 490
490 
Содержание
DataOps — это междисциплинарный подход к управлению данными, который объединяет принципы DevOps, автоматизацию, оркестрацию и контроль качества для обеспечения непрерывной, масштабируемой и надежной доставки данных от источников до аналитических и продуктовых систем.
В традиционных организациях путь данных от источника до отчета часто занимает недели. Инженеры данных, аналитики и Data Scientists работают изолированно, используя разные инструменты и среды. Это порождает «информационные колодцы» и конфликты версий. DataOps решает эту проблему, внедряя принципы непрерывной интеграции и доставки (CI/CD) в мир данных. Таким образом, команды могут развертывать новые модели и витрины данных ежедневно, а не ежемесячно. Кроме того, методология смещает фокус с простого «хранения» данных на их активное использование для генерации бизнес-ценности.
Ключевые аспекты и архитектура DataOps
Архитектура DataOps фундаментально отличается от классических хранилищ данных (Data Warehouse). Она строится не вокруг статичных баз данных, а вокруг динамических потоков движения информации.
Можно выделить несколько критически важных столпов, на которых держится эта архитектура:
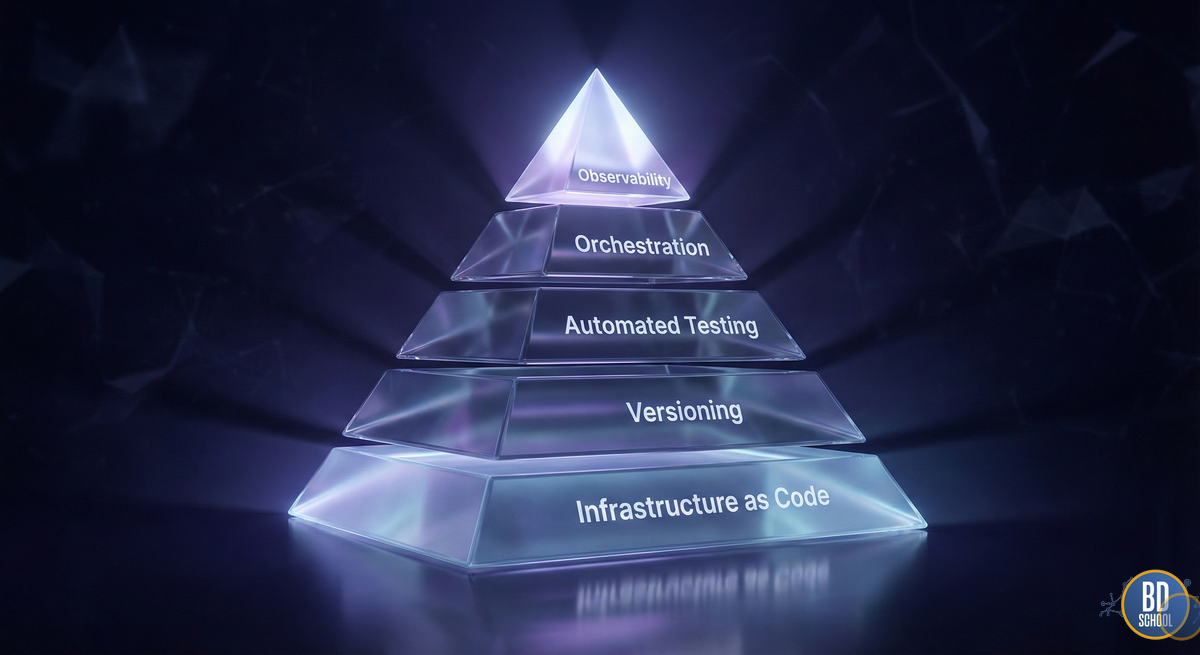
- Все как код (Everything as Code). Это центральный принцип. Не только скрипты трансформации (SQL, Python), но и конфигурации инфраструктуры, настройки доступов и политики качества данных хранятся в репозиториях кода (Git). Это позволяет отслеживать историю изменений и откатываться к предыдущим версиям при сбоях.
