 285
285 
Содержание
- Архитектура Edge-решений: От сенсора до облака
- Битва парадигм: Cloud vs Edge vs Fog
- Почему это критически важно: Три кита Edge Computing
- Технический стек: Инструменты Edge-инженера
- Практика: Эмуляция Edge-логики на Python
- Проблемы и вызовы (The Dark Side of Edge Computing)
- Сценарии будущего: Edge AI и 5G
- Заключение
- Референсные ссылки:
Edge Computing (Граничные вычисления) — это архитектурная парадигма, предполагающая перенос вычислительных мощностей и логики обработки данных из централизованных дата-центров (облаков) на периферию сети — туда, где эти данные генерируются.
Представьте, что вы управляете огромным современным заводом. Ежесекундно тысячи датчиков генерируют гигабайты информации: температура, вибрация, видеопотоки. Если отправлять каждый байт в центральное облако (например, на сервер в другой стране), канал связи мгновенно «задохнется», а счета за трафик станут астрономическими. Но главное — вы потеряете драгоценное время на передачу сигнала туда и обратно. Граничные вычисления решают эту проблему радикально: мы учим устройства «думать» на месте.
В этой статье мы разберем, как устроена эта технология изнутри, почему она необходима для IoT и AI, и как самостоятельно эмулировать Edge-устройство на Python.
Архитектура Edge-решений: От сенсора до облака
Классическая централизованная модель (Client-Server) уступает место распределенной иерархии. Архитектуру Edge Computing принято изображать в виде «слоеного пирога», где каждый уровень выполняет строго отведенную роль.
Рассмотрим эту иерархию снизу вверх, от «земли» к «небу»:
- Уровень 1: Конечные устройства (Far Edge / Endpoints). Это физические генераторы данных. Сюда относятся промышленные сенсоры, умные счетчики, камеры видеонаблюдения, дроны и даже носимая электроника. Обычно они обладают минимальной мощностью. Их задача — просто собрать факт (например, «температура 45 градусов») и передать его выше.

- Уровень 2: Граничный узел (Edge Node / Gateway). Здесь происходит магия граничных вычислений. Это может быть промышленный компьютер, сервер в стойке 5G-вышки или мощный шлюз (Gateway). Узел принимает «сырой» поток, фильтрует его, проводит первичную аналитику (например, распознает лицо на видео) и принимает локальные решения.
- Уровень 3: Облако (Cloud / Core). Глобальный центр управления. В Edge-архитектуре облако не исчезает, но меняет роль. Оно больше не занимается рутиной. Сюда попадают только ценные, агрегированные данные (метаданные) для долговременного хранения, глобальной аналитики (Big Data) и переобучения моделей искусственного интеллекта.
Такое каскадное разделение позволяет системе сочетать мгновенную реакцию рефлексов (Edge) с глубоким интеллектом мозга (Cloud).
Битва парадигм: Cloud vs Edge vs Fog
В профессиональной среде часто возникает путаница между терминами. Новички считают Edge заменой Cloud, а термин Fog («Туман») вообще вводит в ступор. Давайте внесем ясность.

Ключевое различие кроется в локализации обработки данных:
| Характеристика | Cloud Computing | Edge Computing | Fog Computing |
|---|---|---|---|
| Где вычисления? | Удаленный ЦОД (AWS, Azure) | На самом устройстве или рядом | В локальной сети (LAN) |
| Задержка (Latency) | Высокая (сотни мс) | Минимальная (<10 мс) | Средняя (десятки мс) |
| Зависимость от сети | Критическая (нужен интернет) | Низкая (работает автономно) | Средняя |
| Объем данных | Все сырые данные | Только результаты | Агрегированные данные |
Fog Computing (Туманные вычисления) — это, по сути, промежуточный слой. Если Облако высоко в небе, а Edge — на земле, то Туман стелется над землей. Это инфраструктура локальной сети (свитчи, роутеры, микро-серверы), которая объединяет множество Edge-устройств. Cisco ввела этот термин, чтобы описать распределенную обработку данных внутри корпоративного периметра, до выхода в глобальный интернет.
Почему это критически важно: Три кита Edge Computing
Внедрение граничных вычислений обусловлено не модой, а суровой физикой и экономикой. Существуют три фундаментальные проблемы, которые не может решить традиционное облако.
Граничные вычисления устраняют следующие барьеры:
- Латентность (Latency) и реальное время. Скорость света конечна. Сигнал до сервера и обратно может идти 100-200 миллисекунд. Для беспилотного автомобиля на скорости 100 км/ч это означает проехать несколько метров «вслепую». Edge сокращает отклик до 1-5 мс, что критично для автопилотов, телемедицины и высокочастотного трейдинга.
