 604
604 
Содержание
DAG (Directed Acyclic Graph) — это ориентированная ацикличная структура, используемая для формального описания зависимостей и упорядочивания вычислительных процессов таким образом, чтобы исключить циклы и обеспечить строго определённую последовательность выполнения.
В отличие от простых списков дел, DAG позволяет моделировать сложные нелинейные процессы, где одни задачи могут выполняться параллельно, а другие строго ждут завершения предшественников. В современной инженерии данных это не просто математическая абстракция, а физический «скелет» любого ETL-процесса или ML-пайплайна.
Анатомия: Разбираем аббревиатуру
Чтобы понять, почему DAG стал стандартом в Big Data, нужно разобрать каждое слово его названия. Это не просто термины, а набор жестких ограничений, которые гарантируют стабильность системы.
Рассмотрим три фундаментальных свойства:
- Directed (Ориентированный).
Связи в графе всегда имеют направление. Это вектор времени и логики. Если задача А связана с задачей Б, это значит, что А передает данные или управление задаче Б. Движение вспять невозможно. Это свойство превращает хаотичные связи в понятный поток данных (Data Flow). - Acyclic (Ациклический).
В структуре строго запрещены замкнутые маршруты. Выйдя из точки А, вы никогда не сможете в неё вернуться, двигаясь по стрелкам. Это критически важно для автоматизации: если бы в графе был цикл, программа могла бы попасть в «вечную петлю» (infinite loop), потребляя ресурсы сервера до его падения. - Graph (Граф).
Это математическая модель, состоящая из Вершин (Nodes/Vertices) и Ребер (Edges). В контексте IT, вершины — это блоки кода (скрипты, SQL-запросы, API-вызовы), а ребра — это правила очередности («сначала скачай, потом обработай»).
Таким образом, DAG — это гарантия того, что любой запущенный процесс рано или поздно закончится (успехом или ошибкой), но никогда не зависнет в логической ловушке.
Механизм работы: Топологическая сортировка
Как компьютер понимает, в каком порядке выполнять задачи, если граф выглядит как запутанная паутина? Для этого используется алгоритм топологической сортировки.
Суть алгоритма заключается в линеаризации графа. Представьте, что вы одеваетесь. У вас есть зависимости: «носки надеть до ботинок», «трусы до брюк», но «майку» и «носки» можно надеть в любом порядке. Топологическая сортировка берет эти правила и выстраивает единую цепочку действий.
Важные следствия этого процесса:
- Детерминизм: Даже если граф сложный, планировщик всегда знает валидный порядок действий.
- Параллелизм: Алгоритм выявляет задачи, которые не зависят друг от друга (находятся на одной глубине графа). Оркестратор может отправить их на разные ядра процессора или разные серверы кластера, ускоряя обработку в разы.
Проблема циклических процессов: «А если цикл нужен?»
Это один из самых сложных вопросов архитектуры. Бизнес-логика часто бывает цикличной.
Пример: «Обучай нейросеть. Проверь точность. Если точность ниже 90% — повтори обучение с новыми параметрами».
На первый взгляд, это нарушает принцип «Acyclic». Однако в Data Engineering эта проблема решается не созданием «циклического графа», а архитектурными паттернами.
Apache Airflow для инженеров данных
Код курса
AIRF
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Как решают задачи с циклами, оставаясь в рамках DAG:
Разворачивание цикла (Unrolling).
Если количество итераций известно заранее (например, обработать данные за 10 лет по годам), DAG генерируется динамически. Вместо одного цикла создается 10 последовательных или параллельных задач: Task_2010, Task_2011… Task_2020. Граф остается ацикличным, просто становится шире.
Генератор DAG (Controller DAG).
Создается один маленький DAG, задача которого — проверять условие и, если нужно, запускать другой DAG (TriggerDagRunOperator в Airflow). Таким образом, каждый запуск — это новый, отдельный экземпляр процесса (DAG Run), который линеен. Цикл реализуется на уровне мета-управления, а не внутри одной структуры.
