 1165
1165 
Содержание
- Ключевые характеристики Kafka Consumer
- Группы потребителей (Consumer Groups)
- Смещения (Offsets)
- Подписка на топики
- Потоковая обработка и Heartbeats
- Принцип работы
- Примеры использования Kafka Consumer/Сценарии применения
- Управление Kafka Consumer: Клиентские библиотеки, Consumer API и примеры
- Пример простого Python Consumer с использованием Consumer API
- Примеры использования Kafka Consumer через консольные утилиты
- Использованные источники и материалы:
Kafka Consumer – это программный компонент (или программный код / библиотека), который интегрируется в клиентское приложение и предназначен для надежного и эффективного чтения данных (сообщений) из одного или нескольких топиков Apache Kafka, обычно работающий в составе группы потребителей для обеспечения масштабируемой и отказоустойчивой обработки потоков информации, активно взаимодействуя с брокерами для получения и фиксации смещений прочитанных сообщений.
Потребители подписываются на выбранные топики. Они извлекают сообщения из их разделов. Kafka Consumer является ключевым элементом для обработки данных в реальном времени. Таким образом, он позволяет приложениям реагировать на события, обрабатывать потоки данных и выполнять аналитику. Каждый Kafka Consumer активно взаимодействует с брокерами для получения новых сообщений. Его основная задача — обеспечить надежное и эффективное потребление данных.
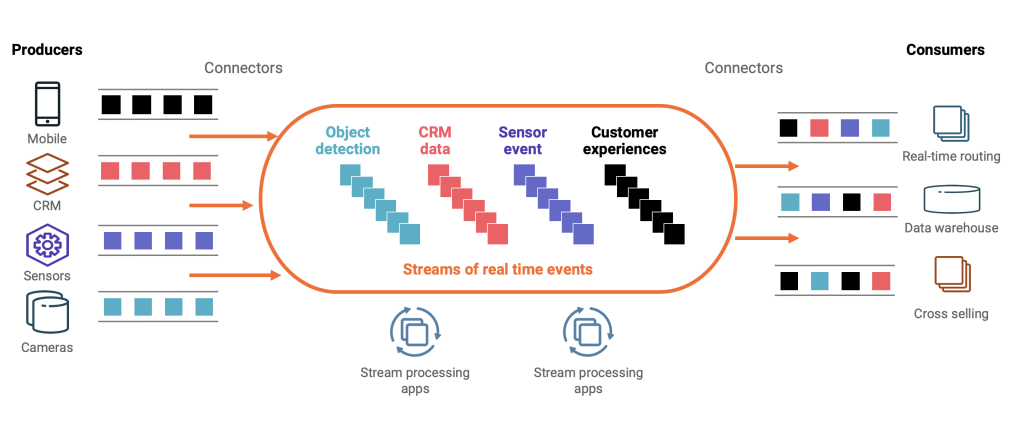
Ключевые характеристики Kafka Consumer
Группы потребителей (Consumer Groups)
Kafka Consumer всегда работает в составе одной или нескольких групп. Группа потребителей — это механизм масштабирования и отказоустойчивости в Kafka. Все потребители в одной группе совместно читают сообщения из одного или нескольких топиков. Принцип работы прост: каждый раздел топика назначается только одному Kafka Consumer внутри группы. Если потребитель выходит из строя, его разделы автоматически переназначаются другим активным потребителям в той же группе. Это гарантирует непрерывность обработки. Кроме того, добавление новых Kafka Consumer в группу увеличивает параллелизм чтения. Например, если топик имеет 3 раздела, то группа может эффективно использовать до 3 активных потребителей. Это обеспечивает линейное масштабирование пропускной способности.
Смещения (Offsets)
Каждый Kafka Consumer отслеживает свое «смещение» (offset). Смещение – это уникальный, последовательный идентификатор последнего успешно прочитанного сообщения в конкретном разделе. Этот механизм критически важен для надежности. Kafka Consumer периодически «фиксирует» (commits) свои смещения в специальном топике `__consumer_offsets`. Это позволяет ему возобновить чтение с точного места, где оно было остановлено, после перезапуска или сбоя. Таким образом, сообщения не обрабатываются повторно без необходимости, и никакие сообщения не теряются. Пользовательский код может управлять фиксацией смещений вручную или довериться автоматическому механизму.
