 1301
1301 
Содержание
Gemini – это семейство передовых мультимодальных моделей искусственного интеллекта (ИИ), разработанное Google DeepMind. Gemini создана с нуля для мультимодальности, что означает способность понимать, обрабатывать и комбинировать различные типы информации, такие как текст, код, изображения, аудио и видео. Модели Gemini предлагаются в различных размерах (Ultra, Pro, Nano) для эффективного применения в широком спектре задач, от сложных рассуждений до работы на мобильных устройствах.
Основные функциональные возможности
Gemini обладает широким спектром возможностей, которые открывают новые горизонты для взаимодействия с ИИ:
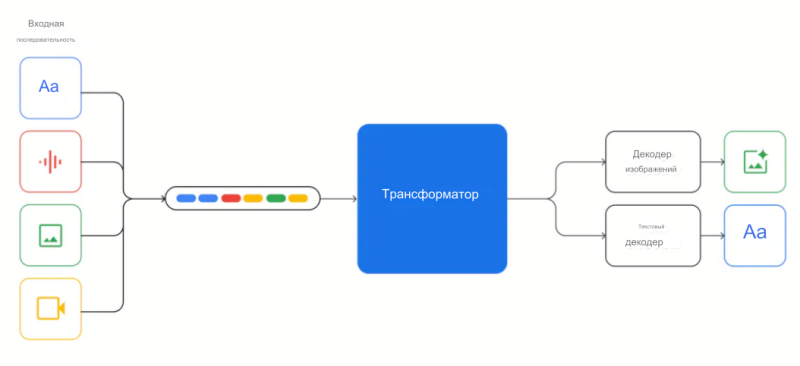
- Мультимодальность: Глубокая интеграция обработки текста, изображений, аудио и видео. Gemini может понимать и генерировать контент, используя комбинации этих модальностей.
- Продвинутые рассуждения и понимание: Способность к сложным логическим выводам, пониманию контекста и нюансов в больших объемах информации.
- Генерация высококачественного контента: Создание текстов различных стилей и форматов (статьи, стихи, сценарии), написание и отладка кода на множестве языков программирования.
- Перевод: Качественный перевод между языками с сохранением смысла и стиля.
- Суммаризация: Извлечение ключевой информации из длинных текстов и документов.
- Ответы на вопросы (Q&A): Предоставление точных и развернутых ответов на основе доступных данных.
- Персонализация: Адаптация ответов и стиля взаимодействия под конкретного пользователя или задачу.
Плюсы и минусы
Плюсы:
- Революционная мультимодальность: Способность работать с разными типами данных открывает уникальные сценарии использования.
- Мощные когнитивные способности: Высокий уровень понимания, рассуждения и решения сложных задач.
- Гибкость и масштабируемость: Различные размеры моделей (Ultra, Pro, Nano) позволяют использовать Gemini на широком спектке устройств и для разных задач.
- Широкий охват знаний: Обучена на огромном массиве данных, что обеспечивает глубокие познания в различных областях.
- Стимулирование инноваций: Потенциал для создания нового поколения приложений и сервисов.
Минусы:
- Потенциал для ошибок и «галлюцинаций»: Как и все LLM, Gemini может генерировать неточную или бессмысленную информацию.
- Вопросы этики и безопасности: Необходимость контроля за генерацией вредоносного или предвзятого контента.
- Зависимость от качества обучающих данных: Предвзятости в данных могут отразиться на выводах модели.
- Высокие вычислительные требования: Для обучения и работы самых мощных версий (например, Gemini Ultra) требуются значительные ресурсы.
- Отсутствие истинного сознания: Несмотря на впечатляющие возможности, модель не обладает самосознанием или реальным пониманием в человеческом смысле.
Особенности реализации и использования
В основе Gemini лежит усовершенствованная архитектура трансформера, оптимизированная для эффективного обучения и мультимодальной обработки. Модель обучается на огромных датасетах, включающих текстовую информацию, код, изображения, аудио и видеозаписи.
Принципы работы:
- Токенизация: Входные данные (текст, звук, кадры видео) преобразуются в числовые представления (токены).
- Механизмы внимания (Attention): Позволяют модели взвешивать важность различных частей входных данных для генерации ответа.
- Глубокие нейронные сети: Многослойные сети обрабатывают информацию и генерируют выходные данные.