- Пропускная способность (Bandwidth). Представьте нефтяную платформу в океане, подключенную через спутник. Передача терабайтов данных с вибродатчиков стоит безумных денег. Edge-устройство обрабатывает поток на месте и отправляет в центр только отчет: «В 14:00 зафиксирована аномалия, риск поломки 80%». Экономия трафика достигает 99%.
- Безопасность и суверенитет данных. Законодательство (GDPR, 152-ФЗ) и корпоративная тайна часто запрещают выводить данные за пределы контура. Камера в больнице может анализировать состояние пациента, но не имеет права транслировать видео в публичное облако. Edge позволяет оставить чувствительные данные (PII) внутри периметра, отправляя наружу лишь обезличенную статистику.
Технический стек: Инструменты Edge-инженера
Практическое применение Big Data аналитики для решения бизнес-задач
Код курса
PRUS
Ближайшая дата курса
20 апреля, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Разработка под Edge кардинально отличается от веб-разработки или классического Data Engineering. Здесь мы всегда ограничены ресурсами: мало памяти, слабый CPU, риск перегрева.
Инженеры формируют стек из специализированных, легковесных решений:
Hardware (Аппаратное обеспечение). Спектр широк: от любительских Raspberry Pi 4 до промышленных NVIDIA Jetson Orin для AI-задач и Google Coral TPU. В промзонах используются защищенные IoT-шлюзы (Siemens, Advantech), способные работать в пыли и при экстремальных температурах.
Операционные системы. Windows здесь гость редкий. Правят балом легковесные дистрибутивы Linux (Alpine, Yocto Project, Ubuntu Core) или системы реального времени (RTOS, например, Zephyr или FreeRTOS) для микроконтроллеров.
Контейнеризация и Оркестрация. Стандартный Kubernetes слишком прожорлив для Edge. Индустрия перешла на его «младших братьев»:
- K3s — сертифицированный дистрибутив Kubernetes размером менее 100 МБ.
- MicroK8s — решение от Canonical для изоляции приложений на IoT-устройствах.
- KubeEdge — надстройка над K8s, специально заточенная под нестабильную связь.
Протоколы передачи данных. Вместо тяжелого HTTP/REST здесь используют бинарные и экономичные протоколы:
- MQTT — стандарт де-факто. Легкий протокол типа «издатель-подписчик», работающий даже при плохой связи.
- CoAP — упрощенный аналог HTTP для очень слабых устройств.
- OPC UA — стандарт для связи промышленного оборудования (станков) с IT-системами.
Практика: Эмуляция Edge-логики на Python
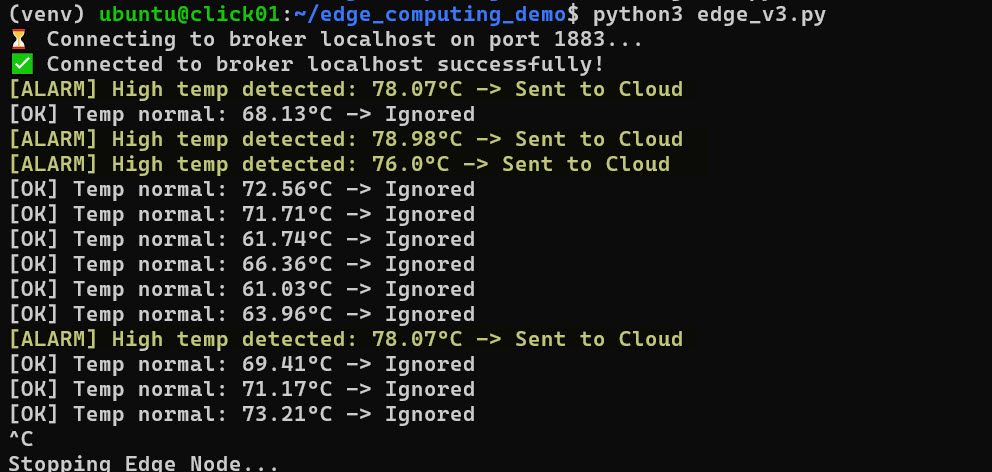
Давайте перейдем от теории к коду. Мы создадим простейшую модель Edge-устройства. Представьте термодатчик, который должен отправлять данные на сервер только если температура превышает критическую норму (фильтрация на краю).
Для этого примера мы используем библиотеку paho-mqtt.
