 289
289 
Содержание
- Архитектура и ключевые особенности
- Software-Defined Assets (Программно-определяемые активы)
- Менеджеры ввода-вывода (I/O Managers)
- Контекст исполнения (Resources)
- Принцип работы и механизм оркестрации
- Как установить Dagster
- Сценарии использования Dagster
- Планирование и запуск конвейеров
- Взаимодействие кодом: Создание пайплайна на Python
- Сравнение подходов оркестарторов Dagster против Apache Airflow
- Изолированное тестирование дата-пайплайнов
- Заключение
- Референсные ссылки
Dagster — это оркестратор данных, предназначенный для разработки, выполнения и мониторинга пайплайнов обработки данных на основе DAG, с акцентом на типизацию данных, тестируемость и прозрачность выполнения. Главная цель этого инструмента состоит в управлении активами данных. Активы включают таблицы, файлы и модели машинного обучения. Традиционные оркестраторы фокусируются исключительно на порядке выполнения задач. Например, они просто запускают скрипты по расписанию. Однако, Dagster ставит в центр внимания сами производимые данные. Это принципиально новый подход в области управления данными. Разработчики переходят от концепции «выполни скрипт» к «получи данные».
Развитие инженерии данных требует новых инструментов для работы. Объем информации в современных компаниях растет экспоненциально каждый год. Старые системы оркестрации перестают справляться с возросшей сложностью зависимостей. Инженеры тратят слишком много времени на поиск ошибок выполнения. Данный инструмент предлагает решать эти проблемы на архитектурном уровне. Платформа объединяет процессы разработки, тестирования и мониторинга пайплайнов. Таким образом, разработчики всегда знают статус и качество своих данных. В результате скорость доставки новых аналитических решений бизнесу многократно возрастает.
Архитектура и ключевые особенности
Архитектура платформы строится вокруг декларативного описания графа вычислений. Разработчики определяют конечный результат в виде желаемого состояния данных. Оркестратор самостоятельно решает задачу достижения этого финального состояния. Этот современный подход радикально снижает сложность поддержки запутанного кода. В основе системы лежит несколько важных и независимых компонентов. Рассмотрим основные архитектурные концепции этой системы более детально.
Software-Defined Assets (Программно-определяемые активы)
Концепция активов является главным функциональным ядром всей платформы. Инженер пишет обычную функцию на языке программирования Python. Эта функция физически возвращает конкретный набор или таблицу данных. Специальный декоратор превращает эту функцию в независимый логический актив. Система автоматически отслеживает все связи и зависимости между активами. Оркестратор строит визуальный граф потока данных на основе кода. Следовательно, обновление одной таблицы каскадно запускает обновление зависимых витрин. Разработчику больше не нужно вручную прописывать порядок выполнения задач.

Менеджеры ввода-вывода (I/O Managers)
Менеджеры ввода-вывода эффективно разделяют бизнес-логику и физическое хранение данных. Код аналитической функции ничего не знает о конкретной базе. Он просто принимает и возвращает стандартные объекты языка Python. Менеджер берет на себя рутинную задачу записи DataFrame в хранилище. Например, один менеджер может писать итоговые данные в Snowflake. Другой менеджер сохранит те же самые данные в локальный файл. Переключение между хранилищами происходит путем изменения одной строки конфигурации. Это делает программный код невероятно гибким и легко тестируемым.
Контекст исполнения (Resources)
Ресурсы позволяют централизованно управлять внешними зависимостями в вашем проекте. К ним относятся подключения к базам данных и различные ключи. Во время локальной разработки вы используете одни тестовые ресурсы. При переносе кода в продакшен ресурсы легко подменяются боевыми. При этом сам исходный код дата-пайплайна остается абсолютно неизменным. Внедрение зависимостей происходит на этапе сборки графа выполнения задач. Таким образом, устраняется огромный класс ошибок конфигурации тестового окружения.
Принцип работы и механизм оркестрации
Механизм работы опирается на построение направленного ациклического графа. Но узлами этого графа выступают не задачи, а активы. Платформа сканирует ваш исходный код при каждом новом запуске. Оркестратор анализирует код и строит детальную карту всех зависимостей. Затем он определяет, какие данные нуждаются в срочном обновлении. Пользователь может запросить обновление конкретного финального финансового отчета. Система автоматически вычислит, какие промежуточные таблицы устарели к этому моменту. Затем она запустит только необходимые функции для вычисления итогового результата.