Внутренняя логика задачи.
Если цикл локальный (например, попытка подключения к API), он прячется внутри Python-кода одной задачи. Для внешнего наблюдателя (оркестратора) это всё ещё одна вершина графа.
Таким образом, мы сохраняем безопасность ацикличной структуры, но реализуем цикличную бизнес-логику.
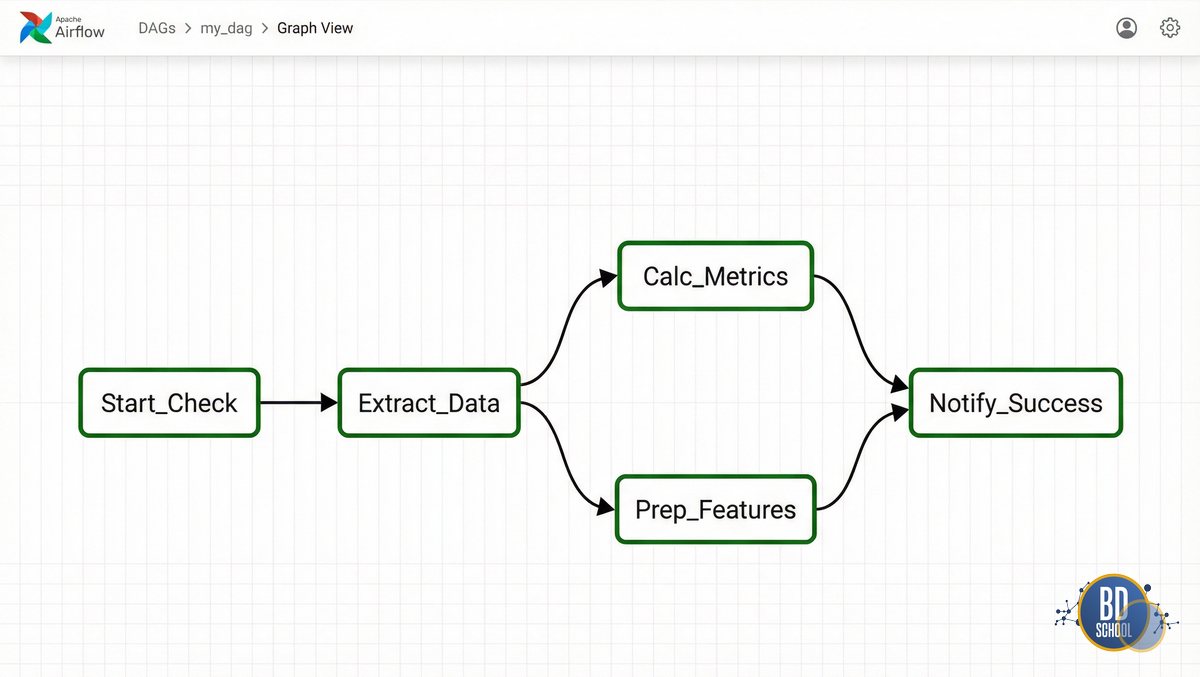
Практикум 1: DAG в Apache Airflow
В Airflow каждый пайплайн — это DAG, описанный на Python. Ниже представлен полноценный пример ETL-процесса.
Мы эмулируем ситуацию: скачать данные, параллельно их обработать двумя способами и собрать отчет.
