 320
320 
Содержание
- Что такое облачное хранилище?
- Архитектура облачного хранилища - Три кита хранения данных
- Объектное хранилище (Object Storage)
- Блочное хранилище (Block Storage)
- Файловое хранилище (File Storage)
- Принцип работы и надежность
- Сценарии использования в Big Data и ML
- Практика: Взаимодействие через код
- Озера данных (Data Lakes) на базе облаков
- Управление затратами - уровни хранения
- Заключение
- Референсные ссылки
Облачное хранилище (Cloud Storage) — это сервис хранения данных, при котором файлы и объекты размещаются в распределённой инфраструктуре удалённых дата-центров и доступны через сеть по стандартным протоколам с возможностью масштабирования, отказоустойчивости и оплаты по факту использования. Данные физически размещаются на множестве удаленных серверов. Эта аппаратная инфраструктура полностью принадлежит облачному провайдеру. Провайдер берет на себя все заботы по обслуживанию железа. Он обеспечивает доступность, резервирование и физическую безопасность дисков. Пользователь взаимодействует с хранилищем через специальный программный интерфейс. Обычно это API или удобная веб-панель управления. Таким образом, сложная инженерная задача превращается в простую услугу.
Что такое облачное хранилище?
Современные корпоративные системы генерируют колоссальные объемы информации ежедневно. Традиционные жесткие диски на локальных серверах быстро переполняются. Покупка нового оборудования требует значительного времени и больших бюджетов. Облачное хранилище решает эту проблему максимально элегантно. Оно предлагает пользователям практически бесконечное дисковое пространство. Вы платите только за реально занятый объем данных. Это называется популярной концепцией оплаты-по-мере-использования (Pay as you Go).
Кроме того, облако обеспечивает мгновенный глобальный доступ. Ваши модели машинного обучения могут обучаться в любом регионе планеты. Инженеры данных легко обмениваются огромными датасетами через сеть. Таким образом, облачное хранилище становится надежным фундаментом инфраструктуры. Без него абсолютно невозможно представить современный Big Data проект. Оно полностью снимает аппаратные ограничения с программистов. Разработчики фокусируются на алгоритмах, а не на закупке железа.
Практическая архитектура данных
Код курса
PRAR
Ближайшая дата курса
20 апреля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Архитектура облачного хранилища — Три кита хранения данных
Разные аналитические задачи требуют совершенно разных подходов к хранению. Крупные провайдеры предлагают три основные системные архитектуры. Каждая из них имеет свои уникальные технические особенности. Мы детально рассмотрим их принципы работы. Это поможет вам сделать правильный архитектурный выбор.
