 964
964 
Содержание
Delta Lake — это открытый формат хранения данных, спроектированный для обеспечения надежности, качества и производительности озер данных. Он не является самостоятельной базой данных, а работает как транзакционный уровень поверх существующих облачных хранилищ, таких как Amazon S3 или Yandex Object Storage. Основная миссия Delta Lake — решить фундаментальные проблемы традиционных озер данных, которые часто превращаются в так называемые «болота данных» (data swamps) — неструктурированные, ненадежные и непригодные для бизнес-аналитики хранилища.
Традиционные Data Lakes, состоящие из тысяч файлов в форматах Apache Parquet или ORC, страдают от отсутствия ACID-транзакций, контроля качества данных и эффективных способов их изменения. Delta Lake решает эти проблемы, привнося в мир больших данных возможности, ранее доступные только в классических хранилищах данных (Data Warehouse). Именно эта технология стала ключевым элементом для построения современной архитектуры, известной как Lakehouse, которая объединяет лучшее из двух миров.
История и роль Databricks
Проект Delta Lake был создан инженерами компании Databricks, основателями Apache Spark. Они столкнулись с тем, что их клиенты не могли построить надежные конвейеры данных поверх озер данных из-за сбоев заданий, повреждения данных и отсутствия консистентности. В ответ на эти вызовы и был разработан Delta Lake.
В 2019 году проект был передан в open-source под управление Linux Foundation, что гарантировало его независимое развитие и способствовало широкому распространению в сообществе. Однако важно понимать разницу между открытым проектом и коммерческим продуктом:
- Open-source Delta Lake: Это открытый формат и библиотека, доступные любому желающему. Сообщество, при активном участии Databricks, развивает его функциональность, которая доступна для Apache Spark, Apache Flink, Presto(Trino) и других движков.
- Databricks Delta Lake: Это коммерческая, значительно оптимизированная версия формата, доступная на платформе Databricks. Она включает в себя проприетарные улучшения производительности, такие как движок Photon, усовершенствованные алгоритмы OPTIMIZE и Z-Ordering, а также глубокую интеграцию с другими сервисами платформы. Эта модель «open-core» позволяет Databricks монетизировать свои разработки, одновременно внося вклад в открытый проект.
От Data Lake к Lakehouse: Архитектурная революция
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Чтобы понять значение Delta Lake, необходимо рассмотреть эволюцию аналитических архитектур.
- Что такое Data Lake? Это централизованное хранилище, которое позволяет хранить структурированные и неструктурированные данные в любом масштабе. Его главные преимущества — гибкость и низкая стоимость хранения (например, в S3). Однако эта гибкость оборачивается проблемами: нет гарантий качества данных, нет транзакций, а сложные DML-операции (UPDATE, DELETE) практически невозможны.
- Что такое Data Warehouse (DWH)? Это высокоструктурированная система, оптимизированная для быстрого выполнения SQL-запросов и бизнес-аналитики. DWH гарантирует надежность данных благодаря ACID-транзакциям и строгому контролю схем. Однако DWH стоит дорого, плохо работает с неструктурированными данными и создает «острова данных», изолированные от остальной экосистемы.
Концепция Lakehouse предлагает решение этого конфликта. Это новая архитектура, которая реализует функциональность хранилищ данных непосредственно поверх дешевого и гибкого озера данных. Delta Lake является технологическим фундаментом, который делает это возможным. Он добавляет критически важный слой управления метаданными и транзакциями поверх файлов в облачном хранилище, обеспечивая надежность и производительность DWH при сохранении открытости и гибкости Data Lake.
