 1093
1093 
Содержание
- Ключевые столпы Data Governance
- Люди (People):
- Процессы (Processes):
- Технологии (Technology):
- Принцип работы: Как функционирует Data Governance на практике
- Сценарии использования и бизнес-ценность
- Практические шаги по внедрению Data Governance
- Преимущества и основные вызовы
- Data Governance в экосистеме Big Data
- Заключение
- Референсные ссылки
Data Governance (DG) — это организация стратегического управления данными в компании. На практике она реализуется через фреймворк, который включает в себя систему правил, процессов, политик и зон ответственности. Этот фреймворк определяет, как организация управляет своими данными на протяжении всего их жизненного цикла — от создания до архивации или удаления — с целью обеспечения их качества, безопасности и соответствия нормативным требованиям.
По своей сути, это «конституция» для мира данных компании. Как основной закон государства устанавливает права и обязанности, так и Data Governance формализует стандарты работы с информацией, превращая ее из хаотичного набора сведений в управляемый и надежный стратегический актив.
Важно не путать Data Governance с близкими, но отличными понятиями:
Data Management (Управление данными): Это более широкая область, которая включает в себя практическую реализацию и исполнение задач, связанных с данными (хранение, перемещение, обработка). Если Data Governance — это законодательная власть, определяющая что и почему нужно делать, то Data Management — это исполнительная власть, отвечающая за то, как это будет сделано.
Master Data Management (MDM): Это одна из дисциплин внутри Data Management, сфокусированная на создании единого, «золотого» источника для ключевых бизнес-сущностей (клиенты, продукты, поставщики). DG предоставляет фреймворк и правила, по которым MDM-система будет работать.
Data Quality (Качество данных): Это процесс обеспечения точности, полноты и актуальности данных. Data Governance определяет, что именно означает «качество» для разных типов данных и кто несет ответственность за его поддержание.
Таким образом, Data Governance является стратегическим уровнем управления, который создает фундамент для всех операционных активностей, связанных с данными.
Ключевые столпы Data Governance
Эффективная система управления данными строится на трех фундаментальных опорах, которые работают в тесной связке. Этими опорами, согласно ведущим отраслевым фреймворкам, таким как DAMA DMBOK (Data Management Body of Knowledge), являются люди, процессы и технологии.
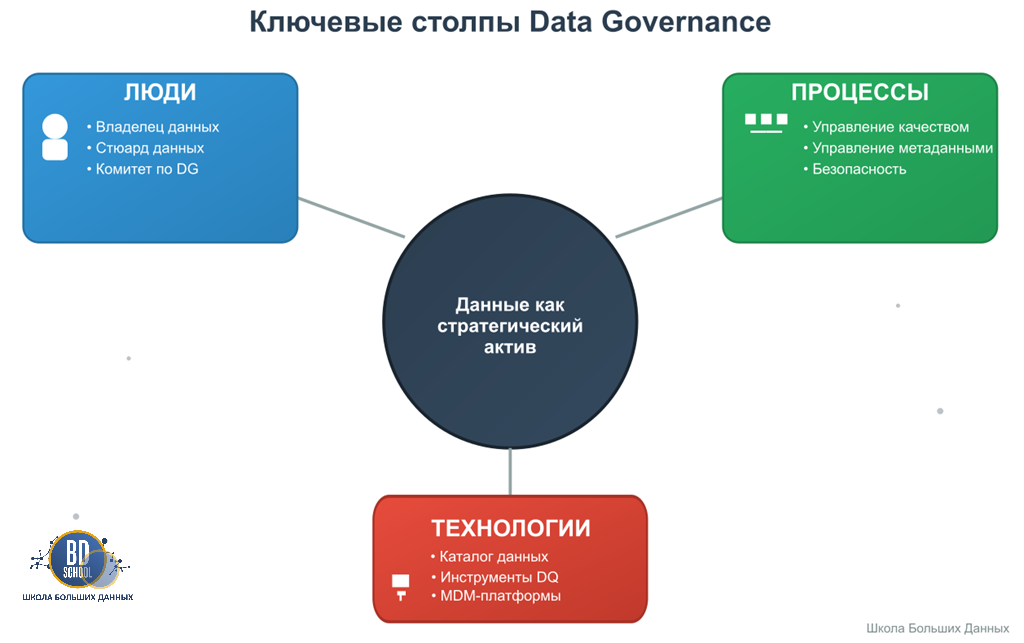
Люди (People):
Технологии и процессы мертвы без людей, которые их используют и контролируют. В Data Governance четкое распределение ролей и ответственности имеет первостепенное значение.