Подготовка окружения (Ubuntu/WSL) — Для запуска в WSL/Linux нужен установленный Docker
# Создаем папку проекта mkdir airflow-dag-demo && cd airflow-dag-demo # Скачиваем официальный docker-compose файл curl -LfO 'https://airflow.apache.org/docs/apache-airflow/2.7.1/docker-compose.yaml' #-- для получения AIRFLOW UID создаем файл .env для текущего пользователя, и теперь мы можем получить доступ к папке с DAGs echo "AIRFLOW_UID=$(id -u)" > .env # Инициализация и запуск docker compose up airflow-init docker compose up -d
Если ваш компьютер или ноутбук не слишком мощный придется подождать когда AirFlow и сервисы полностью прогрузятся
Код DAG (сохранить как ~/dags/wiki_example_dag.py)
from datetime import datetime
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.operators.bash import BashOperator
# 1. Python-функции, которые будут выполняться в задачах
def extract_data():
print("Эмуляция: Скачиваем данные из API...")
return "raw_data.json"
def process_metrics():
print("Ветка А: Считаем сложные метрики...")
def process_ml_features():
print("Ветка Б: Готовим фичи для ML...")
# 2. Определение контекста DAG
# catchup=False означает, что мы не пытаемся запустить пропущенные интервалы
with DAG(
dag_id='wiki_etl_dag',
start_date=datetime(2023, 10, 1),
schedule_interval=None,
catchup=False,
tags=['wiki', 'example']
) as dag:
# 3. Определение задач (Вершины графа)
# Задача 1: Bash-команда (проверка окружения)
t1_check = BashOperator(
task_id='check_environment',
bash_command='echo "System ready checking paths..."'
)
# Задача 2: Python-функция (Экстракт)
t2_extract = PythonOperator(
task_id='extract_data',
python_callable=extract_data
)
# Задачи 3 и 4: Параллельная обработка
t3_metrics = PythonOperator(
task_id='calculate_metrics',
python_callable=process_metrics
)
t4_features = PythonOperator(
task_id='prepare_ml_features',
python_callable=process_ml_features
)
# Задача 5: Финализация
t5_notify = BashOperator(
task_id='send_notification',
bash_command='echo "Pipeline finished successfully!"'
)
# 4. Определение зависимостей (Ребра графа)
# Используем битовые операторы >> для построения потока
# t1 -> t2
t1_check >> t2_extract
