкой подклчением к Redis через CLI
Этот код демонстрирует простоту API. Нет сложных схем или миграций. Вы просто запускаете контейнер и сразу начинаете сохранять структуры данных.
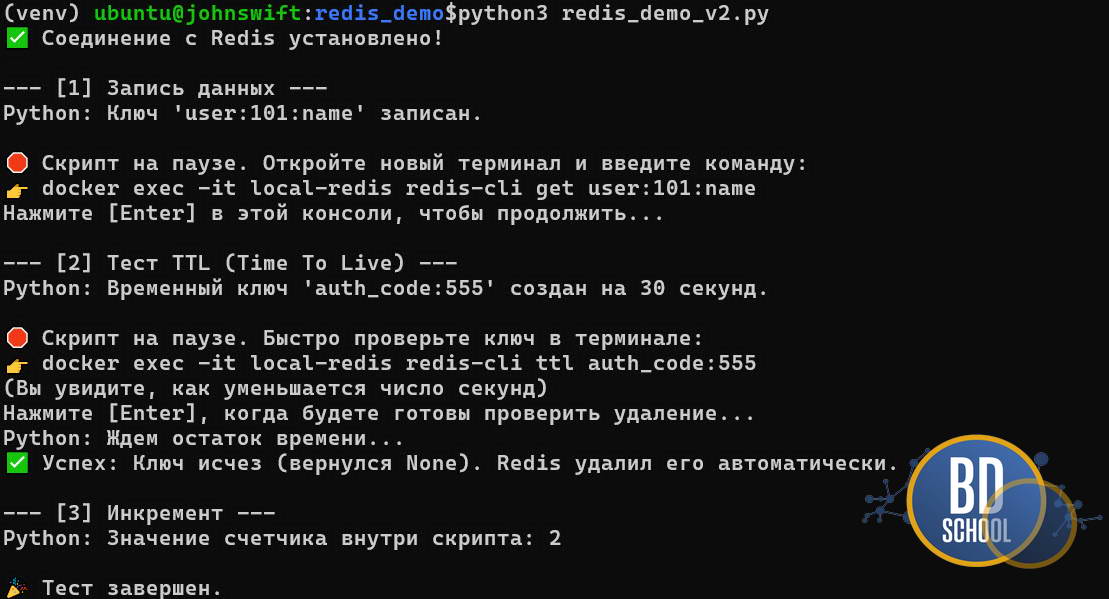
Важный момент в примере — использование TTL (Time To Live). Это время жизни ключа. В реляционных базах удаление устаревших данных — сложная процедура (нужны скрипты очистки).
В Key-Value хранилищах вы просто задаете время жизни при записи. База сама удалит «протухшие» данные. Это идеальный механизм для кэша и временных кодов доступа.
Проблема вытеснения данных (Eviction Policies)
Оперативная память — ресурс дорогой и ограниченный. Что происходит, когда место в Redis или Memcached заканчивается? Хранилище должно решить, какие данные удалить, чтобы записать новые. Этот процесс регулируется политиками вытеснения (Eviction Policies). Без правильной настройки политики ваш кэш может перестать принимать новые записи или удалить что-то важное.
Существует несколько стратегий, которые выбираются в зависимости от бизнес-логики:
- LRU (Least Recently Used): Удаляются ключи, которые дольше всего не использовались. Это самый популярный алгоритм для кэширования. Логика проста: если данные нужны часто, они останутся.
- LFU (Least Frequently Used): Удаляются ключи, к которым обращались реже всего за все время. Полезно, если у вас есть данные, которые нужны редко, но стабильно.
- TTL (Volatile): Удаляются только те ключи, у которых установлен срок жизни. Ключи без срока жизни (персистентные) не трогаются. Если место кончилось, а удалять нечего, вернется ошибка.
- Random: Удаляются случайные ключи. Это работает быстрее, так как не нужно тратить ресурсы на сортировку и анализ использования.
Выбор политики критичен. Например, для кэша веб-страниц идеально подходит allkeys-LRU (удалять любые старые ключи). Если же вы используете Redis как базу данных для сессий, лучше выбрать volatile-lru, чтобы случайно не удалить вечные настройки системы, у которых нет тайм-аута.
Таким образом, понимание Eviction Policies спасает от внезапных падений приложения при пиковых нагрузках.
Теорема CAP в контексте хранения Ключ-Значение
При проектировании распределенных систем мы всегда упираемся в ограничения CAP-теоремы. Она гласит, что распределенная база данных может обеспечить только два свойства из трех: Согласованность (Consistency), Доступность (Availability) и Устойчивость к разделению (Partition Tolerance). Key-Value хранилища ярко иллюстрируют этот компромисс.
Поскольку распределенные системы обязаны быть устойчивы к разрывам сети (P), выбор всегда стоит между CP и AP:
CP-системы (Consistency + Partition Tolerance): Гарантируют, что данные во всех узлах одинаковы. Если связь между узлами потеряна, система заблокирует запись, чтобы избежать конфликтов.
- Пример: Redis (в конфигурации с одним мастером) или HBase. Они предпочитают отказать в обслуживании, но не отдать устаревшие данные.
AP-системы (Availability + Partition Tolerance): Гарантируют, что система ответит на запрос, даже если часть узлов недоступна. Однако данные могут быть устаревшими (eventual consistency).
- Пример: Amazon DynamoDB, Riak или Cassandra. Они принимают запись на любой живой узел. Синхронизация происходит позже.
Для Key-Value хранилищ выбор зависит от критичности данных. Если это счетчик лайков, потеря пары кликов не страшно — важнее доступность (AP). Если это финансовая транзакция или блокировка (как в ZooKeeper), важна строгая согласованность (CP). Понимание этого компромисса позволяет архитекторам правильно выбирать инструмент под задачу, не ожидая от системы невозможного.
Практическая архитектура данных
Код курса
PRAR
Ближайшая дата курса
20 апреля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Заключение
Key-Value хранилища — это скоростные болиды в мире баз данных. Они жертвуют функциональностью SQL ради экстремальной производительности и простоты масштабирования. Мы выяснили, что их архитектура напоминает огромную хэш-таблицу, а сценарии использования охватывают всё: от кэширования до аналитики в реальном времени.
Выбирайте Key-Value, когда:
- Вам нужна минимальная задержка (миллисекунды).
- Данные не имеют сложной структуры или связей.
- Вам нужно масштабироваться на огромные объемы трафика.
Не используйте их, когда требуются сложные выборки, транзакции между множеством записей или строгая реляционная модель. Redis, Memcached и их аналоги — это мощные инструменты, которые при правильном использовании становятся сердцем современной Big Data инфраструктуры.
Референсные ссылки:
- [Redis Documentation: Data Types and Abstractions] (https://redis.io/docs/data-types/)
- [AWS Whitepaper: Key-Value Database Definition] (https://aws.amazon.com/nosql/key-value/)
- [System Design Primer: Key-Value Stores] (https://github.com/donnemartin/system-design-primer)
- [Apache ZooKeeper Internals] (https://zookeeper.apache.org/doc/current/zookeeperOver.html)