 1367
1367 
Содержание
- Ключевые проблемы традиционных озер данных, которые решает Iceberg
- Архитектура и ключевые компоненты Apache Iceberg
- Apache Iceberg в сравнении с Parquet и ORC
- Основные возможности Apache Iceberg
- Интеграция Айсберг с Apache Kafka
- Интеграция Apache Iceberg с ClickHouse
- Использование Айсберг с Trino
- Заключение
- Использованные референсы и материалы
Apache Iceberg — это открытый формат таблиц для огромных аналитических наборов данных в озерах данных (Data Lake). По своей сути, Apache Iceberg не является ни системой хранения, ни движком для обработки запросов; это спецификация, которая определяет, как организовать файлы данных (например, Parquet, Avro, ORC) и метаданные, чтобы обеспечить функциональность, присущую традиционным базам данных, прямо поверх объектных хранилищ вроде Amazon S3.
Ключевое отличие от старых форматов, таких как Hive, заключается в том, что Iceberg (далее Айсберг) отслеживает отдельные файлы, а не каталоги, что обеспечивает атомарные коммиты, надежную эволюцию схемы и высокую производительность без необходимости в централизованном метасторе, который часто становится узким местом. Это позволяет выполнять ACID-транзакции, путешествовать во времени по состоянию данных (Time Travel) и безопасно изменять схему таблицы без переписывания всех данных.
Ключевые проблемы традиционных озер данных, которые решает Iceberg
Традиционные озера данных, часто построенные на базе Apache Hive, сталкиваются с рядом хронических проблем, превращающих их из ценного ресурса в «болото данных» (Data Swamp). Apache Iceberg был создан для решения именно этих проблем.

Во-первых, это проблема согласованности данных. Операции в Hive не являются атомарными. Если задание записи данных завершается сбоем на полпути, в озере остаются «мусорные» данные, которые сложно отследить и удалить. Айсберг решает эту проблему с помощью атомарных операций фиксации (коммитов) метаданных. Каждое изменение — это создание новой, целостной версии таблицы, что гарантирует, что потребители данных видят либо старое, либо новое состояние, но никогда не промежуточное.
Во-вторых, производительность сканирования метаданных. В Hive для получения списка файлов таблицы необходимо рекурсивно обходить каталоги файловой системы, что становится крайне медленным при наличии миллионов файлов и партиций. Айсберг хранит полный список файлов данных в компактных файлах метаданных (manifest files). Благодаря этому движку запросов не нужно взаимодействовать с файловой системой для планирования, что значительно ускоряет выполнение запросов.
Наконец, это хрупкость и сложность эволюции схемы и партиционирования. Изменение типа столбца или схемы партиционирования в Hive — сложная и рискованная операция, часто требующая переписывания всей таблицы. Apache Iceberg поддерживает безопасную эволюцию схемы (schema evolution) и партиций, позволяя изменять структуру таблицы без изменения существующих данных.
Архитектура и ключевые компоненты Apache Iceberg
Архитектура Apache Iceberg логически разделена на несколько уровней, что обеспечивает его гибкость и расширяемость.
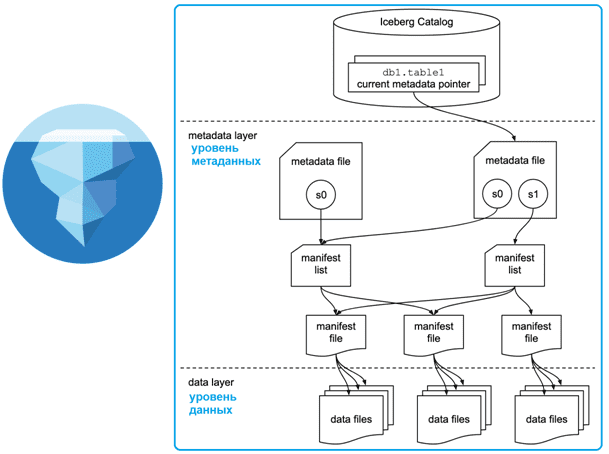
Слой каталога (Iceberg Catalog): Это точка входа для любого движка обработки данных, такого как Trino или Spark. Каталог отвечает за сопоставление имени таблицы с расположением ее текущего файла метаданных. Iceberg поддерживает различные реализации каталогов, включая Hive Metastore, AWS Glue Catalog, JDBC и REST-каталоги, что обеспечивает широкую совместимость.
Слой метаданных (Metadata Layer): Это ядро Apache Iceberg. В отличие от Hive, который полагается на один центральный Metastore, Айсберг использует древовидную структуру метаданных:
- Файл метаданных (Metadata file): Корневой файл, содержащий информацию о схеме таблицы, спецификации партиционирования, снапшотах и расположении текущего списка манифестов.
- Список манифестов (Manifest list): Файл, который содержит указатели на один или несколько файлов манифеста. Каждый снапшот таблицы соответствует одному списку манифестов.
- Файл манифеста (Manifest file): Файл, содержащий список файлов данных (data files), а также статистику по ним (например, минимальные и максимальные значения для столбцов), что используется для оптимизации запросов и отсечения ненужных файлов.