Это экономит огромные вычислительные ресурсы и время работы кластера. Вы не пересчитываете те таблицы, которые не изменились со вчерашнего дня. Кроме того, система бережно хранит историю всех материализаций активов. Вы всегда можете посмотреть, как данные выглядели неделю назад. Разработчик всегда может отследить происхождение любой проблемной строки данных. Интерфейс системы предоставляет инструменты для быстрого профилирования производительности скриптов. Это позволяет легко находить узкие места в конвейерах обработки.
Apache Airflow для инженеров данных
Код курса
AIRF
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Как установить Dagster
Запуск платформы требует глубокого понимания ее внутренней компонентной базы. Система состоит из нескольких независимых и масштабируемых микросервисов. Среди них выделяются веб-сервер, планировщик фоновых задач и база данных. Процесс развертывания логично разделить на несколько основных технических подходов.
Локальное развертывание. Это самый простой и быстрый способ начать работу.
- Запуск системы осуществляется буквально одной командой в терминале разработчика.
- Используется встроенный легковесный веб-сервер для визуализации графиков.
- Все метаданные пайплайнов локально сохраняются во встроенную базу SQLite.
Развертывание в Docker. Этот метод отлично подходит для небольших изолированных команд.
- Все системные компоненты аккуратно упаковываются в независимые легковесные контейнеры.
- В качестве надежной базы данных метаданных обычно используется PostgreSQL.
- Запуск всей конфигурации выполняется через привычный инструмент Docker Compose.
Промышленное развертывание на Kubernetes. Это золотой стандарт для крупных корпоративных проектов.
- Используется официальный готовый Helm Chart для быстрой установки системы.
- Поддерживается динамическое горизонтальное масштабирование рабочих узлов под высокой нагрузкой.
- Обеспечивается высокая доступность абсолютно всех критичных сервисов современного оркестратора.
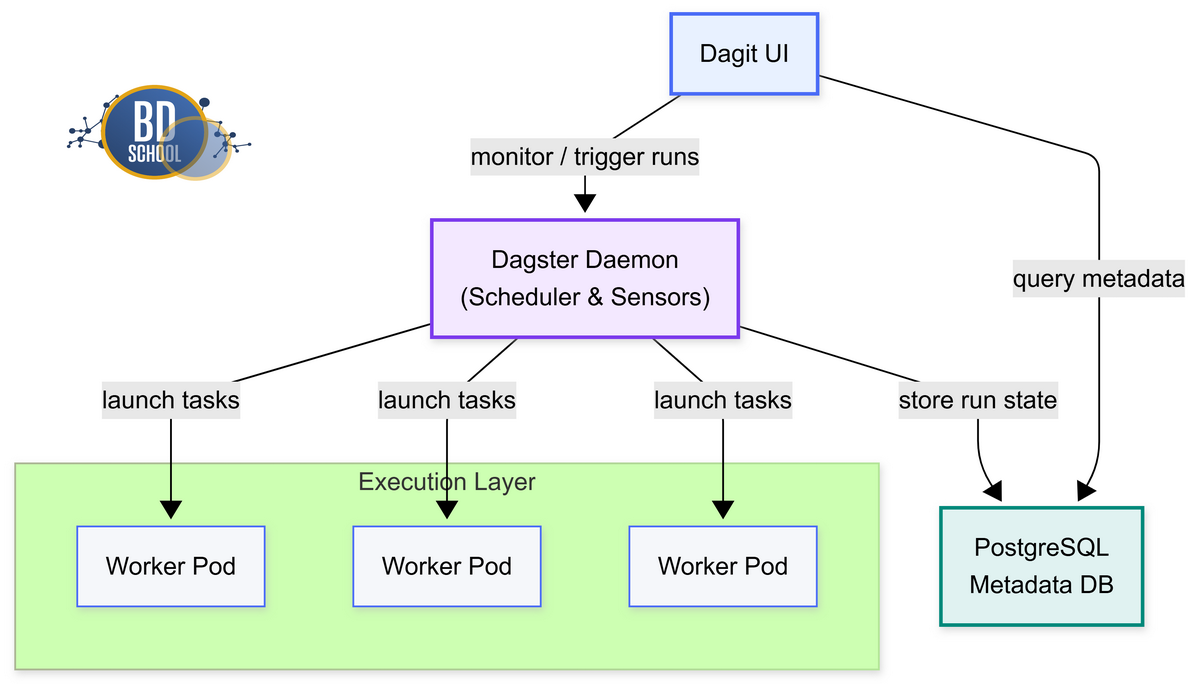
Таким образом, окончательный выбор метода зависит от масштаба вашего текущего проекта. Начать активную разработку можно локально, а затем легко мигрировать. Переход между средами выполнения происходит без изменения пользовательского кода. Это существенно экономит время инженеров при настройке базовой инфраструктуры.