Способы использования:
- API (Application Programming Interface): Google предоставляет доступ к моделям Gemini через API (например, в Google AI Studio или Vertex AI), позволяя разработчикам встраивать их возможности в свои приложения и сервисы.
- Интеграция в продукты Google: Gemini уже используется или планируется к использованию в различных продуктах Google, таких как Поиск, Bard (теперь Gemini), Google Ads и др.
- Инструменты для разработчиков: Предоставляются SDK и инструменты для упрощения работы с моделями.
Иллюстрация концепции мультимодальности:
Представьте, что вы можете задать вопрос голосом, приложить изображение и получить развернутый текстовый ответ, учитывающий обе модальности.
Best Practices при использовании
- Формулируйте четкие и конкретные запросы (промпты): Чем точнее запрос, тем релевантнее будет ответ. Укажите желаемый формат, стиль, объем.
- Предоставляйте контекст: Если задача сложная, дайте модели достаточно информации для понимания.
- Итеративно улучшайте запросы: Если первый ответ не идеален, попробуйте переформулировать промпт, добавить детали или попросить уточнения.
- Критически оценивайте результаты: Всегда проверяйте важную информацию, сгенерированную ИИ, на точность и достоверность.
- Используйте «температуру» и другие параметры (если доступны в API): Для управления случайностью и креативностью ответов. Более низкая температура делает ответы более детерминированными и сфокусированными.
- Соблюдайте этические нормы: Не используйте модель для создания вредоносного, вводящего в заблуждение или предвзятого контента.
Troubleshooting и «Тюнинг» взаимодействия
Поскольку пользователи обычно не «тюнят» саму базовую модель Gemini, «тюнинг» здесь относится к оптимизации взаимодействия:
- Неожиданные или нерелевантные ответы:
- Упростите или уточните промпт.
- Разбейте сложную задачу на несколько более простых подзадач.
- Проверьте, нет ли в вашем запросе двусмысленности.
- «Зацикливание» или повторение: Попробуйте прервать генерацию и начать с немного измененного промпта.
- Предвзятые ответы: Сообщайте о таких случаях Google (если есть механизм обратной связи). Старайтесь формулировать запросы нейтрально.
- Понимание ограничений: Помните, что Gemini – это инструмент. Он не обладает реальным опытом или чувствами.
Пример использования API (на Python)
# Предполагается, что есть библиотека google_gemini_api
# import google_gemini_api
# # Установите ваш API ключ
# google_gemini_api.api_key = "YOUR_API_KEY"
# # Пример текстового запроса
# prompt = "Напиши краткое эссе о будущем возобновляемой энергетики."
# try:
# response = google_gemini_api.generate_text(
# model="gemini-pro", # Указание модели
# prompt=prompt,
# max_tokens=300,
# temperature=0.7
# )
# print(response.text)
# except Exception as e:
# print(f"An error occurred: {e}")
# # Пример мультимодального запроса (концептуально)
# # image_data = load_image_from_file("solar_panel.jpg")
# # audio_prompt = load_audio_from_file("question.wav")
# # response = google_gemini_api.generate_multimodal_content(
# # model="gemini-ultra",
# # text_prompt="Опиши эту технологию и ответь на вопрос из аудио.",
# # image=image_data,
# # audio=audio_prompt
# # )
# # print(response.text_output)
# # print(response.audio_output) # Если модель генерирует и ауди
Примечание: Реальный код API может отличаться. Это иллюстративный пример.
Источники для дальнейшего изучения:
- Официальный блог Google о Gemini: https://blog.google/technology/ai/google-gemini-ai/ (или аналогичные анонсы на https://deepmind.google/technologies/gemini/)
- Google AI Studio / Vertex AI документация: (Искать «Google AI Studio Gemini API» или «Vertex AI Gemini documentation» для технической информации по использованию API).
- Обзорные статьи о Gemini на ведущих технологических ресурсах: Например, TechCrunch, The Verge, Wired (искать «Google Gemini review» или «Gemini AI capabilities»).
- Публикации по этике ИИ от Google: https://ai.google/responsibility/responsible-ai-practices/ (для понимания подходов Google к ответственной разработке).
- Научные статьи и блоги исследователей в области LLM: (Поиск по «large language models research», «multimodal AI advancements» на платформах типа arXiv или блогах известных ИИ-лабораторий).