 570
570 
Содержание
- Детальная архитектура KAG
- База Знаний (Knowledge Base): Почему Графы?
- Модуль Генерации (LLM)
- Модуль Синтеза (Augmentation Engine)
- Принцип работы KAG: Глубокое погружение
- KAG против RAG: Фундаментальный сравнительный анализ
- Что такое RAG?
- Ключевые различия
- Сравнительная таблица: KAG vs. RAG
- Гибридные подходы: GraphRAG
- Практические сценарии использования KAG
- Практическое руководство по реализации KAG
- Моделирование и создание Графа Знаний
- Настройка LLM и фреймворков
- Оркестрация запроса (Расширенный пример)
- Преимущества и стратегические вызовы KAG
- Будущее гибридного ИИ - Роль KAG
- Заключение
- Референсные ссылки
KAG (Knowledge-Augmented Generation), или Генерация, Дополненная Знаниями, — это передовая архитектура систем искусственного интеллекта. Ее суть заключается в том, что Большая Языковая Модель (LLM) при создании ответа активно использует внешнюю, структурированную базу знаний.
Стандартные LLM обучаются на гигантских, но «замороженных» объемах данных. Их знания статичны и ограничены датой последнего обучения. Это приводит к двум фундаментальным проблемам. Во-первых, модели могут «галлюцинировать», то есть уверенно генерировать ложную или бессмысленную информацию. Во-вторых, они ничего не знают о частных, закрытых данных конкретной организации.
KAG решает эти проблемы. Эта технология выступает в роли моста между «творческим» языковым ядром LLM и «фактическим» миром проверенных данных. Вместо того чтобы полагаться только на свою «память», модель в реальном времени делает запрос к внешнему источнику. Таким образом, KAG привязывает LLM к фактической реальности, обеспечивая точность, актуальность и достоверность ответов.
Детальная архитектура KAG
Система KAG — это не единый продукт, а гибридная архитектура. Ее успешная работа зависит от слаженного взаимодействия трех ключевых компонентов.
База Знаний (Knowledge Base): Почему Графы?
Ядром KAG и его главным отличием является источник данных. В этой роли почти всегда выступает Граф Знаний (Knowledge Graph). В отличие от SQL-таблиц или текстовых документов, графы хранят информацию в виде сущностей (узлы) и связей (ребра).
Такая структура идеально подходит для KAG по нескольким причинам. Графы великолепно моделируют сложные, неоднозначные связи реального мира. Они позволяют системе не просто находить факты, а понимать контекст и выполнять многошаговые логические выводы (multi-hop reasoning). Например, граф легко отвечает на запрос «Найти всех инженеров, которые работали над проектом ‘Альфа’ и подчиняются менеджеру, который работает в лондонском офисе».
Модуль Генерации (LLM)
В архитектуре KAG Большая Языковая Модель выполняет две ключевые роли. Во-первых, она выступает как «интерпретатор» запроса пользователя, помогая Модулю Синтеза понять, что именно нужно найти. Во-вторых, она является «генератором» финального ответа. Получив точные, но «сухие» факты из графа, LLM облекает их в связный, понятный и естественно звучащий текст.
Модуль Синтеза (Augmentation Engine)
Это «мозг» и главный оркестратор всей KAG — операции. Именно этот компонент связывает пользователя, граф и LLM в единую систему. Его задачи включают:
- Понимание запроса: Анализ того, что спросил пользователь.
- Трансляция: Перевод запроса на естественном языке в формальный язык запросов к графу (например, Cypher для Neo4j или SPARQL).
- Формирование промпта: Сбор извлеченных из графа фактов и их «упаковка» в расширенный промпт, который будет понятен для LLM.
Принцип работы KAG: Глубокое погружение
Процесс KAG можно разбить на четкую последовательность шагов. Этот цикл гарантирует, что ответ модели будет не выдуманным, а основанным на фактах.
Шаг 1: Анализ намерения (Intent Analysis) Пользователь задает вопрос, например: «Какие побочные эффекты у препарата ‘X’ при взаимодействии с ‘Y’?» Модуль Синтеза определяет, что это не общий вопрос, а запрос на конкретные факты.
Шаг 2: Идентификация сущностей (Entity Recognition) Система выделяет в запросе ключевые сущности: «Препарат X» и «Препарат Y», а также тип искомой связи: «побочные эффекты» и «взаимодействие».