Владелец данных (Data Owner): Обычно это руководитель бизнес-подразделения (например, глава департамента маркетинга для клиентских данных), который несет конечную ответственность за качество, безопасность и использование определенного домена данных. Он не работает с данными напрямую, а принимает стратегические решения.
Стюард данных (Data Steward): Это тактический эксперт из бизнес-подразделения, который глубоко понимает конкретный набор данных. Он отвечает за повседневное управление: определяет правила качества, управляет метаданными, решает спорные вопросы и обеспечивает соблюдение политик, установленных Владельцем данных.
Хранитель данных (Data Custodian): Это роль на стороне ИТ. Хранители отвечают за техническую реализацию требований к данным: управляют базами данных, настраивают права доступа, обеспечивают резервное копирование и восстановление. Они обеспечивают техническую сохранность актива.
Комитет по управлению данными (Data Governance Council): Центральный координирующий орган, состоящий из Владельцев данных, ключевых стюардов и представителей ИТ. Этот комитет утверждает общие политики, разрешает междоменные конфликты и контролирует общую стратегию управления данными в компании.
Chief Data Officer (CDO): Стратегический лидер, отвечающий за реализацию Data Governance в масштабах всей организации и ее согласование с бизнес-целями.
Процессы (Processes):
Процессы определяют, как именно осуществляется управление данными. Они формализуют активности и гарантируют их повторяемость и последовательность. Фреймворк COBIT (Control Objectives for Information and Related Technologies) подчеркивает важность управляемых и измеримых процессов для всего ИТ, и Data Governance не является исключением.
- Управление метаданными (Metadata Management): Процесс сбора, документирования и поддержания информации о данных. Метаданные отвечают на вопросы: «что это за данные?», «откуда они пришли?», «кто их владелец?», «насколько они качественные?». Без управления метаданными невозможно создать прозрачную и понятную среду данных.
- Управление качеством данных (Data Quality Management): Включает в себя определение метрик качества (полнота, точность, своевременность), создание процессов для мониторинга этих метрик, а также процедур по очистке и исправлению данных.
- Обеспечение безопасности данных (Data Security): Разработка и внедрение политик, классифицирующих данные по уровню конфиденциальности и определяющих правила доступа к ним. Этот процесс тесно связан с требованиями информационной безопасности.
- Управление жизненным циклом данных (Data Lifecycle Management): Определение стадий, которые проходят данные от момента создания до архивации или удаления, и правил работы с ними на каждом этапе.
Технологии (Technology):
Технологии служат инструментами для автоматизации и поддержки людей и процессов в рамках Data Governance.
- Каталоги данных (Data Catalogs): Это централизованные репозитории метаданных. Они позволяют пользователям искать, находить и понимать доступные в компании данные. Современные каталоги используют AI для автоматического профилирования и тегирования данных. Примеры: Collibra, Alation, Atlan, Informatica Data Catalog.
- Инструменты для качества данных (Data Quality Tools): Программное обеспечение для профилирования, очистки, стандартизации и мониторинга качества данных. Они помогают автоматизировать процессы, определенные в рамках DG. Примеры: Informatica Data Quality, Talend Data Quality, Ataccama ONE.
- Платформы MDM (Master Data Management Platforms): Специализированные решения для управления мастер-данными, которые обеспечивают создание и поддержание «золотой записи».
- Средства управления политиками и доступом: Инструменты, которые помогают централизованно управлять правами доступа к данным в различных системах на основе ролей и атрибутов.
Принцип работы: Как функционирует Data Governance на практике
Внедрение и функционирование Data Governance — это не разовый проект, а циклический и непрерывный процесс, направленный на постоянное улучшение. Его можно разбить на несколько логических этапов, которые организация проходит для достижения зрелости в управлении данными.
1. Определение стратегии и целей: Все начинается с ответа на вопрос: «Зачем нам это нужно?». Руководство компании совместно с CDO или спонсором программы должно определить ключевые бизнес-драйверы. Это может быть подготовка к запуску новой ML-инициативы, требование регулятора (например, GDPR), или цель повысить эффективность маркетинговых кампаний на 20%. Цели должны быть конкретными, измеримыми и привязанными к бизнес-результатам.