- Непрерывная оркестрация. В отличие от простых планировщиков (cron), DataOps использует сложные оркестраторы. Они управляют зависимостями между задачами, перезапускают упавшие процессы и балансируют нагрузку.
- Автоматизированное тестирование. Тесты пишутся на каждом этапе. Существуют юнит-тесты для кода трансформации и тесты качества данных (Data Quality tests), проверяющие сами данные на соответствие бизнес-правилам.
- Изолированные среды. Разработка никогда не ведется на «живых» данных (Production). Архитектура DataOps предполагает создание эфемерных (временных) сред для каждого разработчика, которые автоматически уничтожаются после проверки гипотезы.
- Активное управление метаданными. Система должна знать о данных все. Кто их создал, когда обновил, и какие отчеты сломаются, если изменить структуру таблицы. Это обеспечивает прозрачность (Data Lineage).
Таким образом, архитектура DataOps создает «защитную сетку». Она позволяет инженерам экспериментировать и совершать ошибки в безопасной среде, не ломая основные бизнес-процессы.
Принцип работы DataOps: От сырых данных к ценности
Механизм работы DataOps представляет собой бесконечный цикл, часто изображаемый в виде восьмерки. Он охватывает два основных домена: разработку новых функций (Value Pipeline) и эксплуатацию текущих процессов (Innovation Pipeline).
Рассмотрим пошаговый механизм функционирования типичного конвейера:
- Сбор требований и Дизайн. Аналитики формулируют бизнес-потребность. Инженеры проектируют архитектуру решения, создавая задачу в трекере (например, Jira).
- Разработка в ветке (Branching). Разработчик создает отдельную ветку в системе контроля версий. Он пишет код трансформации данных, например, на SQL или Python.
- Локальное тестирование. Инженер запускает код в своей песочнице. Для этого часто используются Docker-контейнеры, имитирующие производственную среду.
- Непрерывная интеграция (CI). После сохранения кода (commit) автоматически запускается CI-сервер (например, GitLab CI или Jenkins). Он выполняет серию проверок: линтинг кода, проверку безопасности и юнит-тесты.
- Тестирование данных. На этом этапе DataOps проверяет не только логику скрипта, но и сами данные. Проверяются типы полей, отсутствие дублей и распределение значений.
- Непрерывная доставка (CD). Если все тесты пройдены, код автоматически сливается с основной веткой и развертывается в среду Staging, а затем и в Production.
- Мониторинг и Наблюдаемость. После развертывания вступают в дело системы мониторинга. Они следят за свежестью данных, временем выполнения задач и аномалиями.
Ключевая особенность механизма DataOps — обратная связь. Если на этапе мониторинга обнаружена ошибка (например, «битые» данные от поставщика), система автоматически оповещает команду. Часто конвейер может сам остановить загрузку, чтобы не загрязнять хранилище.
Практическая архитектура данных
Код курса
PRAR
Ближайшая дата курса
20 апреля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
DataOps и стандарты управления данными (DAMA)
Существует опасное заблуждение, что скорость DataOps противоречит фундаментальности DAMA (Data Management Association). Считается, что стандарты DAMA-DMBOK слишком бюрократичны для гибкой разработки. Однако в реальности эти подходы образуют симбиоз.
Взаимодействие DataOps и DAMA строится на следующих принципах:
- Автоматизация Data Governance. DAMA определяет политики (правила игры), а DataOps обеспечивает их техническое исполнение. Например, DMBOK требует обеспечения качества данных. В DataOps это реализуется через автоматические тесты (Great Expectations, dbt tests), блокирующие попадание плохих данных в отчеты.
- Управление метаданными. DAMA подчеркивает важность каталогизации данных. Инструменты DataOps автоматически собирают метаданные (Lineage) во время выполнения пайплайнов, поддерживая актуальность каталога без ручного труда.
