 683
683 
Содержание
- Ключевые компоненты архитектуры Data Vault
- Хабы (Hubs): Неизменное ядро бизнеса
- Линки (Links): Отношения между Хабами
- Сателлиты (Satellites): Контекст, атрибуты и история
- Принцип работы: Загрузка и хранение в Data Vault
- Параллельная загрузка
- Как Data Vault хранит историю
- Сценарии использования и преимущества Data Vault
- Взаимодействие с Data Vault: Примеры на SQL
- Пример 1: Загрузка данных в Хаб и Сателлит (SQL)
- Пример 2: Чтение данных (сборка "на лету") (SQL)
- Data Vault 2.0: Эволюция подхода
- Сравнение: Data Vault, 3NF и Схема Звезды
- Заключение
- Референсные ссылки
Data Vault (DV) — это современная методология моделирования, архитектура и набор практик для создания корпоративных хранилищ данных (DWH). Важно понимать: DV — это не программный продукт, который можно «купить» или «установить». Это подход, стандарт проектирования. Его главная цель — решить две основные проблемы традиционных DWH: нехватку гибкости при изменениях и отсутствие полной, гранулярной истории данных. Эту методологию разработал Дэн Линстедт (Dan Linstedt) в 1990-х годах, а позже она превратилась в стандарт Data Vault 2.0.
Если говорить просто, DV — это гибридный подход. Он берет лучшие черты из классических моделей. Он использует нормализацию (как в 3NF Билла Инмона) для устранения дублирования. Одновременно он ориентирован на аналитику (как «схема звезды» Ральфа Кимбалла). Результатом является уникальная структура. Она идеально подходит для интеграции данных из множества разрозненных источников. Эта структура создана, чтобы легко адаптироваться к новым бизнес-требованиям, обеспечивать 100% аудит всех изменений и поддерживать параллельную загрузку данных.
Ключевые компоненты архитектуры Data Vault
Чтобы понять Data Vault, нужно разобраться в трех его «китах». Вся модель строится всего из трех типов таблиц. Эта элегантная простота и есть ключ к ее гибкости. Каждый компонент выполняет одну, очень специфическую задачу.
Хабы (Hubs): Неизменное ядро бизнеса
Хабы — это фундамент. Они хранят уникальные бизнес-ключи (Natural Keys), которые идентифицируют основные бизнес-сущности. Примерами таких сущностей могут быть «Клиент», «Продукт», «Сотрудник», «Счет».
Главное правило Хаба: в нем нет никаких описательных атрибутов. Ни имени клиента, ни цвета продукта. В Хабе HUB_CUSTOMER будет храниться только идентификатор клиента (например, CustomerID из CRM-системы или ИНН). Кроме ключа, Хаб содержит только метаданные: дату загрузки (LoadDate) и источник записи (RecordSource).
Зачем это нужно? Бизнес-ключи по своей природе стабильны. ИНН клиента или SKU товара не меняются. Вынося их в отдельную, «ядерную» таблицу, DataVault создает неизменный, стабильный скелет всего хранилища. Все остальное будет «навешиваться» на этот скелет.
Линки (Links): Отношения между Хабами
Линки (или Связи) — это клей, который соединяет Хабы. Они представляют собой транзакции, события или любые ассоциации между бизнес-сущностями. Линки реализуют отношения «многие-ко-многим». Например, Линк LNK_CUSTOMER_PRODUCT будет связывать Хаб HUB_CUSTOMER и Хаб HUB_PRODUCT. Он отвечает на вопрос «Какой клиент купил какой товар?».
Как и Хабы, Линки не содержат описательных атрибутов. Они хранят только ссылки (первичные ключи) на те Хабы, которые они связывают. Если Линку самому по себе нужен контекст (например, «количество товара в заказе»), этот контекст выносится в специальный Сателлит на Линке.
Такая структура позволяет невероятно гибко добавлять новые отношения. Если завтра нам понадобится связать «Клиента» и «Сотрудника» (кто менеджер клиента), мы просто создаем новый Линк LNK_CUSTOMER_EMPLOYEE. При этом нам не нужно менять ни HUB_CUSTOMER, ни HUB_EMPLOYEE.
Сателлиты (Satellites): Контекст, атрибуты и история
Сателлиты — это место, где хранится вся «мякоть»: описательные атрибуты, которые дают Хабам и Линкам контекст. Именно здесь лежат Имя клиента, Адрес, Email, Название продукта, Цена и так далее.