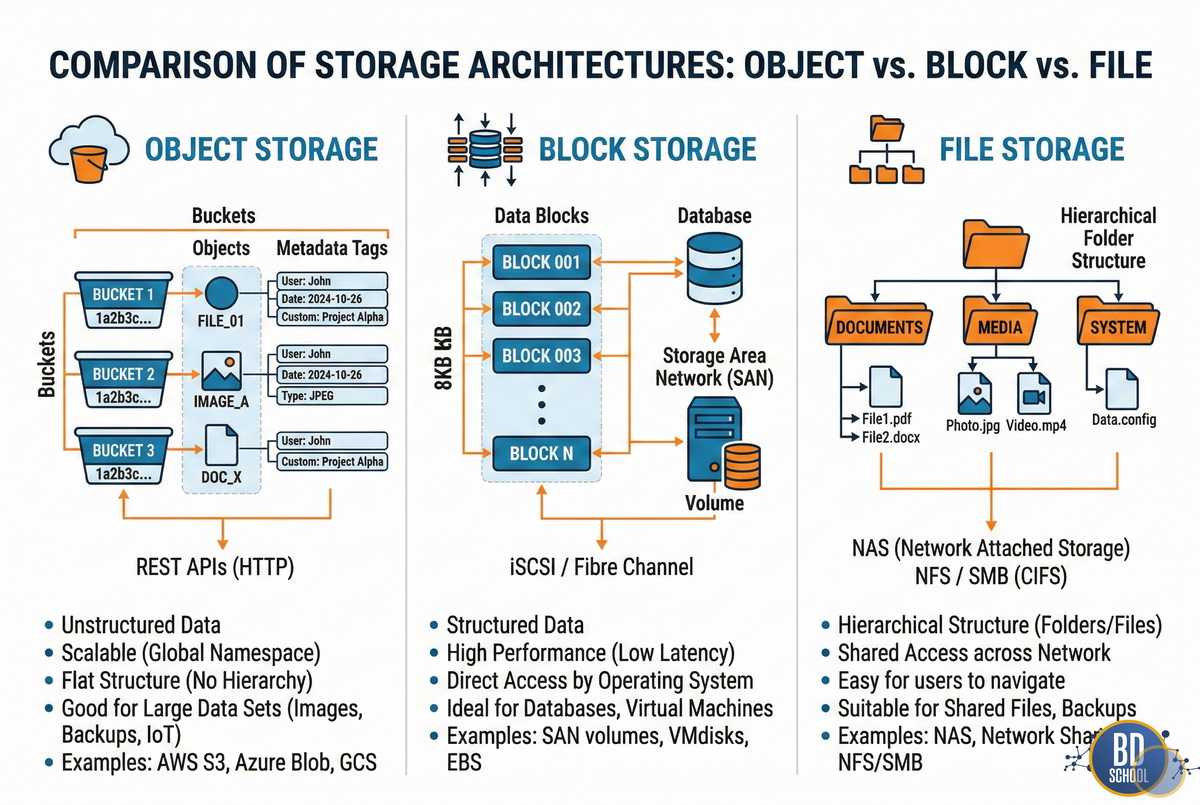
Объектное хранилище (Object Storage)
Это абсолютный индустриальный стандарт для сферы Big Data. Данные здесь сохраняются в виде независимых объектов. Каждый объект содержит сами данные, метаданные и уникальный идентификатор. Здесь полностью отсутствует привычная иерархия вложенных папок. Все объекты лежат в едином плоском адресном пространстве. Обычно это виртуальное пространство называют термином «бакет» или корзиной.
Такая плоская архитектура позволяет масштабировать систему бесконечно. Поиск нужного файла происходит мгновенно по его идентификатору. Самый известный пример — это сервис Amazon S3. Этот протокол давно стал универсальным стандартом индустрии. Большинство других провайдеров полностью поддерживают S3 API. Объектное хранилище идеально подходит для неструктурированных сырых данных. К ним относятся текстовые логи, картинки, видео и бэкапы.
Однако, этот тип совершенно не подходит для частых точечных изменений. Если нужно изменить один байт, придется перезаписать весь объект целиком. Таким образом, это хранилище оптимизировано для чтения, а не для модификации.
Блочное хранилище (Block Storage)
Эта архитектура работает по совершенно иному принципу. Исходные данные разбиваются на небольшие блоки одинакового размера. Каждый такой блок получает свой уникальный системный адрес. Операционная система виртуальной машины видит эти блоки как обычный жесткий диск. Это обеспечивает максимальную возможную скорость работы ввода-вывода. Сетевые задержки при таком подходе остаются минимальными.
Блочное хранилище жизненно необходимо для транзакционных баз данных. Оно активно используется для системных дисков виртуальных машин. Если вам нужна быстрая реляционная база данных, выбирайте этот тип. Классическим примером служит сервис Amazon EBS. Вы можете изменять отдельные блоки без перезаписи всего большого файла. Это главное архитектурное отличие от объектного подхода.
Файловое хранилище (File Storage)
Это самый привычный и понятный формат для обычного пользователя. Данные организованы в виде строгой древовидной иерархии. Система содержит привычные папки, подпапки и файлы. Вы используете такую же структуру на своем личном компьютере. В облачной среде это работает точно так же.
Главный плюс архитектуры — это простой совместный доступ. Несколько серверов могут одновременно читать и писать нужные файлы. Это очень удобно для миграции старых монолитных приложений. Они ожидают увидеть стандартную файловую систему операционной системы. Популярным примером является сервис Amazon EFS. Однако, файловое хранилище очень сложно масштабировать до уровня петабайтов. Оно сильно уступает объектному хранилищу в масштабных задачах Big Data.