- Безопасность и Приватность. Стандарты DAMA по защите данных внедряются в код инфраструктуры. Доступы к чувствительной информации (PII) регулируются автоматически через код (Role-Based Access Control as Code).
Таким образом, DataOps — это «руки», которые выполняют «законы», написанные DAMA. Без стандартов DAMA конвейеры DataOps будут быстро доставлять мусор. Без DataOps стандарты DAMA останутся стопкой бумаги, которую никто не читает. Интеграция этих подходов создает «Data Governance 2.0» — управление, встроенное в процесс разработки.
Экосистема: DataOps как фундамент для MLOps
MLOps (Machine Learning Operations) часто называют расширением DataOps, но это не совсем верно. Это взаимозависимые дисциплины. Невозможно построить надежную систему MLOps без зрелого DataOps. Рассмотрим их критическую взаимосвязь:
- Качество данных для моделей. Модели машинного обучения крайне чувствительны к изменениям во входных данных (Data Drift). DataOps обеспечивает стабильность и чистоту данных, на которых обучаются модели. Если конвейер данных ломается, модель MLOps начинает выдавать неверные предсказания.
- Feature Store (Магазин признаков). Это точка соединения двух миров. Инженеры DataOps создают и обновляют признаки (features), помещая их в Feature Store. Специалисты MLOps (Data Scientists) берут эти признаки для обучения моделей.
- Версионирование. В MLOps нужно версионировать не только код модели, но и данные, на которых она училась. Инструменты DataOps (например, DVC) предоставляют эту возможность, связывая конкретный коммит кода с конкретным снимком данных (Snapshot).
Следовательно, DataOps отвечает за доставку «сырья» (данных), а MLOps — за работу «станка» (модели). Попытка внедрить MLOps без налаженного DataOps похожа на строительство крыши без фундамента. Команды будут тратить 80% времени на очистку данных вручную, вместо настройки нейросетей.
Сценарии использования (Use Cases)
Применение DataOps оправдано там, где данные меняются часто, а требования бизнеса к аналитике высоки. Рассмотрим детальные сценарии:
Соблюдение нормативных требований (GDPR/ФЗ-152).
- Проблема: Компании необходимо удалять данные пользователей по запросу («право на забвение») во всех системах.
- Решение DataOps: Автоматизированный пайплайн, который ищет идентификатор пользователя во всех озерах данных и резервных копиях, удаляет его и генерирует отчет о соответствии требованиям.
Миграция Legacy-систем в облако.
- Проблема: Перенос петабайтов данных из старого Oracle в облачный Snowflake без остановки бизнеса.
- Решение DataOps: Параллельный запуск двух систем. Автоматическая сверка данных (Data Reconciliation) между старой и новой системой в реальном времени для выявления расхождений.
Self-Service Analytics (Аналитика самообслуживания).
- Проблема: Бизнес-пользователи ждут новые витрины неделями.
- Решение DataOps: Платформа данных, где аналитик может сам написать SQL-запрос. Система автоматически проверит его, создаст витрину в песочнице и, если тесты пройдены, выведет в прод.
Снижение технического долга.
- Проблема: Лоскутная автоматизация скриптами, которые запускаются вручную.
- Решение DataOps: Перенос всей логики в оркестратор (Airflow). Внедрение стандартов кодирования и обязательного Code Review.
Управление и Настройка DataOps
Взаимодействие с инструментами DataOps требует навыков программирования и знания командной строки (CLI). Интерфейсы Drag-and-Drop используются редко. Основной метод управления — декларативное описание желаемого состояния системы. Ниже приведены технические примеры реализации ключевых этапов.
Пример 1. Контейнеризация среды (Dockerfile)
Чтобы обеспечить идентичность среды у всех разработчиков, используется Docker. Этот файл описывает образ, в котором будут запускаться трансформации.
