 1048
1048 
Содержание
Apache Hudi (Hadoop Upserts Deletes and Incrementals) — это открытый формат таблиц и платформа для управления данными в озере данных (Data Lake), которая предоставляет возможности потоковой обработки непосредственно поверх пакетных данных. Основная функция Hudi заключается в обеспечении атомарных операций вставки, обновления (upsert) и удаления данных на уровне отдельных записей, что традиционно было сложной задачей в озерах данных на базе HDFS или Amazon S3. Ключевое отличие Apache Hudi от конкурентов, таких как Apache Iceberg и Delta Lake, заключается в его архитектурной гибкости, предлагающей два типа таблиц: Copy on Write (CoW) для оптимизации чтения и Merge on Read (MoR) для оптимизации записи. Это позволяет инженерам выбирать оптимальный компромисс между задержкой ingestion-процессов и производительностью аналитических запросов, делая Hudi особенно мощным инструментом для построения инкрементальных конвейеров данных и сценариев Change Data Capture (CDC).
Архитектура и ключевые концепции Apache Hudi

В основе Apache Hudi лежит несколько фундаментальных концепций, которые обеспечивают его функциональность. Понимание этих концепций критически важно для эффективного использования платформы.
Главным компонентом является Timeline — временная шкала, которая отслеживает все действия, выполненные над таблицей в хронологическом порядке. Каждое действие, такое как коммит, очистка или компактификация, записывается как атомарная операция на временной шкале. Это обеспечивает изоляцию снапшотов и позволяет выполнять запросы к состоянию таблицы на определенный момент времени, что является основой для инкрементальных запросов и откатов.
Файловая структура в Hudi организована в виде групп файлов (File Groups). Каждая группа файлов уникально идентифицируется и содержит несколько срезов файлов (File Slices). Срез файла состоит из базового файла (например, в формате Parquet), который содержит основную версию данных, и набора лог-файлов (в формате Avro), где хранятся обновления для этого базового файла. Эта структура является сердцем типа таблиц Merge on Read.
Для быстрого поиска записей, подлежащих обновлению, Hudi использует механизм индексирования. Индекс сопоставляет ключ записи (primary key) с ее физическим местоположением (ID группы файлов). Hudi поддерживает несколько типов индексов, включая Bloom-индекс и HBase-индекс, что позволяет эффективно выполнять операции upsert даже на петабайтных наборах данных.
Типы таблиц поддерживаемых Apache Hudi: Copy on Write vs Merge on Read
Выбор типа таблицы — это одно из самых важных архитектурных решений при работе с Apache Hudi. Этот выбор напрямую влияет на производительность записи и чтения данных.
Copy on Write (CoW): В таблицах этого типа данные хранятся исключительно в колоночном формате, например, Apache Parquet. При поступлении обновления для существующей записи Hudi не изменяет старый файл, а создает его новую версию, включающую это обновление. Старый файл помечается как устаревший и впоследствии удаляется.
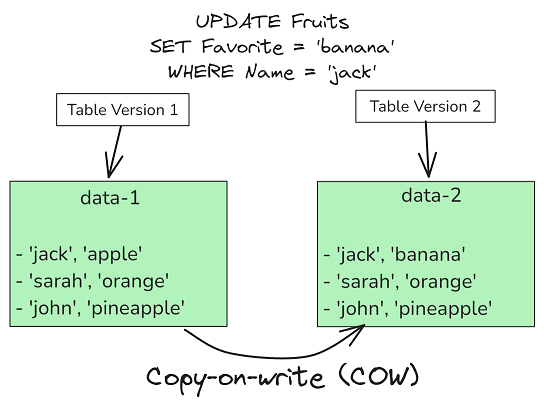
- Преимущества: Высокая производительность чтения, так как нет необходимости объединять базовые и лог-файлы во время запроса. Формат идеально подходит для традиционных аналитических нагрузок.
- Недостатки: Более высокая задержка записи и «усиление» записи (write amplification), поскольку даже небольшое обновление требует копирования всего файла.
Merge on Read (MoR): Этот тип таблиц использует гибридный подход. Данные хранятся в комбинации базовых файлов (Parquet) и дельта-файлов (логов) в строковом формате (Avro). Новые записи и обновления быстро дописываются в лог-файлы. Процесс слияния (merge) логов с базовым файлом происходит либо во время чтения (on-the-fly), либо асинхронно в фоновом режиме (компактификация).
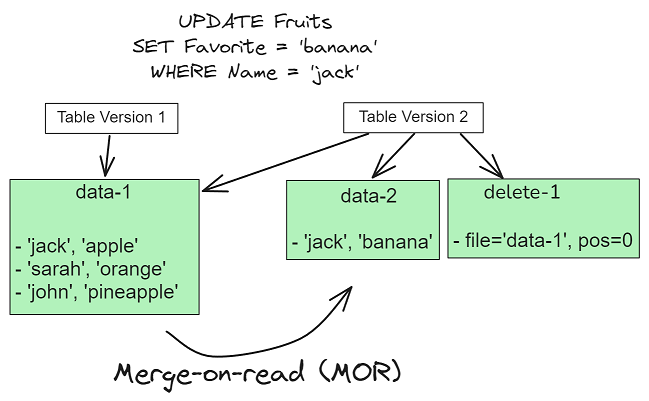
- Преимущества: Очень низкая задержка записи, что идеально подходит для потоковой обработки и сценариев CDC.
- Недостатки: Более низкая производительность чтения, так как движку запросов необходимо на лету объединять данные из нескольких файлов.