# t2 разветвляется на t3 и t4 (они пойдут параллельно)
t2_extract >> [t3_metrics, t4_features]
# t3 и t4 должны закончиться перед t5
[t3_metrics, t4_features] >> t5_notify
Что происходит в коде:
- Конструкция [t3, t4] создает ветвление.
- Airflow видит, что эти задачи не зависят друг от друга, и если у вас есть свободные слоты (Workers), запустит их одновременно.
- Задача t5_notify (Wait Operation) не начнется, пока обе ветки не отчитаются об успехе.
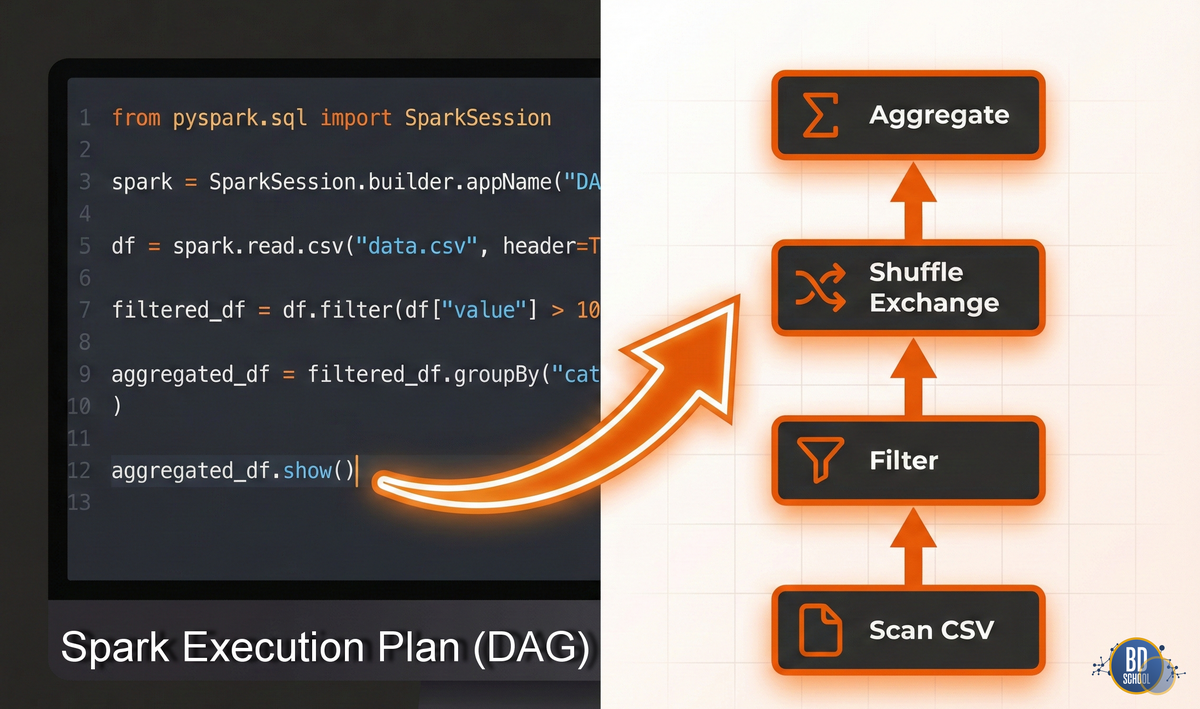
Практикум 2: DAG в Apache Spark
В Spark вы редко строите DAG вручную, как в Airflow. Здесь DAG — это план выполнения (Execution Plan), который оптимизатор строит за вас. Spark использует концепцию Lazy Evaluation (ленивые вычисления): код не выполняется, пока вы не попросите результат (Action).
Подготовка окружения (Ubuntu/WSL)
# Необходима Java и сам Spark (через pip ставится обертка) sudo apt install default-jdk python3-pip pip install pyspark #--- возможно понадобится установить поддержку VENV sudo apt install python3.12-venv python3 -m venv venv/ source venv/bin/activate
Код для демонстрации DAG в Spark (сохранить как spark_dag_demo.py)
from pyspark.sql import SparkSession
import time
# Инициализация сессии
spark = SparkSession.builder \
.appName("WikiDAGDemo") \
.master("local[*]") \
.getOrCreate()
# Отключаем лишние логи, чтобы видеть вывод
spark.sparkContext.setLogLevel("ERROR")
print("1. Создаем DataFrame (Вершина 1)...")
data = [("Alice", 25), ("Bob", 30), ("Charlie", 35), ("David", 25)]
df = spark.createDataFrame(data, ["name", "age"])
print("2. Определяем трансформации (Строим DAG в памяти)...")
# Эти строки НЕ запускают обработку данных.
# Они лишь добавляют узлы в граф.
# Узел фильтрации
filtered_df = df.filter(df.age > 25)
# Узел преобразования
renamed_df = filtered_df.withColumnRenamed("name", "full_name")
print("--- На этом этапе данные еще не обработаны! ---")
print("Spark лишь записал шаги (Lineage/Родословную).")
time.sleep(2)
print("\n3. Вызываем Action (Запуск выполнения DAG)...")