Принцип работы и надежность
Главный страх новичка — это внезапная потеря данных в облаке. Однако современные провайдеры используют невероятно сложные алгоритмы защиты информации. Основа надежности любой облачной системы кроется в избыточности. Ваша корпоративная информация никогда не хранится в одном единственном экземпляре.
При загрузке файла происходит скрытая системная магия. Сервис автоматически копирует его на несколько разных физических серверов. Часто эти серверы находятся в независимых изолированных дата-центрах. Если один сервер внезапно сгорит, данные останутся доступны. Система маршрутизации просто переключит запрос на живую рабочую копию.
Ниже представлены основные механизмы обеспечения надежности в облачной архитектуре.
- Синхронная репликация. Создание полных зеркальных копий данных на соседних узлах кластера.
- Кодирование стиранием. Файлы разбиваются на части с добавлением сложных математических битов четности.
- Гео-распределение. Асинхронное сохранение запасных копий в совершенно других географических регионах.
- Контрольные суммы. Постоянная фоновая проверка криптографической целостности файлов на физических дисках. Эти сложные технологии позволяют провайдерам гарантировать потрясающую сохранность.
Обычно маркетинговые материалы заявляют доступность на уровне «одиннадцати девяток». Это означает фантастическую надежность в 99.999999999 процентов. Риск потери файла математически стремится к абсолютному нулю. Вы гораздо быстрее забудете пароль, чем сервис потеряет сам файл. Таким образом, публичное облако объективно надежнее любого локального сервера.
Сценарии использования в Big Data и ML
Облачное хранилище решает огромное множество практических бизнес-задач. Оно является настоящим сердцем любого современного пайплайна данных. Data Science команды используют этот инструмент в своей работе ежедневно. Мы подробно разберем самые ключевые сценарии применения технологии.
Вот базовые варианты использования объектных хранилищ в аналитике и машинном обучении.
- Хранение огромных датасетов. Размещение петабайтов текстов или миллионов изображений для обучения глубоких нейросетей.
- Централизованный сбор логов. Накопление сырых данных о событиях из тысяч различных микросервисов компании.
- Сохранение чекпоинтов. Регулярная запись промежуточных весов моделей машинного обучения во время долгих тренировок.
- Асинхронный обмен данными. Передача финальных результатов обработки от инженеров к продуктовым аналитикам. Все эти сложные процессы требуют невероятной гибкости и моментальной масштабируемости.
Кроме того, хранилище часто служит недорогим промежуточным буфером. Внешние данные сначала попадают туда в совершенно сыром виде. Затем вычислительные Spark-кластеры забирают их для очистки и трансформации. После завершения расчетов результаты снова сохраняются в облачный бакет. Это классический и очень эффективный паттерн проектирования архитектуры данных.
Практическое применение Big Data аналитики для решения бизнес-задач
Код курса
PRUS
Ближайшая дата курса
20 апреля, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Практика: Взаимодействие через код
Голая теория безусловно важна, но инженерная практика всегда интереснее. Программисты крайне редко используют визуальный веб-интерфейс для повседневной работы. Обычно все рутинные операции строго автоматизируются через скрипты. Для этого применяются специальные официальные библиотеки разработчика. В мире языка Python абсолютным стандартом является пакет boto3. Это мощный SDK для работы с сервисами компании AWS. Оно также отлично работает с любым другим S3-совместимым хранилищем.
Давайте детально посмотрим на простой скрипт программного взаимодействия. Мы напишем функцию для загрузки локального файла в облачную корзину.
import boto3
from botocore.exceptions import ClientError
# Инициализация S3 клиента с учетными данными
s3_client = boto3.client(
's3',
aws_access_key_id='YOUR_ACCESS_KEY',
aws_secret_access_key='YOUR_SECRET_KEY',
region_name='us-east-1'
)
def upload_dataset(file_name, bucket, object_name=None):
# Если имя объекта не указано, используем имя файла
if object_name is None:
object_name = file_name
try:
# Непосредственная загрузка файла в указанный бакет
s3_client.upload_file(file_name, bucket, object_name)
print(f"Файл {file_name} успешно загружен в облако.")
except ClientError as error:
print(f"Произошла критическая ошибка загрузки: {error}")
return False
return True
# Запуск функции для тестового датасета
upload_dataset('neural_network_train_data.csv', 'my-ml-datasets')
Этот весьма компактный код выполняет очень сложную сетевую операцию. Он устанавливает зашифрованное HTTPS-соединение с удаленным сервером провайдера. Затем он аккуратно передает байты файла по частям через интернет. В самом конце он проверяет успешность операции и возвращает статус. Таким образом, глубокая интеграция облака в ваш проект занимает минуты.
