 796
796 
Содержание
Bloom filter ( Фильтр Блума) — это высокоэффективная вероятностная структура данных. Она позволяет очень быстро проверять, принадлежит ли элемент некоторому множеству. Представьте себе охранника на входе в эксклюзивный клуб. У него нет полного списка имен гостей, а есть только блокнот с отметками. Когда гость приходит, охранник быстро проверяет отметки. Если отметок нет, гостя точно нет в списке. Если отметки есть, гость, вероятно, в списке, но может быть и совпадением.
Главной особенностью Фильтра Блума является его компактность в использовании памяти. Однако эта эффективность достигается ценой небольшой вероятности ошибки. Фильтр Блума может сказать, что элемент «вероятно, в множестве», когда его там нет. Такое событие называют ложноположительным срабатыванием. При этом он никогда не совершает обратную ошибку. Если фильтр говорит, что элемента нет, это гарантированно так. Отсутствие ложноотрицательных срабатываний делает его незаменимым во многих системах, где память и скорость важнее стопроцентной точности на первом этапе проверки.
Архитектура и ключевые характеристики Фильтра Блума
В основе архитектуры Фильтра Блума лежат два простых компонента. Они определяют его работу и характеристики. Понимание этих элементов помогает оценить его сильные стороны и объясняет ограничения.
Первым компонентом является битовый массив. Это последовательность битов, изначально заполненных нулями. Его размер напрямую влияет на точность фильтра. Чем больше массив, тем ниже вероятность ложных срабатываний. Второй компонент — это набор независимых хэш-функций. Эти функции преобразуют входной элемент в несколько числовых значений. Каждое значение указывает на позицию бита в массиве. Качество и независимость этих функций критически важны. Хорошие хэш-функции, такие как из семейства MurmurHash, обеспечивают быстрое вычисление и равномерное распределение битов. Это минимизирует «столкновения», когда разные элементы пытаются установить один и тот же бит. Таким образом, эти два элемента формируют основу для работы Фильтра Блума.
Механизм работы Фильтра Блума — добавление и проверка
Принцип работы bloom filter состоит из двух основных операций. Это добавление элемента и его последующая проверка. Оба процесса используют битовый массив и хэш-функции. Давайте рассмотрим их пошагово.
Процесс добавления нового элемента выглядит следующим образом.
- Хэширование. Сначала элемент, например, строка «hello», пропускается через каждую хэш-функцию. Допустим, у нас 3 функции, которые вернули значения 5, 18 и 42.
- Установка битов. Каждое такое значение используется как индекс в битовом массиве. Биты по этим индексам (5, 18, 42) устанавливаются в единицу. Если какой-то бит уже был равен единице, он таким и остается.
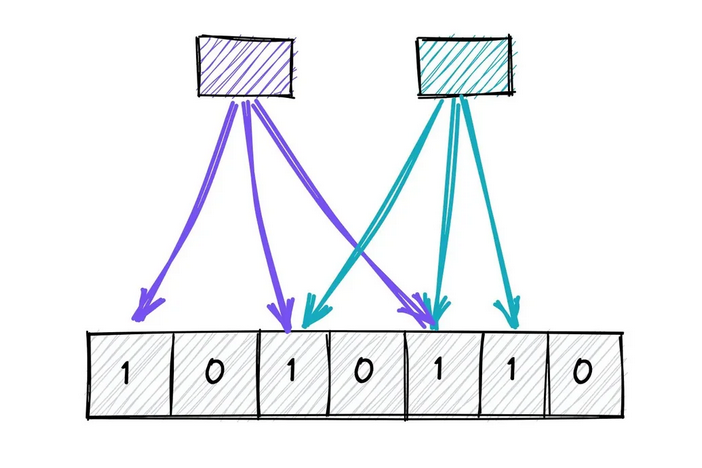
Проверка наличия элемента работает похожим образом, но с логикой чтения.
- Хэширование. Элемент для проверки снова хэшируется всеми теми же функциями.