Сценарии использования Dagster
Инструмент отлично подходит для решения самых сложных современных аналитических задач. Он закрывает базовые потребности как инженеров данных, так и аналитиков. Различные плагины позволяют интегрировать платформу с популярными облачными хранилищами. Ниже представлены самые востребованные сценарии применения этой платформы в бизнесе.
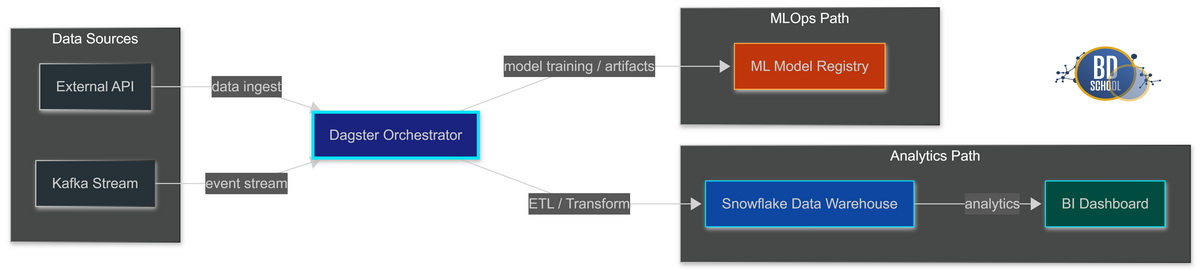
Интеграция с инструментом dbt. Dagster умеет парсить проекты трансформации данных.
- Каждая отдельная модель dbt становится полноценным активом в оркестраторе.
- Пользователи видят визуальную связь между сырыми данными и моделями.
- Ошибки в коде локализуются прямо в удобном интерфейсе управления.
Машинное обучение (MLOps). Платформа контролирует весь сложный жизненный цикл моделей.
- Автоматическая подготовка качественных признаков для алгоритмов обучения нейросетей.
- Регулярная тренировка алгоритмов на самых свежих исторических выборках данных.
- Надежное сохранение артефактов готовых моделей в специализированные объектные хранилища.
Аналитика и бизнес-отчетность. Инструмент гарантирует ежедневную свежесть важных бизнес-метрик.
- Точный расчет сложных показателей на основе десятков различных источников.
- Автоматическая генерация и рассылка ежедневных управленческих дашбордов руководству компании.
- Мгновенная отправка уведомлений о готовности свежих данных бизнес-пользователям.
Следовательно, платформа является мощным универсальным решением для любых дата-команд. Она позволяет органично объединить совершенно разные стеки технологий в единый конвейер.
Apache Airflow для инженеров данных
Код курса
AIRF
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Планирование и запуск конвейеров
Автоматический запуск заданий является базовой функцией абсолютно любого современного оркестратора. Система предлагает несколько совершенно разных подходов к решению этой важной задачи. Выбор конкретного инструмента зависит от специфики бизнес-требований к свежести данных.
Классические расписания. Это самый понятный и традиционный метод регулярного запуска.
- Позволяет запускать периодическое обновление активов по заданному системному времени.
- Идеально подходит для формирования регулярных ежедневных или еженедельных бизнес-отчетов.
- Поддерживает строгий учет различных часовых поясов и настройку периода выполнения.
Декларативные сенсоры. Это более продвинутый и реактивный способ управления пайплайнами.
