 287
287 
Содержание
- Фундаментальная архитектура облачных вычислений (SPI Model)
- Технологический базис: Как это работает "под капотом"
- Практический кейс: Обработка Big Data в облаке
- Шаг 1: Подготовка инфраструктуры (Terraform) облачных вычислений
- Шаг 2: Загрузка данных (Object Storage)
- Шаг 3: Spark-приложение (Scala)
- Модель разделенной ответственности (Shared Responsibility Model)
- Экономика облака (FinOps) облачных вычислений
- Заключение
- Референсные ссылки
Облачные вычисления (Cloud Computing) — это модель предоставления вычислительных ресурсов (вычисления, хранение, сети и платформенные сервисы) по требованию через сеть с эластичным масштабированием, оплатой по факту использования и абстрагированием физической инфраструктуры от пользователя.
Простыми словами, это переход от владения собственным «железом» к его аренде как коммунальной услуги. Вы не покупаете электростанцию, чтобы включить свет дома. Точно так же вы не должны покупать серверную стойку, чтобы запустить код. Для Big Data инженера это означает смену парадигмы: инфраструктура превращается из физического актива (Capital Expenses) в операционные расходы (Operating Expenses), управляемые через код.
Фундаментальная архитектура облачных вычислений (SPI Model)
Облако — это слоеный пирог, где каждый уровень абстрагирует определенную часть сложности управления IT-системами. Понимание модели SPI (SaaS, PaaS, IaaS) критически важно для выбора правильного инструмента под задачу. Рассмотрим три основных уровня сервиса для облачных вычислений:
IaaS (Infrastructure as a Service).
Это фундамент. Провайдер дает вам «голое железо» в виртуальном виде: процессоры, память, диски и сети. Вы получаете ключи от виртуального сервера и делаете с ним что хотите. Вы сами устанавливаете ОС, настраиваете базы данных и патчите дыры в безопасности.
- Примеры: Yandex Compute Cloud, Amazon EC2, Google Compute Engine.
- Для кого: Для DevOps-инженеров, которым нужен полный контроль над конфигурацией ядра Linux или сетевыми протоколами.
PaaS (Platform as a Service).
Золотая середина для разработчиков и дата-инженеров. Провайдер берет на себя управление «железом» и операционной системой. Вам предоставляется готовая среда для запуска кода или базы данных. Вы не думаете об обновлениях Ubuntu или настройке репликации PostgreSQL на низком уровне.
- Примеры: Yandex Data Proc (Managed Spark/Hadoop), Google BigQuery, AWS Lambda.
- Для кого: Для нас. Мы пишем Spark-джобы, а не настраиваем кластеры вручную.
SaaS (Software as a Service).
Вершина пирамиды. Это готовый программный продукт, работающий в браузере. Вы просто пользователь, который потребляет функционал. Настройки бэкенда полностью скрыты.
- Примеры: Gmail, Tableau, Snowflake (в режиме Data Warehousing), Google Colab.
- Для кого: Для бизнес-аналитиков и конечных пользователей.