- Проверка битов. Затем проверяются значения битов по полученным индексам. Если все эти биты равны единице, фильтр сообщает, что элемент, вероятно, находится в множестве. Если хотя бы один бит равен нулю, элемент гарантированно отсутствует. Именно это свойство исключает ложноотрицательные результаты.
Сравнение Фильтра Блума с другими методами фильтрации
Фильтр Блума является лишь одним из инструментов для проверки данных. Важно понимать его место среди других подходов, особенно при работе с текстом.
- Хэш-таблица (Set). Это самый точный способ проверки принадлежности. Хэш-таблица хранит все элементы и дает 100% точный ответ без ложных срабатываний. Однако она требует значительно больше памяти, так как хранит сами элементы, а не их компактное представление. Bloom filter выигрывает, когда объем данных огромен, а оперативная память ограничена.
- Оператор
LIKEи регулярные выражения. Эти инструменты незаменимы для поиска по шаблону или подстроке (например,WHERE url LIKE '%google%'). Они обеспечивают максимальную гибкость. Их недостаток — крайне низкая производительность на больших объемах данных, так как они требуют полного сканирования. Фильтр Блума не может выполнять поиск по подстроке, но молниеносно проверяет наличие полного значения. - Полнотекстовые индексы (FTS). Системы вроде Elasticsearch строят сложные обратные индексы для релевантного поиска по словам в документах. Это мощное, но ресурсоемкое решение. Вариации Фильтра Блума, такие как
tokenbfв ClickHouse, представляют собой легковесную альтернативу. Они не обеспечивают ранжирования, но эффективно отсекают фрагменты данных, где искомых слов точно нет.
Пример реализации Фильтра Блума на Python
Теорию легко понять на практике. Ниже приведен простой пример кода на языке Python, который демонстрирует базовую логику работы Фильтра Блума. Для реализации хэш-функций мы используем библиотеку mmh3, а в качестве битового массива — стандартный array.
Этот код показывает ключевые шаги: инициализацию, добавление элементов и последующую проверку. Вы можете заметить, что проверка для элемента «world», который не был добавлен, возвращает False. А проверка для «goodbye», которого тоже не было, может случайно вернуть True — это и есть ложноположительное срабатывание.
import array
import mmh3
class BloomFilter:
def __init__(self, size, hash_count):
self.size = size
self.hash_count = hash_count
self.bit_array = array.array('b', [0]) * size
def add(self, item):
for i in range(self.hash_count):
# Используем seed для получения 'разных' хэш-функций
index = mmh3.hash(item, i) % self.size
self.bit_array[index] = 1
def check(self, item):
for i in range(self.hash_count):
index = mmh3.hash(item, i) % self.size
if self.bit_array[index] == 0:
return False # Элемента точно нет
return True # Элемент, вероятно, есть
# Параметры: размер массива 100 бит, 3 хэш-функции
bf = BloomFilter(100, 3)
# Добавляем элементы
bf.add("hello")
bf.add("python")
# Проверяем
print(f"Проверка 'hello': {bf.check('hello')}") # Ожидаем True
print(f"Проверка 'world': {bf.check('world')}") # Ожидаем False
# Демонстрация ложного срабатывания (может произойти)
print(f"Проверка 'goodbye': {bf.check('goodbye')}")
Практический пример с ClickHouse и Bloom Filter
Аналитическая СУБД ClickHouse активно использует bloom filter в индексах для пропуска данных. Такой индекс позволяет быстро проверить, может ли искомое значение находиться в определенном блоке данных (грануле). Если фильтр говорит «нет», ClickHouse пропускает этот блок и не читает его с диска. Это значительно ускоряет выполнение запросов. Давайте создадим таблицу и посмотрим, как это работает.
Построение DWH на ClickHouse
Код курса
CLICH
Ближайшая дата курса
16 февраля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Сначала создадим таблицу events с индексом типа bloom_filter для колонки user_id. Параметр 0.01 задает желаемую долю ложноположительных срабатываний.