- Сенсор непрерывно отслеживает внешние изменения в системах и облачных хранилищах.
- Запуск графа происходит только при появлении нового файла в корзине.
- Это позволяет строить по-настоящему событийно-ориентированную архитектуру обработки потоковых данных.
Автоматическая материализация. Это самая передовая функция данного инструмента оркестрации данных.
- Вы задаете декларативные правила свежести для конкретных важных таблиц.
- Система сама решает, когда нужно запустить фоновое обновление промежуточных активов.
- Вмешательство человека в планирование запусков сводится к абсолютному техническому минимуму.
Такое богатство инструментов планирования делает платформу исключительно гибкой и очень мощной. Вы можете свободно комбинировать разные подходы в рамках одного большого проекта.
Взаимодействие кодом: Создание пайплайна на Python
Программный интерфейс этого фреймворка отличается особой элегантностью и простотой. Инженеры и разработчики пишут обычный чистый код на языке Python. Специальные декораторы фреймворка превращают этот базовый код в готовый конвейер. Порог входа в технологию остается достаточно низким для начинающих специалистов. Рассмотрим подробный практический пример загрузки и обработки простого набора данных.
#--- перед созданием скрипта DAG установим необходимые пакеты pandas, dagster и dagster-webserver в venv
python3 -n venv venv
source venv/bin/active
pip3 install pandas dagster
#--- создаем DAG sample_pd.py
import pandas as pd
from dagster import asset, Output
@asset
def raw_users_data() -> Output[pd.DataFrame]:
"""Загрузка сырых данных о пользователях из внешнего источника."""
data = {"id": [1, 2, 3], "name": ["Alice", "Bob", "Charlie"]}
df = pd.DataFrame(data)
# Добавление полезных метаданных к активу
return Output(
value=df,
metadata={
"row_count": len(df),
"source": "internal_api"
}
)
@asset
def active_users(raw_users_data: pd.DataFrame) -> pd.DataFrame:
"""Фильтрация активных пользователей для построения итогового отчета."""
df = raw_users_data.copy()
df["is_active"] = True
return df
Запустить этот код очень просто. Сначала нужно подготовить локальное рабочее окружение. Для этого мы используем встроенные инструменты фреймворка.
-
Сохранение кода. Скопируй этот скрипт в новый файл. Назови его, например, sample_pd.py.
-
Установка библиотек. Открой командную строку. Выполни команду pip3 install dagster dagster-webserver pandas.
-
Запуск сервера. Введи в терминале команду dagster dev -f sample_pd.py.
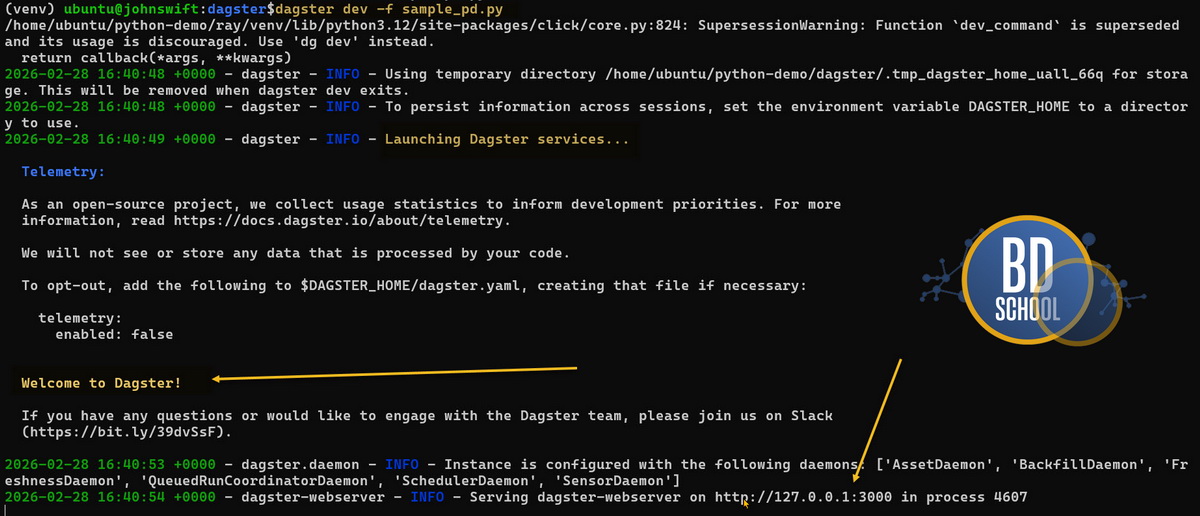
-
Интерфейс управления. Открой браузер по адресу
http://localhost:3000.