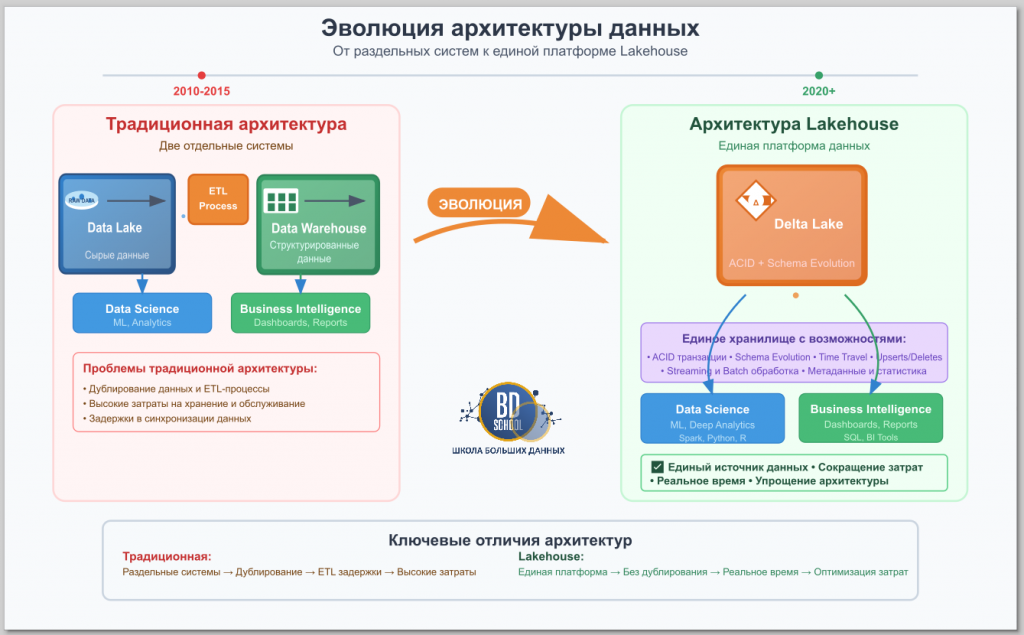
Архитектура Delta Lake: Как это работает под капотом
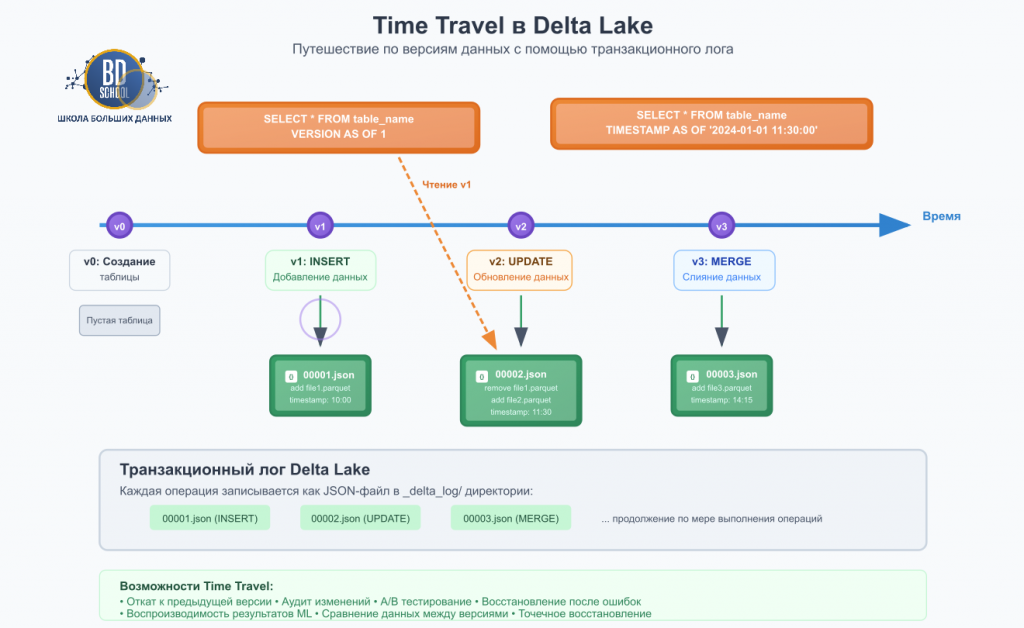
Магия Delta Lake заключается в его транзакционном логе (_delta_log). Это каталог, расположенный внутри директории таблицы, который является единственным источником истины о ее состоянии.
- Транзакционный лог: Лог состоит из упорядоченной последовательности JSON-файлов, где каждый файл представляет собой атомарную фиксацию (коммит) изменений. Коммит содержит действия, например, add (добавить этот файл Parquet) или remove (удалить ссылку на этот файл Parquet). Когда вы запрашиваете таблицу, Delta Lake сначала читает лог, чтобы понять, какие именно файлы составляют актуальную версию данных, и только затем обращается к ним.
- Файлы данных Parquet: Сами данные хранятся в стандартном открытом формате Parquet, что обеспечивает высокую производительность сжатия и чтения. Delta Lake не создает новый проприетарный формат, а лишь управляет жизненным циклом этих файлов.
- Контрольные точки (Checkpoints): Чтобы не читать тысячи JSON-файлов для больших таблиц, Delta Lake периодически создает контрольные точки, которые агрегируют состояние таблицы в один файл (в формате Parquet), что значительно ускоряет получение актуальной версии.