2. Оценка текущего состояния (As-Is Analysis): На этом этапе проводится аудит существующих данных, процессов и ролей. Команда пытается понять, где находятся основные «болевые точки»: где данные самые некачественные, какие процессы отсутствуют, кто реально отвечает за данные сейчас. Это помогает определить приоритеты и выбрать пилотный проект.
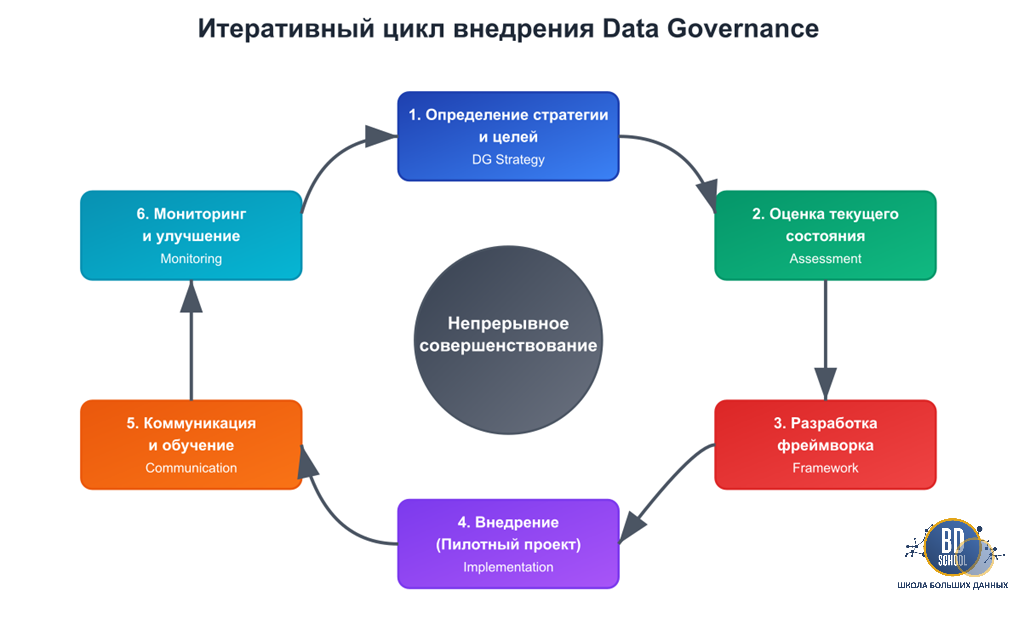
3. Разработка фреймворка и дорожной карты: На основе целей и результатов оценки разрабатывается сам фреймворк Data Governance:
- Формально определяются и назначаются роли (Владельцы, Стюарды).
- Создается и утверждается устав Комитета по управлению данными.
- Разрабатываются первые политики и стандарты (например, «Политика качества клиентских данных», «Стандарт наименования таблиц в DWH»).
- Формируется дорожная карта внедрения, которая определяет, какие домены данных, системы и процессы будут взяты под управление и в какой последовательности.
4. Внедрение и реализация (пилотный проект): Как правило, внедрение начинается с одного или двух пилотных проектов на ограниченном наборе данных, где «боль» ощущается сильнее всего. Например, это может быть домен «клиентских данных». На этом этапе Стюарды данных при помощи ИТ-Хранителей и технологических инструментов (например, каталога данных) начинают применять разработанные политики: документируют метаданные, измеряют качество, решают проблемы.
5. Коммуникация и обучение: Ключевой аспект, который часто упускают. Необходимо постоянно информировать всю компанию о целях и прогрессе программы Data Governance. Сотрудники должны понимать, почему вводятся новые правила и как ими пользоваться. Проводятся тренинги для аналитиков, разработчиков и бизнес-пользователей.
6. Мониторинг, измерение и совершенствование: Data Governance — это живой организм. Комитет по управлению данными регулярно отслеживает метрики: процент данных с определенным Владельцем, уровень качества данных в ключевых системах, количество решенных инцидентов с данными. На основе этих метрик принимаются решения о корректировке политик, расширении программы на новые домены или внедрении новых инструментов. Этот цикл повторяется, постепенно повышая зрелость управления данными во всей организации.
Сценарии использования и бизнес-ценность
Data Governance перестает быть абстрактной концепцией, когда ее прикладывают к решению реальных бизнес-задач. Ценность управления данными проявляется в конкретных и измеримых улучшениях.