Шаг 3: Запрос к Графу (Graph Query) Модуль Синтеза преобразует эти сущности и связи в формальный запрос к Графу Знаний. Запрос может выглядеть так: (Препарат X)-[:ВЗАИМОДЕЙСТВУЕТ_С]->(Препарат Y), (Препарат X)-[:ИМЕЕТ_ПОБОЧНЫЙ_ЭФФЕКТ]->(Эффект). Граф выполняет этот запрос и возвращает точный «подграф» — набор фактов, описывающих это взаимодействие.
Шаг 4: Сериализация фактов (Fact Serialization) Граф возвращает данные в структурированном виде (например, JSON). Этот формат непонятен LLM. Поэтому Модуль Синтеза «сериализует» эти факты, превращая их в простой текст. Например: «Факт 1: ‘Препарат X’ взаимодействует с ‘Препарат Y’. Факт 2: ‘Препарат X’ имеет побочный эффект ‘Головная боль'».
Шаг 5: Синтез ответа (Augmented Generation) LLM получает расширенный промпт, который содержит исходный вопрос пользователя и набор сериализованных фактов. Теперь задача LLM — сгенерировать ответ, строго основываясь на этих фактах. В результате получается точный и безопасный ответ.
KAG против RAG: Фундаментальный сравнительный анализ
Для понимания KAG крайне важно четко разграничить его с более известной технологией — RAG (Retrieval-Augmented Generation).
Что такое RAG?
RAG, или Генерация, Дополненная Извлечением, — это также метод борьбы с галлюцинациями. Однако RAG работает с неструктурированными данными: документами (PDF, .txt, .md), веб-страницами и так далее.
Механика RAG основана на векторном поиске. Весь корпус документов заранее разбивается на «чанки» (куски текста) и векторизуется. Когда пользователь задает вопрос, RAG находит наиболее «похожие» по смыслу куски текста и передает их в LLM в качестве контекста.
Ключевые различия
Ключевое отличие KAG и RAG — в источнике и структуре данных.
- Источник данных: RAG работает с неструктурированным текстом. KAG работает со структурированными графами знаний.
- Механика: RAG ищет похожее (similarity search). KAG выполняет точный запрос и логический вывод (precise query & inference).
- Результат извлечения: RAG возвращает «чанк» текста, который может содержать ответ. KAG возвращает точный факт или набор связей.
RAG отвечает на вопрос «Что говорится в моих документах на эту тему?». KAG отвечает на вопрос «Каковы точные факты и связи между этими сущностями?».
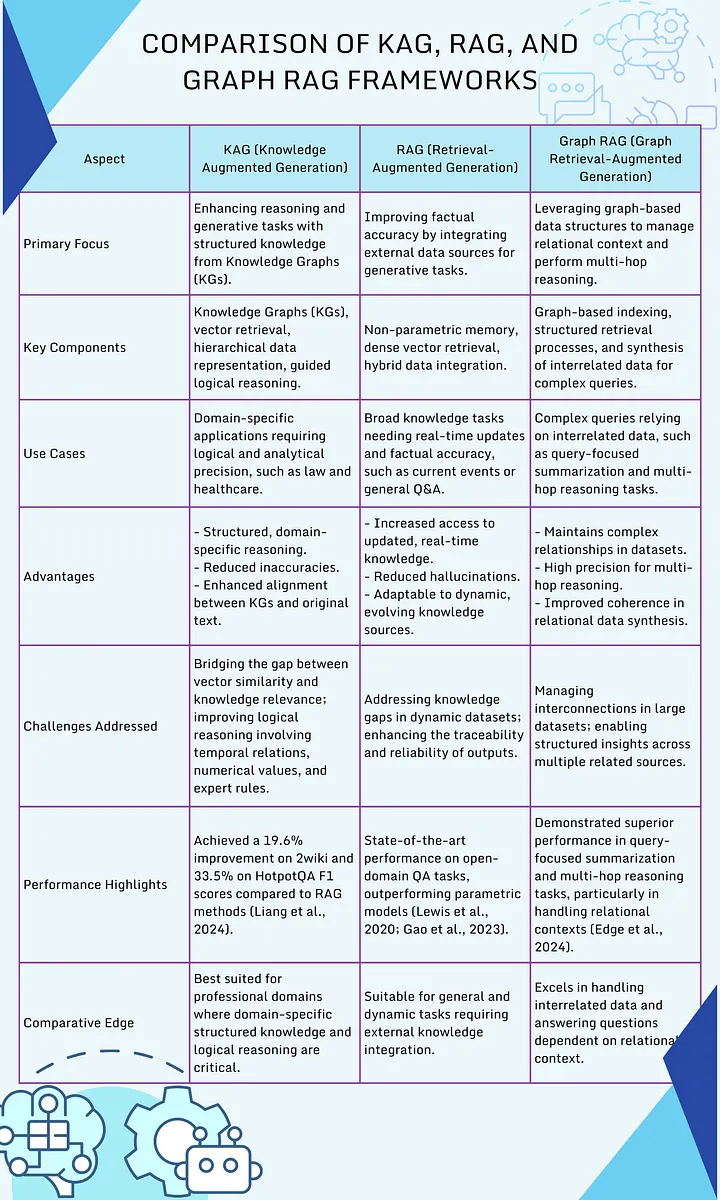
Сравнительная таблица: KAG vs. RAG
| Параметр | RAG (Retrieval-Augmented Generation) | KAG (Knowledge-Augmented Generation) |
| Тип данных | Неструктурированные (текст, документы) | Структурированные (Графы Знаний) |
| Механизм | Векторный поиск по сходству | Точный запрос к графу, логический вывод |
| Точность | Умеренная (зависит от качества чанка) | Очень высокая, основана на фактах |
| Сценарии | Q&A по документации, чат-боты, поиск | Аналитика связей, сложные Q&A, «объяснимый» ИИ |