Сценарий: Устройство генерирует данные каждую секунду, но отправляет (публикует) их только при аномалии.
import time
import random
import json
import paho.mqtt.client as mqtt
# Конфигурация
BROKER = "mqtt.eclipseprojects.io" # Публичный тестовый брокер
TOPIC = "factory/sensor/temp_alert"
CRITICAL_TEMP = 75.0
# Функция имитации датчика (генерация данных)
def read_sensor_data():
# Имитируем температуру от 60 до 90 градусов
return round(random.uniform(60.0, 90.0), 2)
def run_edge_device():
client = mqtt.Client(client_id="EdgeNode_01")
try:
print(f"Connecting to broker {BROKER}...")
client.connect(BROKER, 1883, 60)
client.loop_start() # Запускаем фоновый поток для сети
while True:
# 1. Сбор данных (Ingestion)
current_temp = read_sensor_data()
# 2. Локальная обработка (Edge Processing)
# Логика: отправляем только если температура > CRITICAL_TEMP
if current_temp > CRITICAL_TEMP:
payload = json.dumps({
"sensor_id": "temp_01",
"value": current_temp,
"alert": "OVERHEAT",
"timestamp": time.time()
})
# 3. Отправка данных (Transmission)
client.publish(TOPIC, payload)
print(f"[ALARM] High temp detected: {current_temp}°C -> Sent to Cloud")
else:
# Данные отбрасываются (Filtering), экономим трафик
print(f"[OK] Temp normal: {current_temp}°C -> Ignored")
time.sleep(1)
except KeyboardInterrupt:
print("Stopping Edge Node...")
client.loop_stop()
if __name__ == "__main__":
run_edge_device()
Пример переработанного кода с использование локального брокера mosquitto вы можете скачать здесь
Для локального брорека Mosquitto надо установить и запустить сервис
sudo apt update -н sudo apt install mosquitto mosquitto-clients -y sudo systemctl start mosquitto #---- проверьте работающий сервис на порту 1883 sudo netstat -ntlp|grep mosquitto
В этом примере мы видим суть Edge Computing: фильтрация мусора. В облако попадают только критические события, экономя канал и место в базе данных.
Проблемы и вызовы (The Dark Side of Edge Computing)
Несмотря на хайп, внедрение Edge Computing — это сложная инженерная задача. Это не просто «маленькое облако», это распределенный хаос, которым нужно управлять.
Основные боли, с которыми сталкиваются архитекторы:
- Управление парком устройств (Fleet Management). Обновить софт на одном сервере в AWS легко. Обновить прошивку на 10 000 камер, разбросанных по всей стране, когда у половины нестабильный 3G — это кошмар. Требуются надежные механизмы OTA (Over-the-Air) обновлений с возможностью отката.
- Физическая безопасность. Сервер в дата-центре охраняется вооруженной охраной. Edge-устройство висит на столбе или стоит в цеху. Его могут украсть, взломать физически или подменить. Требуется шифрование дисков и защита на уровне железа (TPM-модули).
- Разнородность железа. В одной сети могут работать устройства разных поколений, мощностей и производителей. Создать универсальное ПО, которое одинаково хорошо работает и на мощном сервере, и на слабом шлюзе, крайне сложно.
Сценарии будущего: Edge AI и 5G
Будущее технологии неразрывно связано с развитием искусственного интеллекта (AI) и сетей пятого поколения (5G).
Два главных вектора развития:
- TinyML (AI на микроконтроллерах). Мы учимся запускать нейросети на устройствах размером с монету. Библиотеки TensorFlow Lite и PyTorch Mobile позволяют выполнять инференс (распознавание) локально. Это открывает путь к умной одежде, имплантам и автономным дронам, которые распознают препятствия без связи с базой.
- 5G и MEC (Multi-access Edge Computing). Операторы связи начинают размещать сервера прямо на базовых станциях. Это позволяет получить вычислительную мощность серверного уровня с задержкой менее 5 мс. Это необходимо для массового внедрения AR/VR очков и полного автопилота на дорогах.
Практическая архитектура данных
Код курса
PRAR
Ближайшая дата курса
20 апреля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Заключение
Edge Computing — это неизбежный этап эволюции IT. Маятник истории качнулся от централизации (Mainframes) к децентрализации (PC), затем снова к центру (Cloud), и теперь возвращается к гибридной модели.
Для специалиста по Big Data это означает смену парадигмы. Данные больше не лежат статичным грузом в Data Lake. Они становятся потоком, который нужно обрабатывать на лету. Понимание того, как распределить нагрузку между «краем» и «центром», становится ключевым навыком системного архитектора ближайшего десятилетия.
Референсные ссылки:
- [What is Edge Computing? — IBM] (https://www.ibm.com/topics/edge-computing)
- [EdgeComputing vs Fog Computing — GeeksforGeeks] (https://www.geeksforgeeks.org/difference-between-edge-computing-and-fog-computing/)
- [Eclipse Foundation: The Three Software Stacks of Edge Computing] (https://iot.eclipse.org/)
- [NVIDIA Edge Computing Solutions] (https://www.nvidia.com/en-us/edge-computing/)
- [State of the Edge Report] (https://stateoftheedge.com/)