Соответствие регуляторным требованиям (Compliance): В современном мире компании обязаны соблюдать строгие законы по работе с данными, такие как GDPR (Общий регламент по защите данных в ЕС) или отраслевые стандарты вроде HIPAA (в здравоохранении США). Data Governance предоставляет необходимые механизмы для этого:
- Карта данных и происхождение (Data Lineage): DG позволяет точно знать, где хранятся персональные данные, как они перемещаются между системами и как используются. Это критически важно для выполнения запросов на удаление данных («право на забвение»).
- Классификация данных: Процессы DG помогают классифицировать данные по уровню чувствительности, что позволяет применять адекватные меры защиты.
Повышение качества и достоверности аналитики: Бизнес-решения, принятые на основе некачественных данных, могут стоить компании миллионов. Data Governance напрямую решает эту проблему.
- Единый источник правды: Когда все в компании используют одни и те же определения для ключевых метрик (например, «активный клиент», «чистая выручка»), отчеты становятся согласованными, а споры о том, «чьи цифры правильные», прекращаются.
- Прозрачность качества: Аналитики и руководители видят в каталоге данных не только сами данные, но и их оценку качества. Это позволяет им принимать взвешенные решения о том, можно ли доверять этим данным для построения критически важных отчетов.
Оптимизация операционных процессов: Плохие данные ведут к прямым операционным издержкам.
- Устранение дубликатов: Процессы MDM, управляемые через DG, позволяют избавиться от дублей в клиентских базах. Это снижает затраты на маркетинг (не отправляем несколько писем одному и тому же человеку) и повышает качество обслуживания.
- Снижение затрат на ИТ: Когда данные хорошо документированы и управляемы, ИТ-специалисты тратят меньше времени на «археологию данных» — поиск нужной информации и выяснение ее происхождения.
Создание фундамента для ML и AI: Модели машинного обучения абсолютно бесполезны без качественных данных. Принцип «Garbage In, Garbage Out» (мусор на входе — мусор на выходе) здесь работает как нигде.
- Надежные обучающие выборки: DG гарантирует, что данные, используемые для обучения моделей, являются полными, точными и репрезентативными.
- Воспроизводимость моделей: Благодаря управлению метаданными и происхождением данных (data lineage), специалисты по машинному обучению могут в любой момент времени точно сказать, на каких данных обучалась модель, что критически важно для отладки и соответствия регуляторным требованиям в AI.
Архитектура ML-систем
Код курса
ARML
Ближайшая дата курса
13 апреля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Практические шаги по внедрению Data Governance
Запуск программы Data Governance — это марафон, а не спринт. Он требует стратегического планирования и поэтапного подхода.
- Определите бизнес-драйвер и заручитесь поддержкой руководства. Начните с конкретной бизнес-проблемы. Не пытайтесь «внедрить Data Governance» ради самого процесса. Найдите спонсора на уровне высшего руководства, который понимает эту проблему и готов поддерживать инициативу ресурсами.
- Начните с малого (Think Big, Start Small). Не пытайтесь охватить все данные компании сразу. Выберите один-два пилотных домена, где проблема стоит наиболее остро и где можно быстро продемонстрировать ценность. Часто начинают с клиентских данных или данных о продуктах.
- Сформируйте рабочую группу. Соберите команду, в которую войдут представители бизнеса, ИТ и аналитики. Назначьте первых стюардов и владельцев данных для пилотного домена.
- Проведите оценку и создайте глоссарий. Проанализируйте выбранный домен данных. Документируйте источники, определите ключевые термины и создайте бизнес-глоссарий. Это первый шаг к управлению метаданными.
- Разработайте первые политики. Создайте несколько простых, но важных правил. Например, «Политика обязательного наличия Владельца у каждой таблицы в DWH» или «Стандарт качества для поля ’email клиента'».
- Выберите подходящие инструменты. На начальном этапе можно обойтись простыми инструментами вроде Confluence для глоссария. По мере роста зрелости программы стоит рассмотреть внедрение специализированного каталога данных.
- Демонстрируйте результаты и расширяйтесь. После успешного завершения пилотного проекта активно рассказывайте о достигнутых результатах (например, «мы сократили время подготовки отчета X на 40%»). Используйте этот успех для расширения программы на новые домены.