| Сложность | Относительно просто внедрить | Высокая (требует создания Графа Знаний) |
Гибридные подходы: GraphRAG
Стоит отметить, что индустрия активно движется к гибридным решениям. Появляются системы GraphRAG, которые используют графы для навигации по неструктурированным документам. Они объединяют мощь обеих методологий.
Практические сценарии использования KAG
Благодаря своей точности, KAG идеально подходит для критически важных задач, где цена ошибки высока.
Корпоративные «Базы Знаний 2.0»
Представьте HR-ассистента. Запрос «Какие сотрудники говорят по-испански?» — это RAG. Запрос «Кто из менеджеров в отделе R&D имеет опыт в Python, свободен для нового проекта и ранее не работал с клиентом ‘Z’?» — это KAG. Только граф может эффективно обработать такой сложный запрос на связи.
Финансовый анализ и Compliance
KAG незаменим для выявления сложных, не очевидных рисков. Системы на основе графов могут анализировать сети владения компаниями, выявлять аффилированных лиц и обнаруживать схемы отмывания денег, которые невозможно увидеть в плоских таблицах.
Медицина и Фармацевтика
AI-ассистент для врача, использующий KAG, может дать мгновенный и точный ответ о взаимодействии лекарств, основываясь на графе медицинских исследований. Это также ускоряет разработку новых препаратов, позволяя анализировать связи между генами, белками и болезнями.
Управление цепочками поставок
KAG позволяет задавать сложные вопросы о рисках. Например: «Какие из моих заказов зависят от поставщика ‘X’ из региона ‘Y’, который пострадал от стихийного бедствия, и какие альтернативные поставщики у меня есть?»
ИИ-агенты для оптимизации бизнес-процессов
Код курса
AGENT
Ближайшая дата курса
18 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
Практическое руководство по реализации KAG
Внедрение KAG — это комплексная задача, включающая инженерию данных, MLOps и разработку ПО.
Моделирование и создание Графа Знаний
Это самый сложный и важный этап. Нельзя просто «загрузить» данные. Необходимо спроектировать онтологию — модель ваших данных (какие будут сущности, какие связи). Для этого используются специализированные графовые СУБД, такие как Neo4j, NebulaGraph или FalkorDB. Данные из разных источников (SQL, API, CSV) извлекаются, трансформируются и загружаются в граф (ETL-процесс).
Настройка LLM и фреймворков
Для оркестрации всего процесса используются фреймворки, такие как LangChain или LlamaIndex. Они предоставляют готовые компоненты («чейны») для интеграции LLM с различными источниками данных. Вы выбираете LLM (например, GPT-4 через API или локальную модель) и настраиваете ее подключение.
Оркестрация запроса (Расширенный пример)
Фреймворк LangChain позволяет создать цепочку (Chain), которая реализует логику KAG.