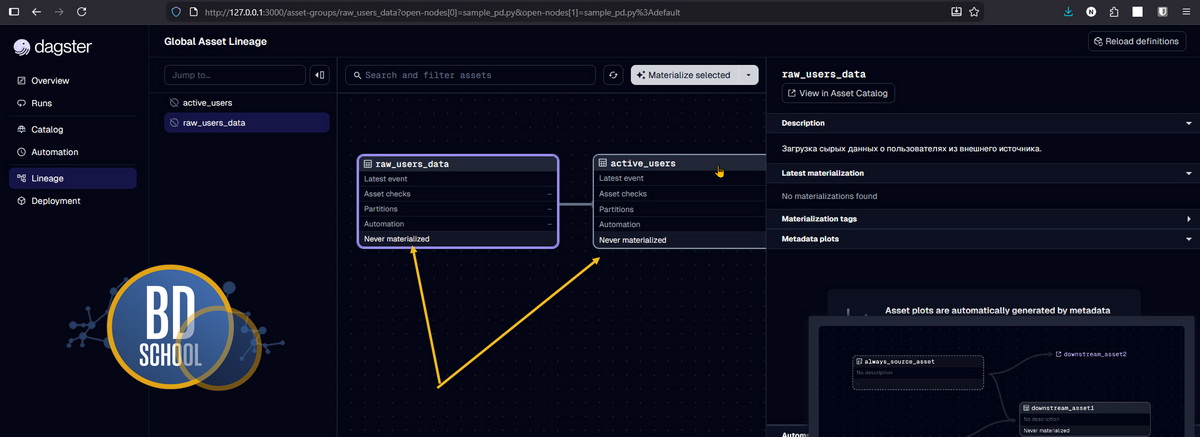
-
Материализация. Нажми кнопку «Materialize all» в правом верхнем углу.
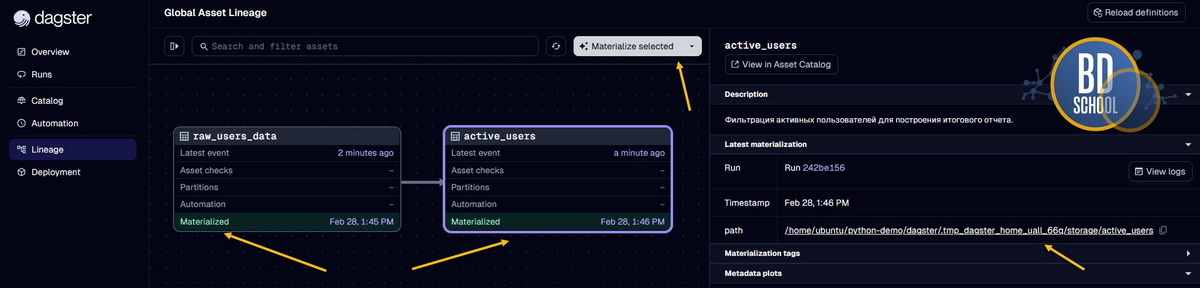
В этом небольшом коде мы успешно создали два зависимых актива. Функция active_users принимает результат работы функции raw_users_data как аргумент. Система автоматически понимает эту тесную связь через стандартные аргументы функции. При запуске графа оркестратор сначала материализует самый первый сырой датафрейм. Затем он безопасно передаст его во вторую функцию для финальной обработки.