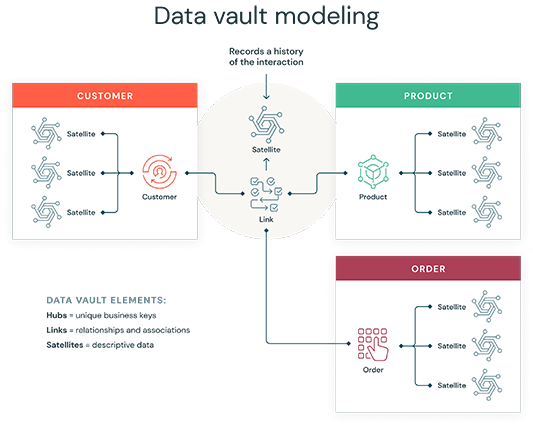
У одного Хаба или Линка может быть сколько угодно Сателлитов. Это ключевой элемент гибкости. Например, HUB_CUSTOMER может иметь:
- SAT_CUSTOMER_MAIN: хранит ФИО, дату рождения. Меняется редко.
- SAT_CUSTOMER_ADDRESS: хранит адрес. Меняется чаще.
- SAT_CUSTOMER_CONTACTS: хранит телефон, email. Меняется очень часто.
Главная «суперсила» Сателлитов — это хранение истории. Data Vault никогда не обновляет (UPDATE) и не удаляет (DELETE) данные. Когда у клиента меняется адрес, в SAT_CUSTOMER_ADDRESS просто добавляется новая строка с новым адресом и текущей датой загрузки. Старая запись остается нетронутой. Это обеспечивает 100% аудируемость. Вы всегда можете посмотреть, какой адрес был у клиента в любой момент времени.
Эти три компонента (Хабы, Линки, Сателлиты) позволяют создать невероятно устойчивую и адаптивную модель хранилища данных.
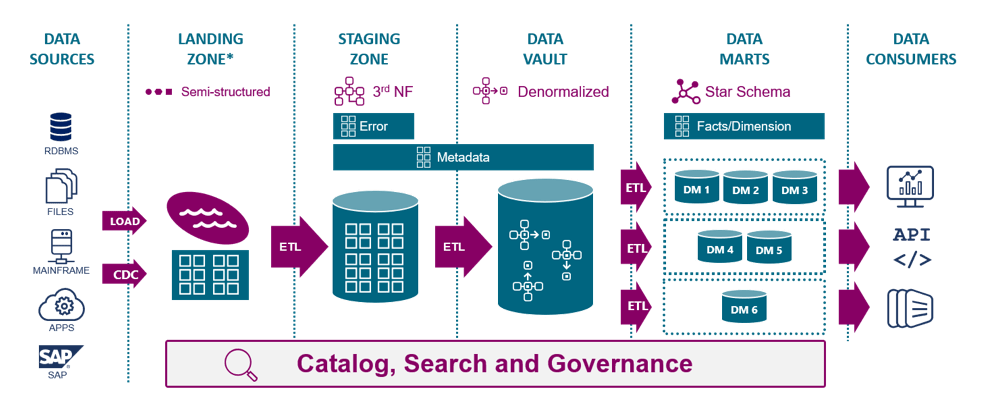
Принцип работы: Загрузка и хранение в Data Vault
Архитектура DataVault напрямую влияет на то, как данные в него загружаются и как в нем хранится история. Эти процессы кардинально отличаются от традиционных подходов.
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Параллельная загрузка
Одно из главных преимуществ Data Vault — возможность массовой параллельной загрузки. В классической 3NF-модели таблицы жестко связаны ограничениями внешних ключей (Foreign Keys). Вы не можете загрузить «Заказ», пока не загружен «Клиент». Это создает «бутылочное горлышко» и усложняет ETL-процессы.
В DV такой проблемы нет. Хабы, Линки и Сателлиты являются независимыми объектами. Между ними нет принудительных ограничений целостности на уровне базы данных. Это означает, что вы можете загружать HUB_CUSTOMER, HUB_PRODUCT и SAT_CUSTOMER_ADDRESS одновременно, в разных потоках. Это идеально подходит для современных MPP-систем (Massive Parallel Processing), таких как Snowflake, Redshift или BigQuery. Сначала загружаются все Хабы, затем все Линки, затем все Сателлиты. Это делает процесс загрузки (ETL/ELT) невероятно быстрым и масштабируемым.
Как Data Vault хранит историю
Как уже упоминалось, Сателлиты отвечают за хранение истории. Этот механизм похож на Slowly Changing Dimension (SCD) Type 2, но реализован более гранулярно и эффективно.
Каждая строка в Сателлите имеет как минимум два служебных поля:
- Дата загрузки (LoadDate/Load_Timestamp): Точное время, когда эта версия данных поступила в хранилище.
- Источник записи (RecordSource): Из какой системы пришли эти данные (например, ‘CRM’, ‘Billing’).