# collect() или show() заставляют Spark пройти по построенному графу
renamed_df.show()
print("\n4. Визуализация плана:")
# Метод explain() показывает текстовое представление DAG
renamed_df.explain()
spark.stop()
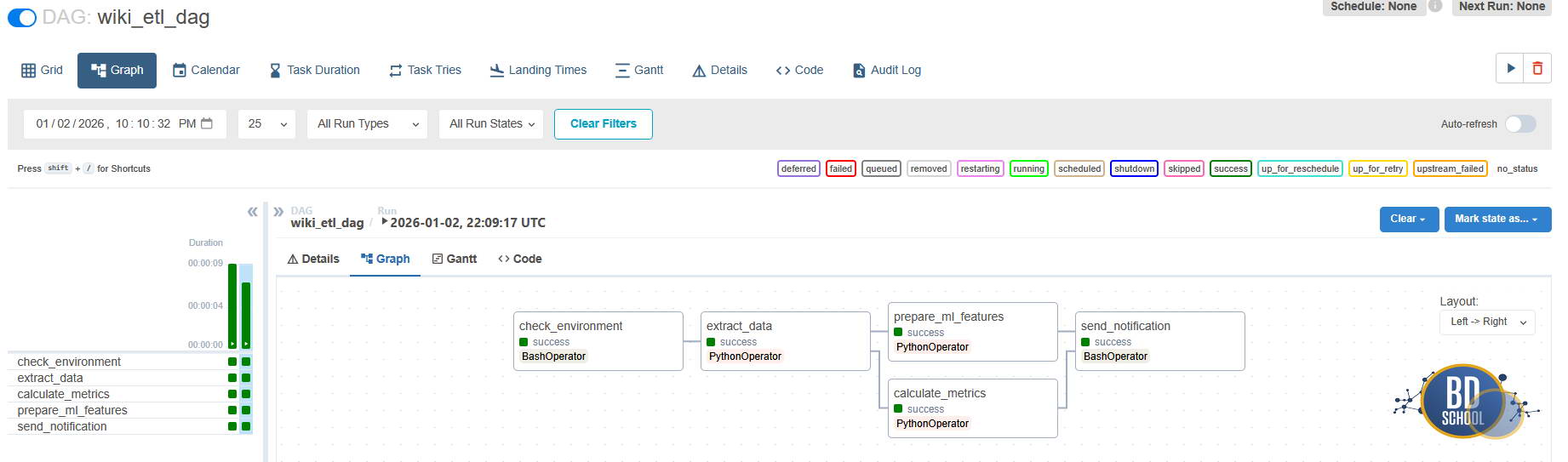
Результат explain():
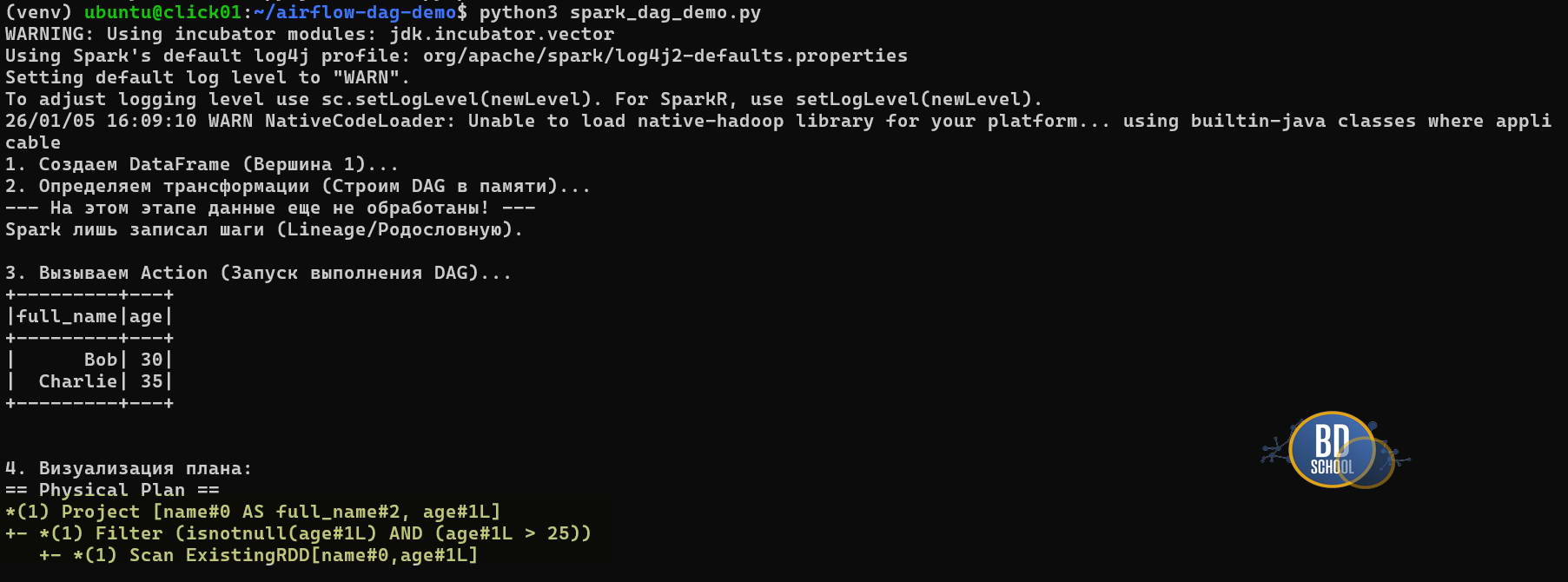
Давайте разберем результат выполнения скрипта более подробно:
Самая интересная часть вашего скриншота — это последние строки под заголовком Physical Plan. Это и есть то самое текстовое представление DAG, о котором шла речь в коде. Spark показывает, как именно он оптимизировал и выполнил вашу логику, читая снизу вверх:
-
Scan ExistingRDD: Это начало графа (листа). Spark считал данные, которые вы создали вручную (
data = [...]). -
Filter: Следующий шаг. Обратите внимание, что Spark автоматически добавил проверку
isnotnull(age#1L), хотя мы просили толькоage > 25. Это работа оптимизатора Catalyst: он знает, что сравнение с NULL может вызвать ошибки или неверные результаты, и заранее отсекает пустые значения. -
Project: Это финальный шаг проекции. Здесь происходит переименование столбца
nameвfull_nameи выборка финального набора полей для вывода.
Звездочки *(1) перед операциями означают, что Spark использовал Whole-Stage Code Generation. Он не выполнял эти шаги по очереди медленно, а «схлопнул» их в одну оптимизированную Java-функцию для максимальной скорости.
Анализ данных с помощью современного Apache Spark
Код курса
SPARK
Ближайшая дата курса