# Базовый образ с Python FROM python:3.9-slim # Установка рабочей директории WORKDIR /app # Установка dbt (инструмент трансформации) и драйвера для PostgreSQL RUN pip install dbt-postgres # Копирование конфигурационных файлов проекта COPY . . # Команда по умолчанию: запуск тестов и трансформаций CMD ["dbt", "build"]
Пример 2. Пайплайн валидации данных (Great Expectations)
Это пример JSON-конфигурации для библиотеки Great Expectations. Она проверяет, что в колонке order_total минимальное значение не меньше 0 (нет отрицательных заказов).
{
"expectation_type": "expect_column_values_to_be_between",
"kwargs": {
"column": "order_total",
"min_value": 0,
"mostly": 0.99
},
"meta": {
"notes": "Проверка на неотрицательные суммы заказов. Допускается 1% ошибок."
}
}
Пример 3. CI/CD скрипт (GitLab CI .gitlab-ci.yml)
Фрагмент настройки конвейера, который запускает тесты при каждом изменении кода.
stages:
- test
- deploy
data_quality_test:
stage: test
image: python:3.9
script:
- pip install pytest
- pytest tests/data_integrity_checks.py
only:
- merge_requests
deploy_to_prod:
stage: deploy
script:
- echo "Deploying to Snowflake..."
- dbt run --target prod
when: manual
only:
- main
Эти примеры показывают, что DataOps требует серьезной инженерной подготовки. Это переход от «кликанья мышкой» к написанию надежного кода инфраструктуры.
Вызовы и сложности внедрения
Несмотря на очевидные преимущества, переход на DataOps сопряжен с серьезными трудностями. Основной барьер — не технологии, а люди.
В процессе внедрения организации сталкиваются со следующими проблемами:
- Культурное сопротивление. Аналитики, привыкшие работать в Excel или писать SQL «в стол», часто сопротивляются внедрению Git и код-ревью. Они воспринимают это как лишнюю бюрократию, а не помощь.
- Дефицит компетенций. На рынке мало специалистов, которые одинаково хорошо понимают и специфику данных (ETL, SQL), и практики разработки ПО (CI/CD, Docker). Часто приходится обучать инженеров данных практикам DevOps с нуля.
- Сложность инструментов. Экосистема DataOps фрагментирована. Существуют сотни инструментов для разных задач. Выбор правильного стека и их интеграция между собой (оркестрация зоопарка технологий) требует высокой квалификации архитектора.
- Наследие (Legacy). Внедрение современных практик поверх устаревших монолитных баз данных, которые нельзя останавливать, похоже на ремонт двигателя летящего самолета.
Преодоление этих вызовов требует поддержки руководства и постепенного, эволюционного подхода к изменениям.
Практическое применение Big Data аналитики для решения бизнес-задач
Код курса
PRUS
Ближайшая дата курса
20 апреля, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Заключение
DataOps — это эволюционный ответ на взрывной рост объемов информации и требований к скорости ее обработки. В современном мире данные являются таким же активом, как деньги или персонал. Управлять ими кустарными методами больше непозволительно.
Внедрение DataOps позволяет достичь трех ключевых целей: скорости (сокращение Time-to-Market), качества (снижение ошибок в отчетах) и управляемости (прозрачность процессов). Эта методология гармонично объединяет строгие стандарты DAMA с гибкостью Agile, создавая надежный фундамент для передовых технологий, таких как MLOps и искусственный интеллект. Компании, игнорирующие DataOps, рискуют утонуть в «болоте данных» и потерять конкурентное преимущество из-за медленной и недостоверной аналитики.
Референсные ссылки
-
DataOps Manifesto https://dataopsmanifesto.org/en/
-
DAMA International https://www.dama.org/
-
Что такое DataOps и зачем он нужен https://www.atlassian.com/dataops
-
Документация dbt Labs https://docs.getdbt.com/
-
Руководство по Apache Airflow https://airflow.apache.org/