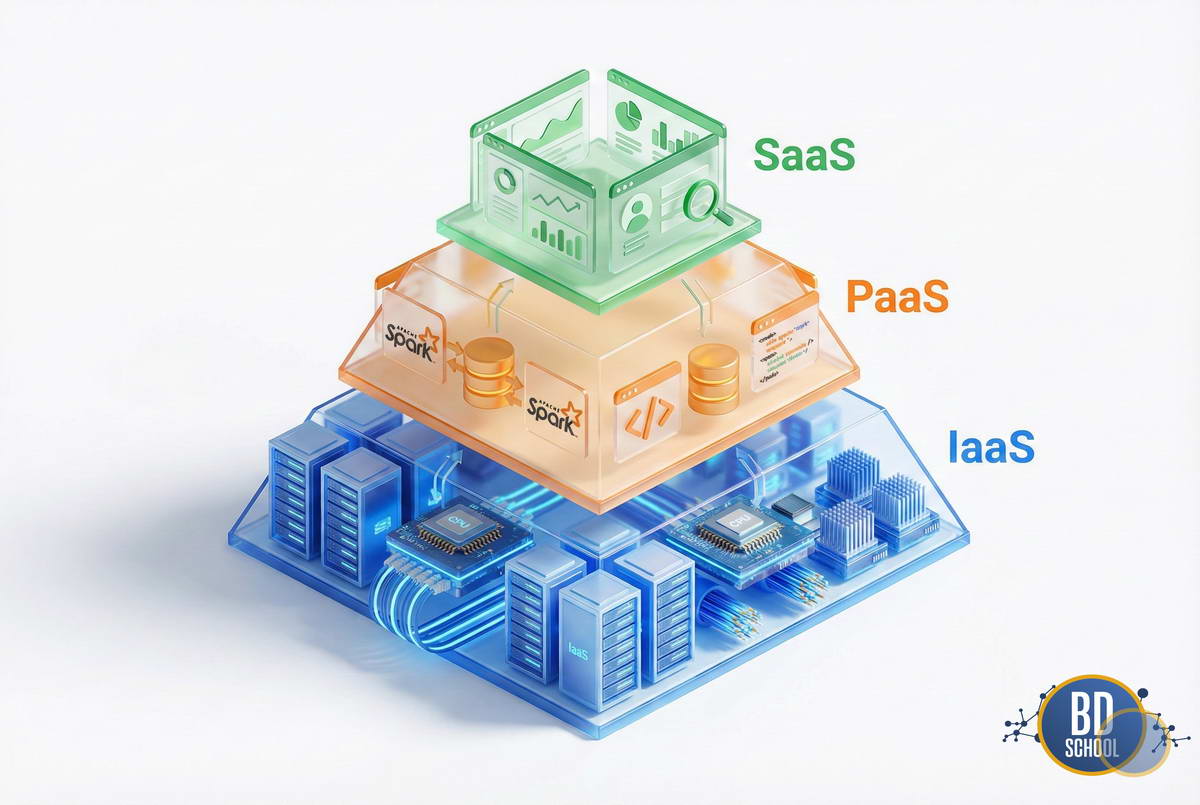
Выбор между этими моделями — это всегда компромисс между контролем (IaaS) и удобством (SaaS). Большинство Big Data пайплайнов сегодня строятся на уровне PaaS.
Технологический базис: Как это работает «под капотом»
Магия облака держится на технологиях виртуализации. Физический сервер в дата-центре (Host) с помощью специального ПО — гипервизора — «нарезается» на множество изолированных виртуальных машин (Guests).
Ключевые механизмы, обеспечивающие работу облака:
Абстракция ресурсов.
Пользователь не видит физический CPU. Он видит vCPU (виртуальное ядро). Гипервизор динамически распределяет такты реального процессора между сотнями виртуальных машин. Это позволяет утилизировать оборудование на 90-95%, тогда как в традиционных серверных простой достигал 80%.
Эластичность (Elasticity).
Это способность системы автоматически расширяться или сжиматься в зависимости от нагрузки. Если ваш скрипт ночью обрабатывает 1 ТБ данных, облако выделит 50 серверов. Утром, когда задача выполнена, эти серверы исчезнут, и вы перестанете за них платить.
API-First подход.
В облаке «железо» управляется программно. Любое действие — создание диска, запуск сети, перезагрузка сервера — это HTTP-запрос к API провайдера. Именно это позволяет нам использовать подход Infrastructure as Code (IaC).
Благодаря этим технологиям мы получаем иллюзию бесконечных ресурсов, доступных по щелчку пальцев (или по строчке кода).
Анализ данных с помощью современного Apache Spark
Код курса
SPARK
Ближайшая дата курса
6 апреля, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Практический кейс: Обработка Big Data в облаке
Перейдем от теории к реальной задаче Data Engineering. Нам нужно не просто «потыкать кнопки» в консоли, а создать воспроизводимую инфраструктуру.
Дано:
- Файл stocks_big.csv (1.3 ГБ) с историей торгов.
- Задача: Найти максимальный объем торгов для каждого тикера.
- Инструменты: Yandex Cloud, Terraform, Apache Spark.