6 апреля, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Сравнение с другими структурами
Чтобы окончательно закрепить понимание, сравним DAG с его ближайшими «родственниками».
| Характеристика | Дерево (Tree) | DAG (Граф) | Циклический граф |
| Родители | У узла строго 1 родитель (кроме корня). | У узла может быть много родителей. | Много родителей. |
| Маршруты | Ветви только расходятся. | Ветви расходятся и могут сливаться обратно. | Ветви могут замкнуться в кольцо. |
| Применение | Файловые системы, DOM браузера. | Пайплайны, компиляторы, ML. | Конечные автоматы, сети дорог. |
| Риски | Простой обход. | Сложность зависимостей. | Бесконечные циклы (зависание). |
Заключение
DAG — это фундаментальный паттерн проектирования распределенных систем. Он решает главную задачу инженера данных: как превратить хаос разрозненных скриптов в надежный конвейер, который устойчив к сбоям.
Когда вы пишете task1 >> task2 в Airflow или делаете df.filter() в Spark, вы не просто пишете код. Вы конструируете граф, который гарантирует, что данные пройдут свой путь от начала до конца именно так, как вы задумали — без петель, тупиков и потери времени.
Референсные ссылки
- [Apache Airflow Documentation: Core Concepts] (https://airflow.apache.org/docs/apache-airflow/stable/core-concepts/dags.html)
- [Databricks Glossary: DAG in Spark] (https://www.databricks.com/glossary/dag)
- [Introduction to Algorithms (Cormen et al.) — Graph Algorithms Section] (https://mitpress.mit.edu/9780262046305/introduction-to-algorithms/)