Слой данных (Data Layer): Это фактические файлы с данными, хранящиеся в объектном хранилище. Apache Iceberg поддерживает несколько форматов файлов, включая Apache Parquet, Apache ORC и Apache Avro. Данные организованы в соответствии со структурой, описанной в файлах манифеста.
Apache Iceberg в сравнении с Parquet и ORC
Iceberg не является заменой форматам файлов, таким как Parquet и ORC. Он скорее дополняет их, предоставляя уровень управления таблицами поверх этих форматов. Parquet и ORC — это колоночные форматы хранения данных. Они оптимизированы для аналитических запросов. Они обеспечивают эффективное сжатие данных. Также они поддерживают предикатную фильтрацию на уровне файла.
Однако, Parquet и ORC сами по себе не предоставляют функций, подобных ACID-транзакциям или schema evolution. Эти форматы просто описывают, как данные хранятся внутри файла. Они не управляют коллекцией файлов как единой таблицей. Айсберг , напротив, предоставляет именно эти возможности. Он отслеживает, какие файлы Parquet или ORC принадлежат к таблице. Более того, Айсберг управляет изменениями и версиями этих файлов. Таким образом, Айсберг добавляет табличную семантику к хранилищам данных. Он повышает надежность и управляемость data lakes. Например, он позволяет выполнять атомарные обновления данных. Это невозможно только с использованием Parquet или ORC.
Основные возможности Apache Iceberg
Формат Apache Iceberg (далее Айсберг) предоставляет инженерам данных мощные инструменты для управления жизненным циклом данных.
- ACID-транзакции: Айсберг обеспечивает атомарность, согласованность, изоляцию и долговечность транзакций через атомарную замену указателя на файл метаданных. Это позволяет безопасно выполнять одновременные операции записи и чтения.
- Эволюция схемы (Schema Evolution): Айсберг позволяет добавлять, удалять, переименовывать столбцы и изменять их порядок без переписывания данных. Каждому значению в таблице привязан уникальный ID поля, что гарантирует корректное чтение данных независимо от изменений в схеме.
- Эволюция партиционирования (Partition Evolution): Вы можете изменить логику разбиения таблицы (например, перейти от дневных партиций к часовым) без необходимости переписывать старые данные. Айсберг будет корректно обрабатывать запросы к данным как со старой, так и с новой схемой партиционирования.
- Путешествия во времени (Time Travel): Каждый коммит в Айсберг создает новый снапшот таблицы. Это позволяет выполнять запросы к состоянию таблицы на определенный момент времени или на определенный номер снапшота. Эта функция бесценна для аудита, отладки конвейеров данных и восстановления после сбоев.
- Скрытое партиционирование (Hidden Partitioning): Айсберг может автоматически генерировать значения для партиций на основе значений в столбцах. Например, он может создать партицию 2023-10-25 из столбца с временной меткой timestamp. Это избавляет пользователей от необходимости знать детали физической структуры таблицы при написании запросов. Для знакомства с технологиями обработки больших данных вы можете прийти наш курс «Архитектор больших данных» .
Интеграция Айсберг с Apache Kafka
Построение потоковых конвейеров данных — одна из ключевых задач современной инженерии данных. Связка Apache Kafka и Apache Iceberg позволяет создавать надежные и масштабируемые системы для накопления данных в реальном времени. В этом сценарии Kafka выступает как брокер сообщений, а Айсберг— как надежное хранилище в озере данных.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
18 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Для соединения этих двух систем обычно используется движок потоковой обработки, такой как Apache Flink или Spark Streaming. Apache Flink, благодаря своему мощному SQL-интерфейсу и нативному коннектору для Iceberg, является особенно популярным выбором.
Вот пример, как можно настроить конвейер данных из Kafka в Айсберг с помощью Flink SQL:
-- Шаг 1: Создаем таблицу-источник, которая читает данные из топика Kafka.
-- Сообщения в Kafka предполагаются в формате JSON.
CREATE TABLE kafka_event_stream (
event_id STRING,
event_timestamp_ms BIGINT,
user_id STRING,
event_type STRING,
-- Преобразуем timestamp в удобный для Flink формат
event_time AS TO_TIMESTAMP_LTZ(event_timestamp_ms, 3)
) WITH (
'connector' = 'kafka',
'topic' = 'server-events',
'properties.bootstrap.servers' = 'kafka-broker-1:9092',
'properties.group.id' = 'flink-iceberg-consumer',
'format' = 'json',
'scan.startup.mode' = 'latest-offset'
);
-- Шаг 2: Создаем таблицу-приемник в формате Iceberg.
-- Flink будет автоматически управлять созданием файлов и коммитами метаданных.
CREATE TABLE iceberg_events_sink (
event_id STRING,
event_time TIMESTAMP(3),
user_id STRING,
event_type STRING
) WITH (
'connector' = 'iceberg',
'catalog-name' = 'my_iceberg_catalog',
'warehouse' = 's3://my-data-lake/warehouse',
'write.upsert.enabled' = 'false' -- Включить, если нужны обновления
);
-- Шаг 3: Запускаем потоковую вставку данных из Kafka в Iceberg.