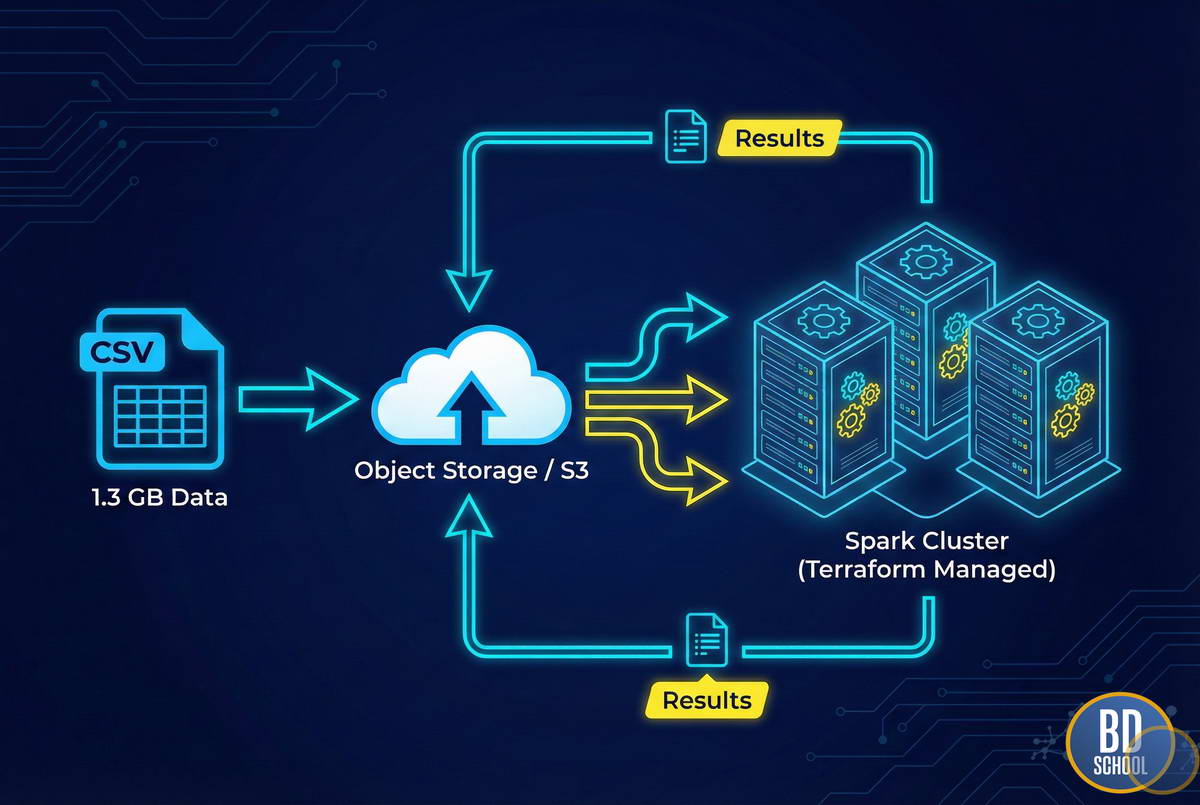
Мы будем использовать подход Infrastructure as Code (IaC). Мы опишем нашу инфраструктуру в текстовых файлах. Это позволит нам развернуть кластер одной командой и так же легко его уничтожить, чтобы не платить лишнее.
Шаг 1: Подготовка инфраструктуры (Terraform) облачных вычислений
Для начала опишем ресурсы. Нам понадобятся: сеть, сервисный аккаунт (права доступа) и сам кластер Yandex Data Proc (аналог Hadoop/Spark кластера).