Когда из источника приходит запись о клиенте, ETL-процесс проверяет: изменилось ли что-то в атрибутах этого Сателлита? Если нет, ничего не происходит. Если да (например, изменился email), то DataVault не перезаписывает старую строку. Вместо этого он добавляет новую строку в Сателлит. Эта новая строка содержит полный срез данных (включая неизменившиеся) и новую LoadDate.
Таким образом, в Сателлите накапливается полная, по-секундно отслеживаемая история изменений каждого атрибута. Это и есть аудируемость.
Сценарии использования и преимущества Data Vault
Data Vault — это не «серебряная пуля» на все случаи жизни. Он наиболее эффективен в определенных сценариях.
Эта методология идеально подходит в следующих ситуациях:
- Множество источников: Когда вам нужно интегрировать данные из десятков разных систем (CRM, ERP, биллинг, логистика, веб-логи).
- Частые изменения: Когда бизнес-требования или структуры источников постоянно меняются. Data Vault позволяет добавлять новые источники, атрибуты или связи, не ломая существующую модель.
- Жесткие требования к аудиту: В сферах, где нужно отслеживать каждое изменение данных (финансы, страхование, медицина).
- Agile DWH: Когда хранилище данных разрабатывается итеративно, по принципам Agile.
- Большие объемы данных: Архитектура Data Vault рассчитана на параллельную загрузку и отлично масштабируется на петабайтных объемах.
Ключевые преимущества этого подхода: гибкость, масштабируемость, аудируемость и отказоустойчивость.
Взаимодействие с Data Vault: Примеры на SQL
Важно понимать: DataVault — это слой интеграции, а не презентации. Его структура (сотни таблиц с Хабами, Линками, Сателлитами) не предназначена для прямых запросов от бизнес-аналитиков. Запросы к Data Vault получаются сложными, с большим количеством JOIN.
Обычно поверх DV (который часто называют «сырым» слоем или Silver Layer) строятся витрины данных (Data Marts) в виде «схемы звезды». Именно к этим витринам (Gold Layer) уже обращаются BI-инструменты и аналитики.
Однако разработчикам DWH постоянно приходится писать код для загрузки и чтения из DV.
Пример 1: Загрузка данных в Хаб и Сателлит (SQL)
Представим, что у нас есть «сырые» данные во временной таблице staging_customers.
-- Таблица с "сырыми" данными
CREATE TABLE staging_customers (
customer_id VARCHAR(50),
customer_name VARCHAR(200),
email VARCHAR(100),
load_time TIMESTAMP,
record_source VARCHAR(20)
);
-- Вставим пример данных
INSERT INTO staging_customers VALUES
('C-101', 'Иван Петров', 'ivan@email.com', '2025-11-10 18:00:00', 'CRM'),
('C-102', 'Анна Сидорова', 'anna@email.com', '2025-11-10 18:00:00', 'CRM');
Теперь загрузим эти данные в Data Vault.
-- 1. ЗАГРУЗКА ХАБА (только бизнес-ключ)
-- Загружаем только те ключи, которых еще нет в Хабе
INSERT INTO hub_customer (
hub_customer_key,
customer_id,
load_date,
record_source
)
SELECT
MD5(s.customer_id), -- Используем хэш для создания суррогатного ключа (практика DV 2.0)
s.customer_id,
s.load_time,
s.record_source
FROM staging_customers s
LEFT JOIN hub_customer h ON h.customer_id = s.customer_id
WHERE h.hub_customer_key IS NULL; -- Только новые
-- 2. ЗАГРУЗКА САТЕЛЛИТА (описательные атрибуты)
-- Здесь мы должны загружать И новые записи, И измененные
-- Для простоты примера, загрузим все
INSERT INTO sat_customer_details (
hub_customer_key,
load_date,
record_source,
customer_name,
email
)
SELECT
MD5(s.customer_id), -- Тот же ключ, что и в Хабе
s.load_time,
s.record_source,
s.customer_name,
s.email
FROM staging_customers s;
-- В реальном проекте здесь была бы проверка на изменение атрибутов
Пример 2: Чтение данных (сборка «на лету») (SQL)
Теперь соберем «актуальный» срез данных, объединив Хаб и Сателлит.
-- Нам нужно получить ПОСЛЕДНЮЮ запись из Сателлита для каждого клиента
-- Используем оконную функцию ROW_NUMBER()
WITH RankedSatellite AS (
SELECT
s.hub_customer_key,
s.customer_name,
s.email,
s.load_date,
-- Ранжируем записи для каждого ключа: самые новые получают ранг 1
ROW_NUMBER() OVER(
PARTITION BY s.hub_customer_key
ORDER BY s.load_date DESC
) as rn
FROM sat_customer_details s
)
-- Теперь собираем модель: соединяем Хаб (ключ) и Сателлит (атрибуты)
SELECT
h.customer_id,
rs.customer_name,
rs.email,
rs.load_date AS last_updated_time
FROM hub_customer h
JOIN RankedSatellite rs
ON h.hub_customer_key = rs.hub_customer_key
WHERE
rs.rn = 1; -- Выбираем только самые свежие записи (ранг = 1)
Этот JOIN с ROW_NUMBER() — классический паттерн для чтения данных из Data Vault.