# ПРЕДУПРЕЖДЕНИЕ: Этот код является концептуальной иллюстрацией
# и требует установленных библиотек langchain, langchain-community, neo4j
import os
from langchain_community.graphs import Neo4jGraph
from langchain.chains import GraphCypherQAChain
from langchain_openai import ChatOpenAI
# 1. Установка соединения с Графом Знаний
# Предполагается, что Neo4j уже развернут и содержит данные
graph = Neo4jGraph(
url=os.environ.get("NEO4J_URI"),
username=os.environ.get("NEO4J_USERNAME"),
password=os.environ.get("NEO4J_PASSWORD")
)
# 2. Инициализация Модуля Генерации (LLM)
llm = ChatOpenAI(temperature=0, model_name="gpt-4")
# 3. Создание "Мозга" KAG - цепочки GraphCypherQAChain
# Эта цепочка автоматически делает четыре вещи:
# 1. Анализирует вопрос (query).
# 2. Генерирует Cypher-запрос к графу на основе схемы графа.
# 3. Выполняет Cypher-запрос в Neo4j.
# 4. Передает результат (контекст) и вопрос в LLM для синтеза ответа.
chain = GraphCypherQAChain.from_llm(
llm=llm,
graph=graph,
verbose=True # Позволяет видеть сгенерированный Cypher-запрос
)
# 4. Выполнение KAG-запроса
user_question = "Сколько сотрудников работает в отделе 'Research'?"
response = chain.invoke({"query": user_question})
# 5. Получение результата
# verbose=True покажет в консоли запрос, который сгенерировал LLM,
# например: 'MATCH (e:Employee)-[:WORKS_IN]->(d:Department {name: 'Research'}) RETURN count(e)'
print(response["result"])
Этот пример демонстрирует, как фреймворк автоматизирует роль «Модуля Синтеза», транслируя естественный язык в точный запрос к графу и обратно.
Преимущества и стратегические вызовы KAG
Несмотря на всю свою мощь, KAG не является «серебряной пулей».
Ключевые преимущества
- Надежность и Точность: Ответы основаны на фактах, а не на статистических догадках. Это критично для сфер, где галлюцинации недопустимы.
- «Объяснимость» (Explainability): KAG может «показать свою работу». Система способна продемонстрировать точный путь по графу (какие факты и связи), который привел к ответу. Это невозможно в стандартных LLM.
- Адаптивность: Знания системы можно обновлять в реальном времени, просто добавив новые узлы или связи в граф. Не нужно переобучать LLM.
Стратегические вызовы
- Сложность поддержки графа: Создание и, что важнее, поддержка Графа Знаний в актуальном состоянии — это колоссальная задача инженерии данных. «Мусор на входе — мусор на выходе» здесь работает как никогда.
- Проблема Latency (задержки): KAG — пайплайн сложен. Он включает несколько обращений: к LLM (для анализа), к базе данных (для запроса), снова к LLM (для синтеза). Это может приводить к более медленным ответам по сравнению с RAG.
- Требования к экспертизе: Для внедрения KAG требуются узкоспециализированные и дорогие специалисты: инженеры по графам (Graph Engineers) и онтологи.
Будущее гибридного ИИ — Роль KAG
KAG и RAG — это не конкурирующие технологии, а, скорее, два крыла гибридного ИИ. Они не являются «костылями» для LLM, а представляют собой фундаментальный сдвиг в архитектуре ИИ. Будущее не за монолитными моделями, которые «знают все», а за гибкими системами, которые умеют эффективно использовать внешние знания разных типов.
KAG — это мост, соединяющий невероятные лингвистические способности LLM с точным, структурированным и проверенным миром корпоративных данных. По мере того, как компании стремятся создавать более надежных и умных AI-ассистентов, архитектуры, подобные KAG, будут становиться не просто желательными, а абсолютно необходимыми.
ИИ-агенты для оптимизации бизнес-процессов
Код курса
AGENT
Ближайшая дата курса
18 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
Заключение
KAG (Knowledge-Augmented Generation) — это мощная и стратегически важная архитектура, которая решает главную проблему Больших Языковых Моделей: их оторванность от проверенных фактов. Используя структурированные Графы Знаний в качестве «внешнего мозга», KAG позволяет создавать AI-системы нового поколения. Эти системы не только свободно говорят на человеческом языке, но и основывают каждый свой ответ на верифицированных данных, обеспечивая тот уровень точности, надежности и «объяснимости», который так необходим современному бизнесу, науке и обществу.
Референсные ссылки
- Сравнение и различия (https://www.plainconcepts.com/rag-vs-kag/)
- Объединение RAG с Графами Знаний (https://adasci.org/knowledge-augmented-generation-kag-by-combining-rag-with-knowledge-graphs/)
- Практическое руководство по KnowledgeAG (https://plainenglish.io/blog/kag-knowledge-augmented-generation-a-pratical-guide-better-than-rag)
- Создание RAG с использованием Графа Знаний и LangChain (https://www.e2enetworks.com/blog/step-by-step-guide-to-building-rag-using-knowledge-graph-and-langchain)
- Генерация Графов Знаний (Neo4j Блог) (https://neo4j.com/blog/developer/knowledge-graph-generation/)