Подписка на топики
Kafka Consumer подписывается на один или несколько топиков. Подписка может быть выполнена по явному имени топика или с использованием регулярных выражений. Использование регулярных выражений удобно для автоматической подписки на новые топики, соответствующие определенному шаблону. После подписки Kafka Consumer начинает получать сообщения из назначенных ему разделов. Этот гибкий подход позволяет потребителям динамически адаптироваться к изменениям в структуре данных.
Потоковая обработка и Heartbeats
Consumer предназначен для высокопроизводительной потоковой обработки данных. Он непрерывно опрашивает брокеры на наличие новых сообщений (используя метод `poll()`). Чтобы оставаться членом группы и сохранять назначенное ему разделы, Consumer регулярно отправляет «пульс» (heartbeat) брокерам. Если брокер не получает heartbeat от потребителя в течение определенного времени, он считает его мертвым и инициирует процесс ребалансировки группы, переназначая разделы другим активным потребителям. Это гарантирует живучесть системы.
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
18 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Принцип работы
Работа Consumer включает несколько ключевых шагов. Сначала потребитель инициализируется и присоединяется к определенной группе потребителей. Затем он отправляет запрос на подписку на один или несколько топиков. Kafka, через координатора группы, назначает этому потребителю конкретные разделы топиков. Каждый Kafka Consumer в цикле вызывает метод `poll()`, чтобы запросить у брокеров новые сообщения из своих назначенных разделов. Брокеры отвечают, предоставляя пакеты сообщений. Потребитель обрабатывает эти сообщения в своем приложении. После успешной обработки он фиксирует (commits) смещения, указывая, до какого момента сообщения были прочитаны и обработаны. Этот механизм обеспечивает надежную и эффективную доставку сообщений, а также их однократную обработку в рамках одной группы потребителей.
Примеры использования Kafka Consumer/Сценарии применения
Kafka Consumer используется в широком спектре сценариев в современных распределенных системах. Например:
- Сбор и анализ логов: Множество сервисов публикуют свои логи в топики. Kafka Consumer читает эти логи, затем они могут быть агрегированы, отфильтрованы и отправлены в хранилища для дальнейшего анализа или отображения на дашбордах.
- Мониторинг в реальном времени: Для отслеживания метрик производительности или критически важных событий систем, Kafka Consumer позволяет собирать данные практически мгновенно.
- Обработка транзакций: В финансовых системах Consumer может получать данные о платежах, заказы или другие транзакционные события для их последующей обработки, валидации и занесения в базу данных.
- Обновление баз данных и кэшей: Потребитель может слушать изменения в топиках (например, CDC-события) и синхронизировать данные между различными базами данных или обновлять кэши для обеспечения их актуальности.
- Обеспечение взаимодействия микросервисов: В архитектурах микросервисов Consumer служит механизмом асинхронной коммуникации, позволяя сервисам обмениваться событиями без жесткой связанности.
Управление Kafka Consumer: Клиентские библиотеки, Consumer API и примеры
Управление Consumer чаще всего осуществляется программно через клиентские библиотеки, доступные для различных языков программирования (Java, Python, Go, Node.js и т.д.). Эти библиотеки предоставляют Consumer API – набор интерфейсов и методов для взаимодействия с брокерами Kafka. С помощью Consumer API разработчики могут подписываться на топики, опрашивать сообщения, управлять фиксацией смещений, настраивать параметры группы потребителей и обрабатывать ребалансировку. Помимо программных клиентов, Kafka также предлагает полезные утилиты командной строки для ручного взаимодействия.