Теперь наполним таблицу данными. Важно вставить достаточно большое количество разнообразных данных, чтобы ClickHouse создал несколько блоков.
INSERT INTO events SELECT
now() - INTERVAL toInteger(rand() % 100) DAY,
toString(rand()),
'click'
FROM numbers(1000000);
Наконец, выполним запрос на поиск пользователя, которого заведомо нет в данных. Мы воспользуемся EXPLAIN для анализа плана запроса, чтобы увидеть работу индекса.
EXPLAIN indexes=1 SELECT count() FROM events WHERE user_id = 'non_existent_user';
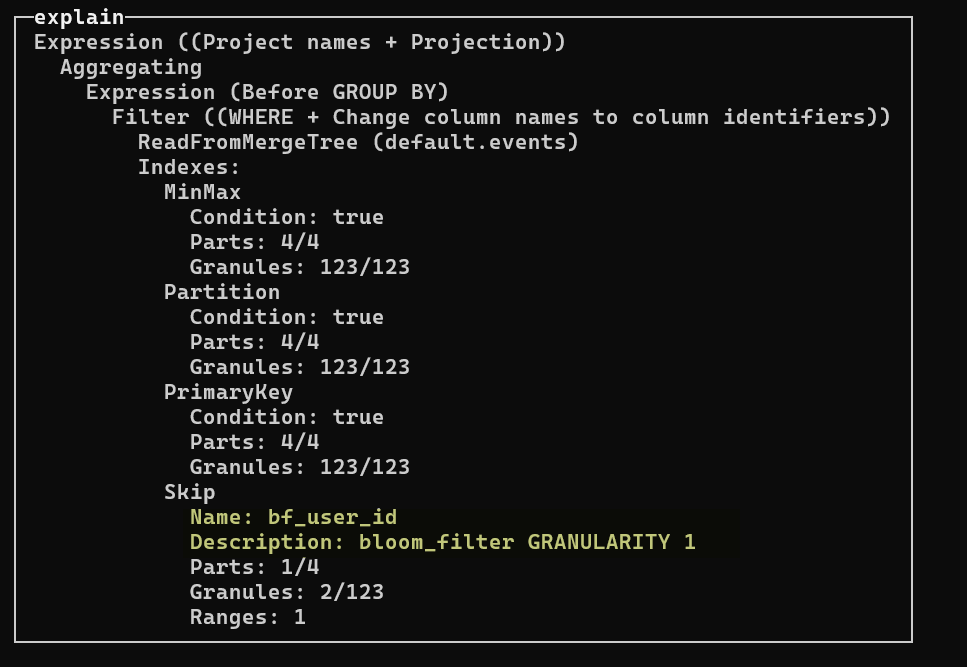
В результате выполнения EXPLAIN вы увидите информацию о задействованных индексах. Ключевым показателем эффективности будет количество прочитанных «гранул» (marks). При использовании индекса bf_user_id оно будет значительно меньше общего числа гранул. Это означает, что ClickHouse с помощью Фильтра Блума смог пропустить большую часть данных, не читая их с диска, что и является целью его применения.
Заключение
Таким образом, Фильтр Блума представляет собой мощный и элегантный инструмент. Он обеспечивает чрезвычайно быстрый и компактный способ предварительной проверки принадлежности к множеству. Его главный компромисс — это контролируемая вероятность ложноположительных срабатываний. Понимание этого компромисса и сравнение с альтернативами позволяет эффективно применять Фильтр Блума в базах данных, сетевых приложениях и системах обработки больших данных, значительно повышая их производительность.
Референсные ссылки
- Как работают индексы пропуска данных в ClickHouse (https://prosto.click/blog/clickhouse-data-skipping-indexes/)
- Bloom Filters by Example (https://llimllib.github.io/bloomfilter-tutorial/)
- Вероятностные структуры данных. Фильтр Блюма (https://habr.com/ru/articles/494692/)