Озера данных (Data Lakes) на базе облаков
Еще десять лет назад миром Big Data безраздельно правил фреймворк Hadoop. Инженеры строили огромные дорогие кластеры из обычных физических серверов. Они использовали специальную распределенную файловую систему под названием HDFS. Это было невероятно дорого и очень сложно в технической поддержке. Проблема заключалась в том, что хранение и вычисления находились вместе.
Появление недорогого облачного хранилища совершило настоящую архитектурную революцию. Оно позволило навсегда разделить процесс хранения данных и их непосредственную обработку. Теперь вы можете хранить петабайты сырой информации очень дешево. А для сложной обработки запускать временные мощные вычислительные кластеры. Вы платите за процессоры серверов только во время активных расчетов. Это называется современной концепцией Озера данных.
Ниже перечислены главные неоспоримые преимущества современных облачных Озер данных.
- Полностью независимое масштабирование. Объем доступных дисков и мощность кластерных процессоров увеличиваются отдельно друг от друга.
- Единый корпоративный источник истины. Все сырые и чистовые обработанные данные лежат в одном центральном хранилище.
- Поддержка абсолютно любых форматов. Вы можете легко сохранять структурированные таблицы и сырые бинарные файлы.
- Прямая интеграция с аналитикой. Инструменты могут выполнять SQL-запросы прямо поверх объектов в корзине. Эта элегантная распределенная архитектура стала новым золотым стандартом IT-индустрии.
Современные инструменты вроде Apache Spark превосходно работают с облаком. Они читают множество мелких объектов параллельно, обеспечивая колоссальную пропускную способность. Однако, для достижения максимальной скорости файлы нужно правильно форматировать. Обычно опытные инженеры используют специализированные колоночные форматы вроде Apache Parquet. Это значительно ускоряет все тяжелые аналитические агрегации и фильтрации.
Управление затратами — уровни хранения
Корпоративный бюджет любого проекта никогда не бывает резиновым. Долговременное хранение петабайтов информации стоит весьма реальных и больших денег. Провайдеры прекрасно понимают эту проблему и предлагают разные классы доступа. Они называются тирами и различаются по цене хранения и скорости отдачи. Грамотное управление этими тирами экономит бизнесу огромные суммы денег ежемесячно.
Вам нужно обязательно классифицировать свои рабочие данные по частоте использования. Горячие актуальные данные нужны системам и людям постоянно каждый день. Холодные исторические данные могут лежать годами абсолютно без движения. Автоматическое перемещение файлов между этими тирами называется управлением жизненным циклом.