Создадим файл main.tf. В нем мы декларативно описываем, что мы хотим получить:
# 1. Настраиваем провайдера (Yandex Cloud)
terraform {
required_providers {
yandex = {
source = "yandex-cloud/yandex"
}
}
}
provider "yandex" {
token = "ВАШ_OAUTH_ТОКЕН"
cloud_id = "ВАШ_CLOUD_ID"
folder_id = "ВАШ_FOLDER_ID"
zone = "ru-central1-a"
}
# 2. Создаем сеть и подсеть для кластера
resource "yandex_vpc_network" "data_net" {
name = "spark-network"
}
resource "yandex_vpc_subnet" "data_subnet" {
name = "spark-subnet-a"
zone = "ru-central1-a"
network_id = yandex_vpc_network.data_net.id
v4_cidr_blocks = ["10.0.0.0/24"]
}
# 3. Сервисный аккаунт для управления кластером
resource "yandex_iam_service_account" "dataproc_sa" {
name = "spark-sa"
description = "Service account for Spark cluster"
}
# Выдаем права (роли) аккаунту: mdb.dataproc.agent нужен для работы кластера
resource "yandex_resourcemanager_folder_iam_member" "dataproc_agent" {
folder_id = "ВАШ_FOLDER_ID"
role = "mdb.dataproc.agent"
member = "serviceAccount:${yandex_iam_service_account.dataproc_sa.id}"
}
# Роль для чтения/записи в Object Storage (S3)
resource "yandex_resourcemanager_folder_iam_member" "bucket_editor" {
folder_id = "ВАШ_FOLDER_ID"
role = "storage.editor"
member = "serviceAccount:${yandex_iam_service_account.dataproc_sa.id}"
}
# 4. Бакет для входных данных и результатов
resource "yandex_storage_bucket" "data_bucket" {
access_key = "ВАШ_STATIC_KEY" # Лучше использовать переменные окружения
secret_key = "ВАШ_SECRET_KEY"
bucket = "bigdata-stocks-13gb"
}
# 5. Описание самого кластера Spark (Data Proc)
resource "yandex_dataproc_cluster" "spark_cluster" {
name = "spark-prod-cluster"
description = "Cluster for processing stocks data"
service_account_id = yandex_iam_service_account.dataproc_sa.id
zone_id = "ru-central1-a"
cluster_config {
version_id = "2.0" # Версия образа с Spark и Hadoop
hadoop {
services = ["HDFS", "YARN", "SPARK"]
# Добавляем SSH ключ для доступа к мастер-ноде (если нужно)
ssh_public_keys = [file("~/.ssh/id_rsa.pub")]
}
subclusters {
role = "MASTERNODE"
resource_preset_id = "s2.small" # 2 vCPU, 8 RAM
disk_type_id = "network-ssd"
disk_size = 40
subnet_id = yandex_vpc_subnet.data_subnet.id
hosts_count = 1
}
subclusters {
role = "DATANODE"
resource_preset_id = "s2.medium" # 4 vCPU, 16 RAM - помощнее для воркеров
disk_type_id = "network-ssd"
disk_size = 128
subnet_id = yandex_vpc_subnet.data_subnet.id
hosts_count = 2 # Два воркера для параллелизма
}
}
depends_on = [
yandex_resourcemanager_folder_iam_member.dataproc_agent
]
}
Чтобы запустить эту магию, в терминале нужно выполнить всего три команды. Terraform сам построит граф зависимостей и создаст ресурсы в правильном порядке.
# Инициализация (скачивание плагинов) terraform init # Просмотр плана (что будет создано) terraform plan # Применение конфигурации (создание ресурсов в облаке) terraform apply
После завершения команды apply (это займет 5-7 минут), у нас будет готовый Spark-кластер и пустой бакет.
Шаг 2: Загрузка данных (Object Storage)
Мы не храним данные на серверах (HDFS), так как они удалятся вместе с кластером. Мы используем Object Storage (S3-совместимое хранилище). Это дешево и надежно.
Загрузим наш датасет stocks_big.csv в созданный бакет с помощью утилиты AWS CLI (она работает и с Yandex Object Storage) или через веб-интерфейс.