Data Vault 2.0: Эволюция подхода
Со временем оригинальная методология Data Vault эволюционировала в Data Vault 2.0. Это не просто «вторая версия», а комплексный стандарт, который включает в себя не только модель данных, но и архитектуру, методологию и практики.
Data Vault 2.0 официально добавил несколько ключевых элементов:
- Хэширование ключей: DV 2.0 настоятельно рекомендует использовать хэш-функции (например, MD5 или SHA-256) для создания суррогатных ключей в Хабах и Линках. Это позволяет полностью отвязать DWH от исходных систем и упрощает интеграцию (как в SQL-примере выше).
- Архитектура: Четко определены слои: Staging Area (временная зона), Raw Vault (сырые данные, 1-в-1 с источником), Business Vault (бизнес-правила, расчеты) и Information Marts (витрины данных).
- Методология: DV 2.0 неразрывно связан с Agile, Scrum и итеративной разработкой. Он также делает огромный упор на автоматизацию (Code Generation) для создания и загрузки тысяч таблиц.
- Интеграция Big Data: Стандарт включает паттерны для работы с неструктурированными данными, NoSQL-базами и потоковой обработкой данных.
Сегодня, когда говорят о Data Vault, почти всегда подразумевают именно Data Vault 2.0.
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Сравнение: Data Vault, 3NF и Схема Звезды
Новички часто спрашивают: «Что лучше: Data Vault или Схема Звезды?». Это некорректный вопрос. Они созданы для разных целей и идеально дополняют друг друга.
- 3NF (Третья Нормальная Форма): Это подход Билла Инмона (Inmon). Он создает высоко нормализованную, единую модель всего предприятия.
- Плюс: Устраняет дублирование, «единый источник правды».
- Минус: Невероятно хрупкий. Добавление одного нового атрибута может потребовать изменения десятков таблиц. Медленная загрузка из-за жестких связей.
- Схема Звезды (Star Schema): Это подход Ральфа Кимбалла (Kimball). Он создает денормализованные витрины, оптимизированные для BI-запросов (одна таблица Фактов, окруженная таблицами Измерений).
- Плюс: Очень быстро для чтения и аналитики. Понятен для бизнеса.
- Минус: Создан под конкретные бизнес-процессы. Если процесс меняется, «звезду» часто приходится перестраивать.
- Data Vault:
- Плюс: Гибкость. Новые источники добавляются безболезненно. Полная аудируемость. Быстрая параллельная загрузка.
- Минус: Очень сложен для чтения. Требует много JOIN для получения простого отчета.
Как они работают вместе в современной архитектуре мы писали об этом здесь и разбираем на наших курсах по архитектуре данных
- Staging (Bronze): Сырые данные как есть.
- Data Vault (Silver): Данные из Staging загружаются в DataVault. Здесь они интегрируются, очищаются и получают полную историю. Это «единый источник фактов».
- Star Schema (Gold): Поверх DVault строятся витрины данных (Схемы Звезд). Они «разворачивают» сложную модель DV в плоские, быстрые таблицы для BI-инструментов.
Таким образом, Data Vault не заменяет «звезды», а служит для них идеальным, стабильным и аудируемым источником.
Заключение
Data Vault — это мощная, современная методология для построения корпоративных хранилищ данных. Она не проще традиционных подходов, но ее сложность оправдана. Разделяя бизнес-ключи (Хабы), отношения (Линки) и контекст (Сателлиты), Data Vault создает уникальную по своей гибкости и масштабируемости архитектуру. Она позволяет DWH развиваться вместе с бизнесом, а не тормозить его. Полная аудируемость и возможность параллельной загрузки делают ее де-факто стандартом для сложных DWH-проектов, особенно в связке с облачными MPP-платформами.
Референсные ссылки
- What is a Data Vault? Modeling & Architecture (Qlik) (https://www.qlik.com/us/data-warehouse/data-vault)
- Data Vault: Scalable Data Warehouse Modeling (Databricks) (https://www.databricks.com/glossary/data-vault)
- Introduction to Data Vault Modeling (Data Lakehouse Hub) (https://datalakehousehub.com/blog/2024-02-data-vault-modeling/)
- Data Vault Warehouse Explained, Vault vs Star Schema (AltexSoft) (https://www.altexsoft.com/blog/data-vault-architecture/)
- Beyond Traditional Warehousing: Unlock the Power of a Data Vault (Atrium) (https://atrium.ai/resources/the-power-of-a-data-vault/)