Пример простого Python Consumer с использованием Consumer API
from kafka import KafkaConsumer
from json import loads
# Инициализация Kafka Consumer
# Здесь используются методы и параметры из Kafka Consumer API библиотеки kafka-python
consumer = KafkaConsumer(
'my_topic', # Имя топика, на который подписывается Kafka Consumer
bootstrap_servers=['localhost:9092'], # Адрес брокера Kafka
auto_offset_reset='earliest', # Начать чтение с самого начала, если для группы нет зафиксированных смещений
enable_auto_commit=True, # Включить автоматическую фиксацию смещений Kafka Consumer
auto_commit_interval_ms=1000, # Интервал автоматической фиксации смещений в миллисекундах
group_id='my-python-consumer-group', # Имя группы потребителей Kafka Consumer
value_deserializer=lambda x: loads(x.decode('utf-8')) # Десериализатор для значений сообщений
)
# Чтение сообщений (метод poll() вызывается внутри цикла for)
print("Запуск Kafka Consumer для чтения сообщений...")
for message in consumer:
# Сообщение из топика: topic, раздел: partition, смещение: offset
print(f"Сообщение из топика {message.topic}, раздел {message.partition}, смещение {message.offset}: {message.value}")
# Закрытие Kafka Consumer при завершении работы (в реальном приложении обычно в блоке finally)
consumer.close()
print("Kafka Consumer остановлен.")
Примеры использования Kafka Consumer через консольные утилиты
Для быстрого тестирования и отладки можно использовать встроенный `kafka-console-consumer.sh`. Утилита имеет большой встроенный и подробный help и если вы допустите какую то ошиюку в параметрах то он сразу появится
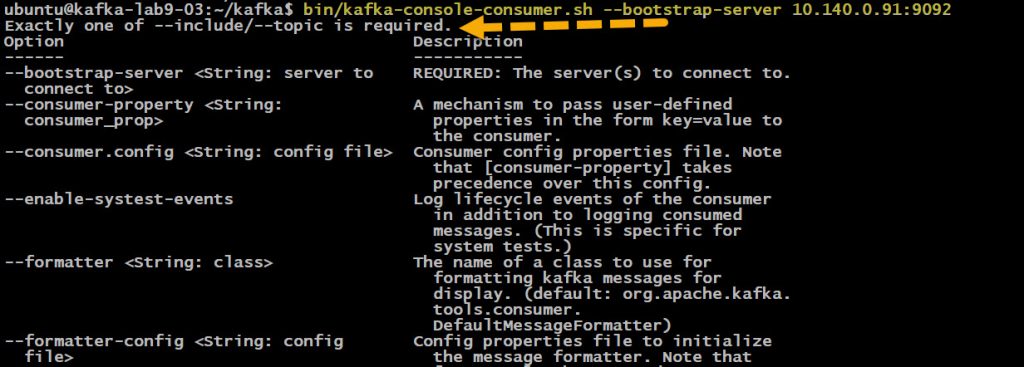
Чтение всех сообщений с начала топика
Эта команда запускает Consumer и читает все сообщения, начиная с самого первого, хотя вы можете управлять чтением данных с конкретного оффсета или отметки времени, из конкретной партиции, с начала топика или с текущего момента, из указанного топика:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic Articles --from-beginning
Можно дополнительно применить форматрирование вывода команды kafka-console-consumer.sh чтобы получить значения полей offset, timestamp,partition и key
bin/kafka-console-consumer.sh \ --bootstrap-server localhost:9092 \ --topic Articles \ --from-beginning \ --property print.key=false \ --property print.value=true \ --property print.timestamp=true \ --property print.partition=true \ --property print.offset=true \ --property print.headers=true \ --property key.separator=" | "
Если постараться то вывод можно даже сделать с конвертацией даты из UNIX-формата (мс от эпохи) в читаемый формат времени (например, YYYY-MM-DD HH:mm:ss), но об этом мы рассказываем на нашем курсе KAFKA: Администрирование кластера Kafka

Чтение новых сообщений для конкретной группы потребителей
Данная команда запускает Consumer, который присоединяется к группе `my-group`. Он будет читать только новые сообщения, поступающие в топик, или те, которые еще не были прочитаны этой группой:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic my_topic --group my-group
Чтение сообщений из определенного раздела и смещения
Эта команда позволяет Kafka Consumer начать чтение с конкретного смещения в указанном разделе топика. Это полезно для отладки или повторной обработки данных:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic my_topic --partition 0 --offset 100
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
18 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800