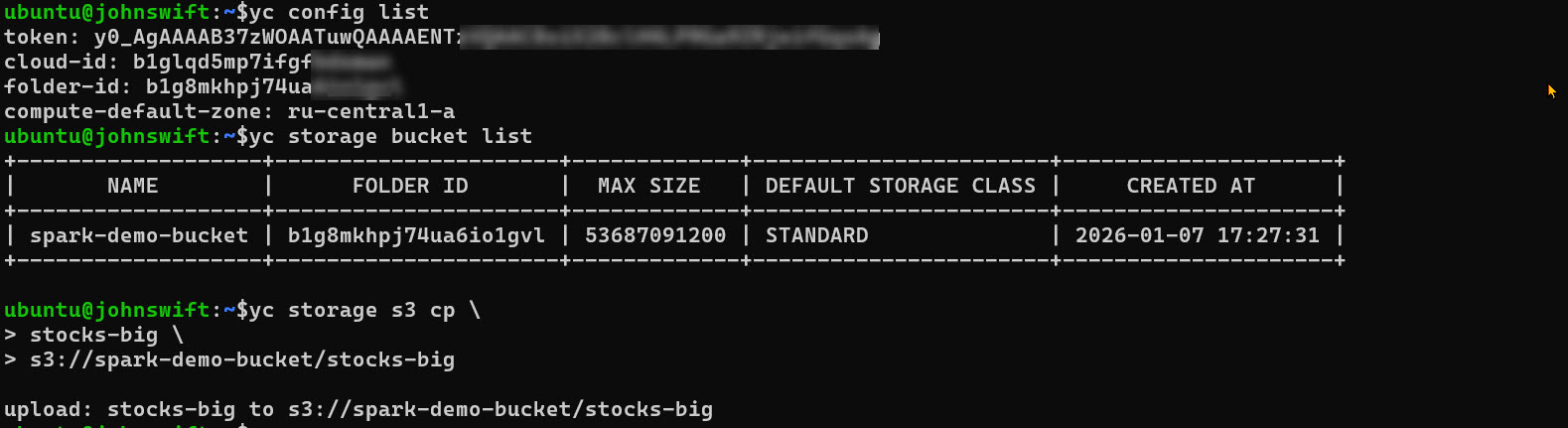
Теперь наш файл объемом 1.3 ГБ лежит в облаке и доступен для Spark по протоколу s3a://.
Шаг 3: Spark-приложение (Scala)
Теперь адаптируем твой код. Главное отличие от локального запуска — мы читаем данные не с диска (file://), а из объектного хранилища (s3a://). Также оформим код в виде полноценного объекта для компиляции в JAR-файл.
Создадим файл StocksAnalysis.scala:
import org.apache.spark.{SparkConf, SparkContext}
object StocksAnalysis {
def main(args: Array[String]): Unit = {
// 1. Инициализация контекста
// В кластере master url обычно управляется через spark-submit, поэтому setMaster не обязателен
val conf = new SparkConf().setAppName("StocksMaxVolume")
val sc = new SparkContext(conf)
// Путь к бакету (лучше передавать аргументом, но для примера хардкодим)
// Обрати внимание: s3a - это коннектор Hadoop к S3
val inputPath = "s3a://spark-demo-bucket/stocks-big"
val outputPath = "s3a://spark-demo-bucket/results/max_vol_output"
// 2. Читаем файл из S3 (ленивая операция)
val stocks = sc.textFile(inputPath)
// 3. Парсим (трансформация)
// Формат CSV: date,symbol,open,close,low,high,volume
val splits = stocks.map(record => record.split(","))
// 4. Выделяем Тикер (index 1) и Объем (index 6 - проверь структуру своего CSV!)
// В примере было 7, но стандартно объем часто идет раньше. Допустим, объем это 7-й элемент.
// Добавляем обработку ошибок парсинга (try/catch или filter) для продакшена
val symvol = splits.map(arr => (arr(1), arr(7).toInt))
// 5. Агрегируем (reduceByKey - это wide transformation, вызывает shuffle)
val maxvol = symvol.reduceByKey((vol1, vol2) => Math.max(vol1, vol2))
// 6. Сохраняем результат обратно в S3, а не выводим в консоль
// Вывод в консоль на кластере уйдет в логи YARN, это неудобно читать.
maxvol.saveAsTextFile(outputPath)
// Останавливаем контекст
sc.stop()
}
}
Для запуска задачи на кластере нам нужно скомпилировать этот код в JAR (например, через sbt) и отправить его в Data Proc.