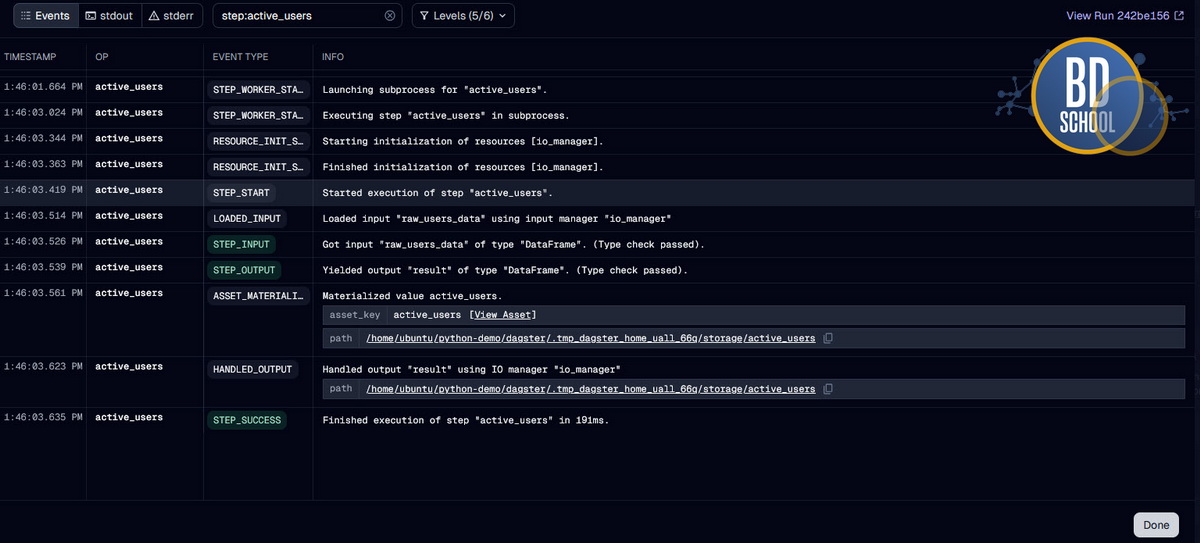
Никакой сложной ручной настройки передачи состояния здесь совершенно не требуется. Кроме того, первый актив возвращает полезные метаданные о количестве строк. Эти ценные метрики будут красиво отображаться в веб-интерфейсе системы мониторинга.
Кроме того, можно запустить код программно без графического интерфейса. Это очень полезно для быстрого тестирования. Добавь следующий небольшой блок в самый конец твоего файла.
from dagster import materialize
if __name__ == "__main__":
# Локальный запуск вычислений в памяти
result = materialize([raw_users_data, active_users])
print("Статус выполнения:", result.success)
После этого просто запусти скрипт стандартной командой python3 sample_pd. Инструмент выполнит все нужные функции в оперативной памяти. Это отличный базовый способ для отладки аналитической логики. Итоговый результат будет выведен прямо в консоль.
Сравнение подходов оркестарторов Dagster против Apache Airflow
Выбор между этими двумя популярными инструментами часто вызывает горячие дискуссии. Airflow долгое время заслуженно оставался неоспоримым индустриальным стандартом сложной оркестрации. Однако новые современные подходы предлагают более элегантные решения многих старых проблем. Давайте объективно сравним их по нескольким ключевым техническим параметрам проектирования.
| Характеристика | Dagster | Apache Airflow |
|---|---|---|
| Главная рабочая сущность | Активы данных (Фокус на Данные) | Задачи и скрипты (Фокус на Процессы) |
| Механизм передачи состояния | Встроенная поддержка (I/O Managers) | Очень сложная маршрутизация (XComs) |
| Удобство локальной разработки | Нативная поддержка и высокая скорость | Требует долгой настройки локального окружения |
| Модульное тестирование кода | Изолированное, простое и невероятно быстрое | Затруднено, часто требует поднятия базы данных |
| Интерфейс системы | Полный фокус на отслеживании происхождения | Строгий фокус на мониторинге статуса выполнения |
Очевидно, что каждый отдельный инструмент имеет свои неоспоримые сильные стороны. Airflow обладает по-настоящему огромным сообществом и тысячами готовых пакетных интеграций. Найти ответ на проблему с Airflow в интернете гораздо проще. В то же время, Dagster предлагает объективно лучший современный опыт разработчика. Он заставляет писать более чистый, модульный и легко тестируемый программный код.