-- Flink будет непрерывно читать данные из Kafka и записывать их в таблицу Iceberg.
INSERT INTO iceberg_events_sink
SELECT
event_id,
event_time,
user_id,
event_type
FROM kafka_event_stream;
Эта архитектура (возможна поддержка Shift Left Architecture) обеспечивает отказоустойчивую доставку данных «exactly-once» из Apache Kafka в ваше озеро данных, делая свежие данные доступными для аналитики практически в реальном времени.
Построение DWH на ClickHouse
Код курса
CLICH
Ближайшая дата курса
18 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Интеграция Apache Iceberg с ClickHouse
ClickHouse, как аналитическая СУБД, известная своей скоростью, может эффективно работать с данными в формате Iceberg. Это позволяет объединить мощь транзакционного озера данных с производительностью ClickHouse. Интеграция выполняется с помощью движка таблиц Iceberg.
Предположим, у вас есть таблица Айсберг, хранящаяся в Amazon S3. Для доступа к ней из ClickHouse нужно создать таблицу, указав путь к метаданным.
-- Создание таблицы в ClickHouse для чтения данных из существующей таблицы Iceberg
CREATE TABLE iceberg_events (
event_id UUID,
event_time DateTime,
user_id String,
payload String
)
ENGINE = Iceberg('https://s3.amazonaws.com/your-bucket/path/to/iceberg_table/', 'aws_access_key_id', 'aws_secret_access_key');
-- После создания таблицы можно выполнять сверхбыстрые аналитические запросы
-- ClickHouse будет использовать метаданные Iceberg для оптимизации чтения
SELECT
user_id,
count(*) AS event_count
FROM iceberg_events
WHERE event_time >= '2023-10-01 00:00:00'
GROUP BY user_id
ORDER BY event_count DESC
LIMIT 10;
Эта связка идеально подходит для сценариев, где данные готовятся и обновляются в озере данных с помощью таких инструментов, как Spark или Flink, а ClickHouse используется для интерактивной аналитики и построения дашбордов. Другой популярный инструмент для работы с данными это Apache Spark.
Использование Айсберг с Trino
Trino (ранее известный как PrestoSQL) является одним из ключевых движков для работы с Apache Iceberg. Он предоставляет полную поддержку SQL, включая DML-операции (INSERT, UPDATE, DELETE, MERGE), что делает его мощным инструментом для управления данными в озере.
Trino подключается к Iceberg через коннектор, который настраивается в конфигурации каталога. После настройки пользователи могут работать с таблицами Iceberg как с обычными SQL-таблицами.
Пример использования операции MERGE для обновления данных о пользователях:
-- Операция MERGE позволяет атомарно вставлять, обновлять или удалять записи
-- на основе совпадения с исходной таблицей.
MERGE INTO iceberg_schema.users_iceberg t
USING staging_schema.user_updates s
ON t.user_id = s.user_id
-- Если пользователь существует и его статус изменился, обновляем запись
WHEN MATCHED AND t.status <> s.status THEN
UPDATE SET status = s.status, updated_at = s.event_time
-- Если пользователя не существует, вставляем новую запись
WHEN NOT MATCHED THEN
INSERT (user_id, email, status, created_at, updated_at)
VALUES(s.user_id, s.email, s.status, s.event_time, s.event_time);
Trino для инженеров данных
Код курса
TRINO
Ближайшая дата курса
27 апреля, 2026
Продолжительность
16 ак.часов
Стоимость обучения
51 200
Эта возможность делает Trino отличным выбором для построения архитектуры Lakehouse, где озеро данных становится не просто хранилищем для RAW-данных, но и полноценной средой для структурированной аналитики и бизнес-анализа. Подробнее прочитать про SQL можно в нашем блоге.
Заключение
Apache Iceberg — это не просто очередной формат файлов, а фундаментальный сдвиг в подходе к построению озер данных. Он приносит надежность, производительность и гибкость, которые ранее были доступны только в дорогих и закрытых хранилищах данных. Благодаря поддержке со стороны ведущих движков обработки данных, таких как ClickHouse, Trino, Spark и Flink, Iceberg быстро становится отраслевым стандартом для создания открытых, масштабируемых и надежных аналитических платформ. Внедрение Apache Iceberg позволяет компаниям строить долговечные архитектуры данных, готовые к будущим вызовам и эволюции технологий.
Использованные референсы и материалы
- Официальная документация Apache Iceberg https://iceberg.apache.org/
- Статья «Diving Deep into Apache Iceberg» в блоге Tabular https://tabular.io/blog/deep-dive-into-iceberg/
- Статья «What is Apache Iceberg?» в блоге Dremio https://www.dremio.com/wiki/apache-iceberg/
- Статья «Apache Iceberg vs. Delta Lake vs. Apache Hudi» от Onehouse https://www.onehouse.ai/blog/apache-iceberg-vs-delta-lake-vs-apache-hudi