echo "deb https://repo.scala-sbt.org/scalasbt/debian all main" | sudo tee /etc/apt/sources.list.d/sbt.list echo "deb https://repo.scala-sbt.org/scalasbt/debian /" | sudo tee /etc/apt/sources.list.d/sbt_old.list curl -sL "https://keyserver.ubuntu.com/pks/lookup?op=get&search=0x2EE0EA64E40A89B84B2DF73499E82A75642AC823" | sudo apt-key add sudo apt-get update sudo apt-get install sbt -y # Создаем корневую папку mkdir my-spark-project cd my-spark-project # Создаем структуру для кода (стандарт Scala) mkdir -p src/main/scala

Команда запуска (выполняется на мастер-ноде по SSH или через Job API Яндекса):
spark-submit \ --class StocksAnalysis \ --master yarn \ --deploy-mode cluster \ --num-executors 4 \ --executor-cores 2 \ --executor-memory 4G \ stocks-analysis_2.12-1.0.jar #----- возможен и локальный запуск с данными на s3 бакете spark-submit \ --packages org.apache.hadoop:hadoop-aws:3.3.4 \ --master "local[*]" \ --conf spark.hadoop.fs.s3a.endpoint=https://storage.yandexcloud.net \ --conf spark.hadoop.fs.s3a.access.key=YCAJER2jF********* \ --conf spark.hadoop.fs.s3a.secret.key=YCMvIaqHDylstFX********V \ --conf spark.hadoop.fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem \ --conf spark.hadoop.fs.s3a.path.style.access=true \ /home/ubuntu/spark_s3_demo/my-spark-project/target/scala-2.12/stocksanalysis_2.12-1.0.jar \ "s3a://spark-demo-bucket/stocks-big" \ "s3a://spark-demo-bucket/results/local_run_output"
В результате Spark создаст executors на наших worker-нодах, скачает куски файла stocks_big из S3 параллельно, посчитает максимумы и сложит ответ в папку results в том же бакете.
Модель разделенной ответственности (Shared Responsibility Model)
Работая в облаке, важно понимать: безопасность — это командная игра. Провайдер не может защитить вас от всего. Эта модель четко разграничивает зоны влияния:
Ответственность провайдера (Security OF the Cloud).
Яндекс/AWS отвечают за физическую охрану дата-центров, электричество, работу гипервизора и защиту сети от DDoS-атак на глобальном уровне. Вы можете быть уверены, что никто не украдет жесткий диск с вашими данными физически.
Ответственность клиента (Security IN the Cloud). Все, что происходит внутри виртуальной машины — ваша проблема.
- Кто имеет доступ к бакету с данными? (IAM настройки).
- Шифруются ли данные при передаче?
- Закрыт ли SSH-порт (22) от всего интернета?
- Обновлен ли код вашего приложения?
Если вы оставите S3 бакет публичным и данные утекут — это вина инженера, а не облачного провайдера.
Экономика облака (FinOps) облачных вычислений
Облако может быть как невероятно дешевым, так и разорительным. Новички часто забывают выключить ресурсы, и счетчик «крутится». Два главных совета по экономии (FinOps) для нашего Spark-кейса:
Прерываемые виртуальные машины (Preemptible / Spot Instances).
Облачные провайдеры продают простаивающие мощности с огромной скидкой (до 80%). Нюанс в том, что провайдер может забрать их обратно в любой момент с предупреждением за 30 секунд.
- Для Spark это идеально: Если один воркер пропадет, Spark (YARN) просто перезапустит его задачи на другом узле. Мы ничего не потеряем, кроме пары минут времени, но сэкономим бюджет в разы.
Эфемерные кластеры.
В примере с Terraform мы создали кластер. Хорошей практикой считается уничтожать его сразу после расчета (terraform destroy). Хранить данные в S3 дешево, а держать запущенный кластер Spark «на всякий случай» — дорого.
Разделение вычислений (Compute) и хранения (Storage) — главный экономический рычаг в облаке.
Практическое применение Big Data аналитики для решения бизнес-задач
Код курса
PRUS
Ближайшая дата курса
20 апреля, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Заключение
Облачные вычисления — это стандарт современной Big Data разработки. Мы перестали быть «хранителями серверов» и стали архитекторами систем. Используя инструменты вроде Terraform, мы превращаем инфраструктуру в код, делая её надежной и воспроизводимой.
Ваш следующий шаг — попробуйте запустить пример из статьи. Зарегистрируйте Free Tier аккаунт в любом облаке, настройте Terraform и поднимите свой первый маленький кластер. Ощущение, когда вы создаете дата-центр одной командой в терминале — бесценно.
Референсные ссылки