Изолированное тестирование дата-пайплайнов
Качественное тестирование кода работы с данными всегда было сложной задачей. Разработчикам часто приходилось поднимать тяжелые базы данных для проверки логики. Это сильно замедляло процессы разработки и интеграции новых полезных фич. Данный современный фреймворк решает эту острую проблему на фундаментальном архитектурном уровне.
Во-первых, функции обработки данных физически отделены от сложной среды выполнения. Вы можете легко вызвать функцию актива как самый обычный метод Python. Во-вторых, встроенные менеджеры ресурсов позволяют легко создавать изолированные программные заглушки. В локальной тестовой среде вы просто передаете ресурс оперативной памяти. В результате, весь код пайплайна тестируется в памяти за считанные миллисекунды. Вам совершенно не нужно долго ждать загрузки тяжелых виртуальных Docker контейнеров.
Такой инновационный подход внедряет лучшие практики классической разработки программного обеспечения. Инженеры данных наконец-то могут писать полноценные изолированные модульные автоматические тесты. Качество и общая надежность аналитических решений при этом предсказуемо возрастают. Исходный код становится более стабильным и максимально безопасным для технического рефакторинга. Эти автоматические тесты можно легко интегрировать в стандартный процесс CI/CD пайплайнов.
from dagster import materialize_to_memory
def test_active_users_logic():
"""Пример модульного теста для нашего пайплайна."""
# Запускаем граф вычислений прямо в оперативной памяти
result = materialize_to_memory([raw_users_data, active_users])
# Проверяем успешность выполнения всех задач
assert result.success
# Извлекаем финальный датафрейм и проверяем логику
df = result.output_for_node("active_users")
assert len(df) == 3
assert df["is_active"].all() == True
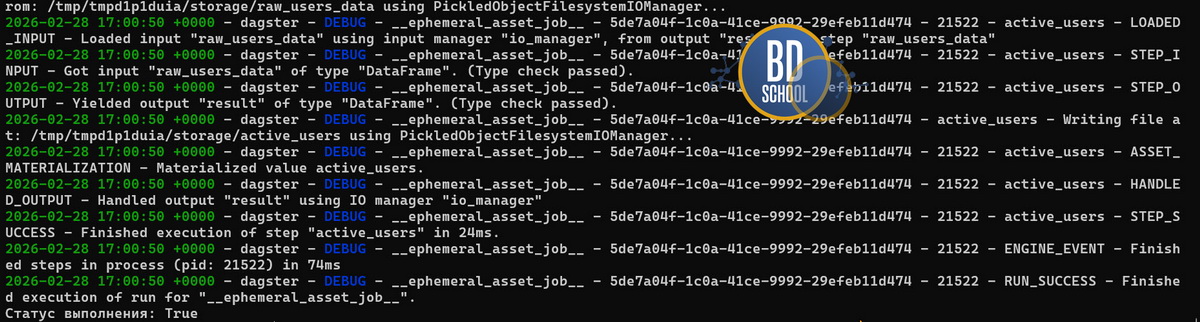
Этот тест выполняется мгновенно и не требует внешних баз данных. Таким образом, цикл обратной связи для инженера данных сокращается до минимума.
Заключение
Оркестратор Dagster представляет собой мощный эволюционный шаг вперед в инженерии данных. Концепция программно-определяемых активов смещает фокус с рутинных процессов на бизнес-результаты. Это позволяет современным дата-командам создавать более надежные и абсолютно прозрачные системы. Внедрение этого инновационного инструмента требует изменения привычного классического мышления инженеров. Необходимо перестать мыслить отдельными скриптами и начать думать готовыми дата-продуктами. Однако итоговое высокое качество кода полностью оправдывает все затраченные усилия. Вы получаете предсказуемую, легко тестируемую и масштабируемую архитектуру аналитического решения.
Референсные ссылки
- [Dagster Official Documentation] (https://docs.dagster.io)
- [Software-Defined Assets Concept] (https://dagster.io/blog/software-defined-assets)
- [Deploying Dagster on Kubernetes via Helm] (https://docs.dagster.io/deployment/guides/kubernetes/deploying-with-helm)
- [Dagster vs Apache Airflow Comparison] (https://dagster.io/blog/dagster-vs-airflow)