Практическая архитектура данных
Код курса
PRAR
Ближайшая дата курса
20 апреля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Ключевые возможности Delta Lake
- ACID-транзакции: Гарантируют, что каждая операция либо полностью завершается, либо полностью отменяется, обеспечивая консистентность данных даже при одновременных операциях чтения и записи.
- DML-операции: Delta Lake полноценно поддерживает SQL-команды UPDATE, DELETE и MERGE, что позволяет легко вносить изменения в данные, например, для соответствия GDPR или для синхронизации с системами-источниками (CDC).
- Schema Enforcement & Evolution: Система строго следит за соответствием схемы записываемых данных схеме таблицы (enforcement), но при этом позволяет легко и безопасно ее изменять, например, добавлять новые колонки (evolution).
- Time Travel (Путешествие во времени): Поскольку лог хранит всю историю изменений, вы можете запрашивать данные по состоянию на любую версию или временную метку. Это бесценно для аудита, отладки конвейеров данных и воспроизводимости экспериментов в машинном обучении.
Управление данными (Data Governance) с Delta Lake
Надежное управление данными — одно из ключевых преимуществ Lakehouse перед Data Lake. Delta Lake предоставляет для этого встроенные механизмы.
- Data Lineage (Происхождение данных): Транзакционный лог по своей сути является детальным журналом происхождения данных. С помощью команды DESCRIBE HISTORY можно увидеть всю историю изменений таблицы: какая операция была выполнена, когда, каким пользователем или приложением, и какие файлы были затронуты. Это обеспечивает полную прозрачность и отслеживаемость данных.
- Data Provenance (Источник изменений): Помимо самой операции, в лог можно записывать метаданные о коммите, что позволяет точно определить источник каждого изменения (например, ID ноутбука в Databricks, ID Airflow DAG’а), что критически важно для анализа влияния и отладки.
- Аудит и соответствие требованиям (Compliance): Возможности Time Travel и детальный лог транзакций делают аудит данных тривиальной задачей. Для выполнения требований регуляторов, таких как GDPR («право на забвение»), можно легко выполнить операцию DELETE или MERGE для удаления данных конкретного пользователя и доказать факт удаления, предоставив выписку из лога.
Оптимизация производительности
- OPTIMIZE (Компактизация): Решает «проблему маленьких файлов», объединяя их в более крупные, что резко сокращает накладные расходы на чтение метаданных и повышает скорость сканирования.
- Z-Ordering: Это техника многомерной кластеризации, которая размещает связанные данные в одних и тех же файлах. Если вы часто фильтруете по нескольким полям (например, region и date), Z-Ordering по ним может на порядки ускорить запросы за счет эффективного пропуска данных (data skipping).
- VACUUM: Команда для физического удаления файлов, которые больше не являются частью актуальных версий таблицы и вышли за пределы периода хранения. Это позволяет экономить место и окончательно удалять данные.
Сравнение с аналогами
Delta Lake — не единственный формат таблиц для Lakehouse. Его главные конкуренты — Apache Iceberg и Apache Hudi (мы о них писали не давно:-).
- Apache Iceberg (создан в Netflix) фокусируется на агностичности к движкам и использует древовидную структуру метаданных вместо хронологического лога. Его сильные стороны — мощные возможности эволюции схемы и скрытое партиционирование, которое позволяет менять структуру партиций без переписывания данных.
- Apache Hudi (создан в Uber) исторически был силен в сценариях потоковой ingest-обработки и предлагает гибкие типы таблиц: Copy-on-Write (простота и скорость чтения) и Merge-on-Read (скорость записи).
В то время как все три проекта движутся к схожей функциональности, Delta Lake часто выбирают за простоту, зрелость и лучшую в индустрии интеграцию с Apache Spark и платформой Databricks.
Заключение
Delta Lake — это больше, чем просто файловый формат. Это фундаментальная технология, которая привнесла надежность и производительность баз данных в мир озер данных. Став основой для архитектуры Lakehouse, он позволяет компаниям строить единую, масштабируемую и экономически эффективную платформу для всех своих данных — от сырых логов до витрин для BI. Встроенные возможности для управления данными (Data Governance) и аудита делают его стандартом де-факто для построения современных аналитических систем, где качество и отслеживаемость данных имеют первостепенное значение.
Референсные ссылки
- Официальный сайт Delta Lake https://delta.io/
- Документация: Что такое Delta Lake? https://docs.delta.io/latest/delta-intro.html
- The Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics — Databricks Blog https://www.databricks.com/blog/2020/01/30/what-is-a-data-lakehouse.html
- Проект Delta Lake на GitHub https://github.com/delta-io/delta