Успешное планирование и реализация такой программы требуют глубокого понимания не только самих данных, но и того, как они вписываются в общую ИТ-инфраструктуру. Знания в области проектирования хранилищ и потоков данных являются критически важными. Именно поэтому специалисты, обладающие компетенциями в Архитектуре данных (ARMG) и Практической архитектуре данных (PRAR), часто становятся ключевыми фигурами при внедрении Data Governance.
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Преимущества и основные вызовы
Преимущества:
- Повышение доверия к данным: Сотрудники уверены в цифрах, на основе которых принимают решения.
- Ускорение принятия решений: Аналитики тратят меньше времени на поиск и проверку данных и больше — на сам анализ.
- Снижение рисков: Улучшается соответствие регуляторным требованиям и снижается риск утечек данных.
- «Демократизация» данных: Качественные и понятные данные становятся доступными более широкому кругу пользователей, что стимулирует инновации.
- Повышение эффективности: Сокращаются операционные издержки, связанные с ошибками в данных.
Вызовы:
- Сопротивление культуре: Data Governance требует изменения привычек. Люди могут воспринимать новые правила как лишнюю бюрократию.
- Сложность измерения ROI: Прямой финансовый эффект от внедрения DG бывает сложно посчитать, так как многие выгоды являются косвенными.
- Требует постоянных усилий: Это не проект с началом и концом, а непрерывный процесс, требующий выделенных ресурсов.
- Начальные затраты: Внедрение специализированных инструментов и выделение времени сотрудников требует инвестиций.
Data Governance в экосистеме Big Data
Классические подходы к Data Governance были разработаны в эпоху структурированных реляционных баз данных. Экосистема Big Data с ее огромными объемами, разнообразием и скоростью поступления данных бросает новые вызовы.
- Управление Data Lake: В «озере данных» хранятся как сырые, так и обработанные данные различных форматов. Data Lake Governance фокусируется на том, чтобы озеро не превратилось в «болото данных». Для этого используются каталоги данных, которые автоматически индексируют новые датасеты, и вводятся зоны (например, raw, curated, trusted), чтобы пользователи понимали, данные какого качества они используют.
- Управление потоковыми данными: Технологии, такие как Apache Kafka, позволяют обрабатывать данные в режиме реального времени. Управление такими данными требует внедрения схем данных (Schema Registry) для контроля структуры сообщений «на лету» и механизмов отслеживания происхождения данных в сложных конвейерах обработки. Эффективная работа с такими системами требует специальных знаний, которые можно получить на курсах, посвященных Apache Kafka.
- Качество в распределенных системах: При обработке данных с помощью Apache Spark на кластере из сотен узлов, процессы проверки качества должны быть встроены непосредственно в конвейеры (pipelines). Используются библиотеки вроде Deequ для автоматического профилирования и валидации данных в масштабе петабайт. Глубокое понимание основ Spark является необходимым условием для построения таких управляемых систем.
Data Governance в мире Big Data становится более автоматизированной, динамичной и встроенной в жизненный цикл данных, отходя от ручных процессов в сторону «Governance as Code».
Заключение
В современной экономике, где данные признаны одним из самых ценных активов, игнорирование управления ими равносильно пренебрежению основными фондами компании. Data Governance — это не модный тренд и не лишняя бюрократия, а стратегическая необходимость, которая создает прочный фундамент для цифровой трансформации. Она превращает данные из источника проблем в двигатель инноваций, повышает операционную эффективность и позволяет принимать решения, основанные на фактах, а не на интуиции. Внедрение Data Governance — это сложный, но необходимый путь для любой организации, стремящейся стать по-настоящему data-driven. Это инвестиция в прозрачность, надежность и, в конечном счете, в конкурентоспособность бизнеса в долгосрочной перспективе.
Референсные ссылки
- Обзор структуры DAMA DMBOK2 и ее областей знаний в сфере информационного менеджмента. https://www.dama.org/cpages/dmbok
- Принципы и структура фреймворка COBIT 2019 для аудита и управления корпоративными ИТ. https://www.isaca.org/resources/cobit
- Стратегический взгляд на эволюцию роли директора по данным (CDO) от McKinsey. https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-data-driven-enterprise-of-2025
- Аналитический отчет Gartner о рынке решений для каталогизации корпоративной информации (Magic Quadrant for Metadata Management). https://www.gartner.com/en/documents/4002471