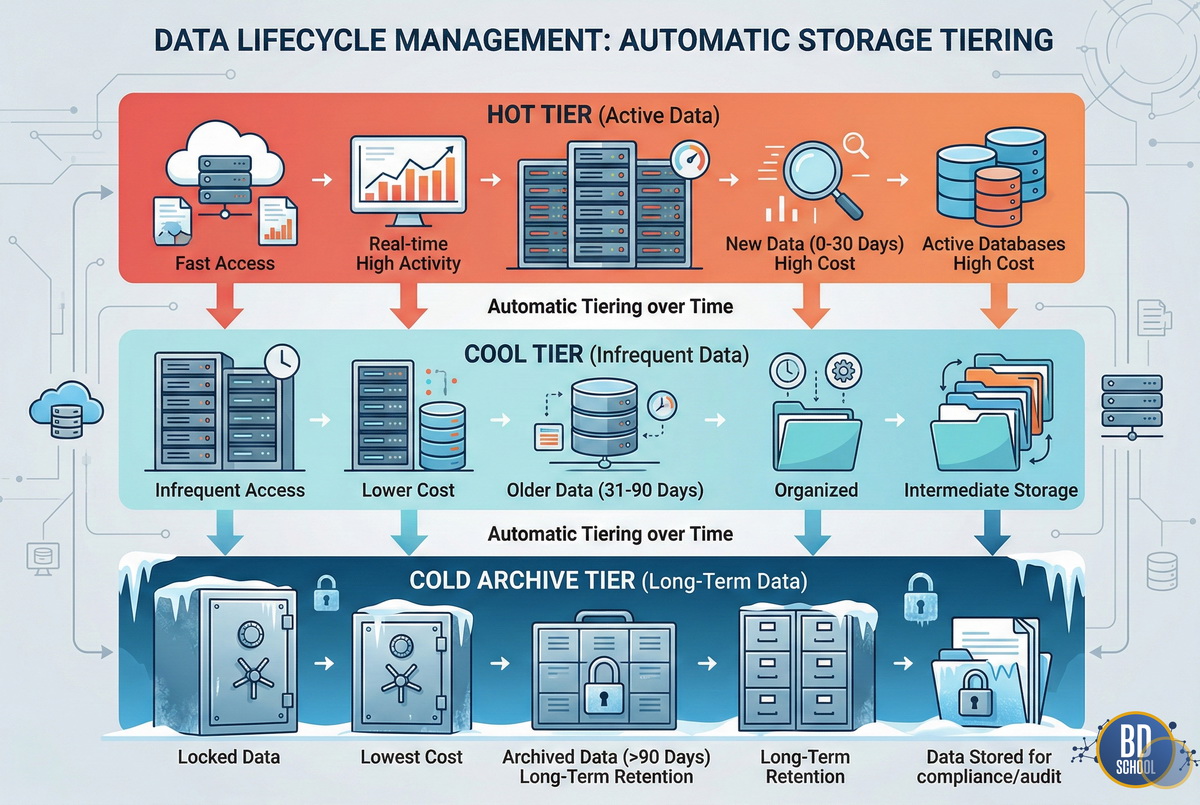
Рассмотрим стандартные популярные классы тарификации хранения облачных данных.
- Горячий тир (Hot). Высокая цена за гигабайт, но полностью бесплатное и мгновенное чтение файлов.
- Прохладный тир (Cool). Сниженная цена хранения, но за каждое чтение или изменение берется комиссия.
- Холодный архивный тир (Archive). Самое дешевое место, но восстановление информации может занимать несколько часов.
- Интеллектуальный тир (Intelligent). Система сама динамически перемещает файлы между классами с помощью алгоритмов. Выбор правильного финансового класса критически важен для рентабельности аналитического отдела.
Например, старые сырые логи веб-сервера логично сразу переносить в архив. Они нужны бизнесу исключительно для редкого аудита безопасности. А вот свежие витрины данных обязательно должны лежать в горячем тире. Аналитики обращаются к ним сотни раз за один рабочий день. Крупные компании всегда настраивают строгие автоматические правила перемещения объектов. Таким образом, постоянная оптимизация огромных затрат происходит без ручного участия человека.
Практическое применение Big Data аналитики для решения бизнес-задач
Код курса
PRUS
Ближайшая дата курса
20 апреля, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Заключение
Облачное хранилище — это далеко не просто большая виртуальная флешка в интернете. Это невероятно мощный, легко масштабируемый и потрясающе отказоустойчивый фундамент. Он позволяет бизнесу строить самые сложные системы аналитики и машинного обучения. Объектный плоский подход навсегда изменил классическую архитектуру проектов Big Data. Грамотное разделение хранения файлов и серверных вычислений дало инженерам абсолютную свободу. Внимательно выбирайте правильный тип хранилища под конкретную задачу. Обязательно следите за бюджетом компании и смело автоматизируйте рутину через код.
Референсные ссылки
- [Документация Amazon S3] (https://docs.aws.amazon.com/s3/)
- [Обзор Google Cloud Storage] (https://cloud.google.com/storage/docs/introduction)
- [Официальное руководство Boto3] (https://boto3.amazonaws.com/v1/documentation/api/latest/guide/s3-examples.html)