Выбор между CoW и MoR зависит от конкретного сценария использования. Для аналитических хранилищ, где данные обновляются редко, а читаются часто, предпочтительнее CoW. Для операционных озер данных, куда непрерывно поступают потоковые данные, лучше подходит MoR.
Потоковая обработка данных из Kafka с помощью Apache Hudi
Один из самых распространенных сценариев использования Apache Hudi — это создание конвейера для поглощения данных из Apache Kafka в реальном времени. Связка Kafka, Apache Spark и Hudi позволяет построить надежную архитектуру для потоковой загрузки данных с поддержкой upsert-операций.
Представим, что у нас есть топик Kafka, в который поступают события об изменении профилей пользователей. Используя Spark Structured Streaming, мы можем читать эти события и записывать их в таблицу Hudi типа Merge on Read, чтобы обеспечить минимальную задержку. Для более глубокого изучения Apache Spark вы можете ознакомиться с нашим курсом «Apache Spark для разработчиков«.
# Пример кода на PySpark для чтения из Kafka и записи в Hudi
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("KafkaToHudi").getOrCreate()
# Читаем поток данных из Kafka
kafka_stream_df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "your_kafka_broker:9092") \
.option("subscribe", "user_profiles_cdc") \
.load()
# Преобразуем данные из формата Kafka (JSON)
from pyspark.sql.functions import from_json, col
from pyspark.sql.types import StructType, StructField, StringType, TimestampType
schema = StructType([
StructField("user_id", StringType(), False),
StructField("email", StringType(), True),
StructField("status", StringType(), True),
StructField("updated_at", TimestampType(), True)
])
parsed_df = kafka_stream_df.select(from_json(col("value").cast("string"), schema).alias("data")).select("data.*")
# Настройки для записи в Hudi
hudi_options = {
'hoodie.table.name': 'user_profiles_mor',
'hoodie.datasource.write.table.type': 'MERGE_ON_READ',
'hoodie.datasource.write.recordkey.field': 'user_id',
'hoodie.datasource.write.precombine.field': 'updated_at',
'hoodie.datasource.write.partitionpath.field': 'status',
'hoodie.datasource.write.operation': 'upsert',
'hoodie.index.type': 'BLOOM'
}
# Запускаем стриминг-запрос для записи в Hudi
def write_to_hudi(batch_df, batch_id):
batch_df.write.format("hudi") \
.options(**hudi_options) \
.mode("append") \
.save("/path/to/lake/user_profiles_mor")
parsed_df.writeStream \
.foreachBatch(write_to_hudi) \
.option("checkpointLocation", "/path/to/checkpoints/user_profiles_mor") \
.start() \
.awaitTermination()
В этом примере мы используем поле user_id как первичный ключ, а updated_at — для определения самой свежей записи при дубликатах (precombine).
Интеграция Apache Hudi с ClickHouse через Iceberg
На текущий момент ClickHouse не имеет нативной поддержки формата Apache Hudi. Однако, это не означает, что нельзя использовать эти мощные инструменты вместе. Распространенным архитектурным паттерном является использование Hudi для ingestion-слоя и потоковой обработки, а затем — экспорт данных в формат Apache Iceberg, который ClickHouse отлично поддерживает.
Этот подход позволяет использовать сильные стороны каждого инструмента: быструю запись и upsert-операции в Hudi (особенно с типом MoR), и сверхбыстрые аналитические запросы в ClickHouse поверх стабильных снапшотов данных в Iceberg.
Процесс конвертации можно реализовать с помощью периодически запускаемого Spark-задания, которое читает данные из таблицы Hudi и записывает их в новую или существующую таблицу Iceberg.
# Пример Spark-задания для конвертации Hudi в Iceberg
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("HudiToIceberg").getOrCreate()
# Читаем данные из таблицы Hudi
hudi_table_path = "/path/to/lake/user_profiles_mor"
hudi_df = spark.read.format("hudi").load(hudi_table_path)
# Записываем данные в таблицу Iceberg
iceberg_table_name = "my_catalog.db.user_profiles_iceberg"
hudi_df.writeTo(iceberg_table_name).createOrReplace()
После выполнения этого задания данные становятся доступными в таблице Iceberg. Далее вы можете использовать ClickHouse для их чтения точно так же, как это было описано в нашей wiki статье про Apache Iceberg.
Заключение
Apache Hudi является мощным и гибким инструментом для построения современных озер данных, особенно в сценариях, требующих инкрементальной обработки и потокового поглощения данных. Его уникальная архитектура с двумя типами таблиц, Copy on Write и Merge on Read, предоставляет инженерам возможность тонкой настройки платформы под конкретные требования к задержке и производительности. Несмотря на отсутствие прямой интеграции с некоторыми аналитическими системами, такими как ClickHouse, гибкость Hudi и его совместимость с экосистемой Apache Spark позволяют строить обходные пути, например, через конвертацию в формат Apache Iceberg, объединяя лучшие черты нескольких технологий. В мире больших данных, где требования постоянно меняются, такие инструменты, как Hudi, играют ключевую роль в создании надежных и масштабируемых платформ.
Использованные референсы и материалы
- Официальная документация Apache Hudi
- Статья «Choosing a Table Type in Apache Hudi: CoW vs MoR» в блоге Onehouse https://www.onehouse.ai/blog/apache-hudi-copy-on-write-vs-merge-on-read
- Статья «Comparing Open Source Data Lake Table Formats — Delta vs. Hudi vs. Iceberg» от lakeFS https://lakefs.io/blog/delta-vs-hudi-vs-iceberg/
- Документация по Hudi Sink для Apache Flink https://flink.apache.org/2023/11/21/announcing-the-apache-flink-community-edition-of-the-fivetran-hudi-sink-connector/