 271
271 
Содержание
- Архитектура и подготовка эксперимента АБ тестирования
- Математический фундамент метода
- Механизм проведения эксперимента
- Практическая реализация на Python метода АБ тестирования
- Ловушки и парадоксы экспериментатора
- Продвинутые техники в Big Data при использовании АБ тестирования
- Заключение
- Референсные ссылки:
АБ тестирование — это метод экспериментальной проверки гипотез, при котором аудитория случайным образом делится на группы и каждой группе показывается различная версия одного и того же элемента (интерфейса, функциональности, контента) для статистически обоснованного сравнения их влияния на заранее заданные метрики.
Архитектура и подготовка эксперимента АБ тестирования
Грамотное АБ тестирование начинается с проектирования системы метрик и формирования четкой гипотезы. Нельзя просто запустить тест и надеяться на случайный инсайт. Вам нужен структурированный подход к выбору измеряемых параметров.
Система метрик для теста обычно состоит из нескольких уровней:
- Целевая метрика. Это главный показатель, который вы планируете изменить. Она напрямую связана с доходами или основными целями компании.
- Прокси-метрика. Данный показатель коррелирует с основной целью, но изменяется быстрее. Ее удобно использовать для ускорения анализа коротких тестов.
- Метрика здоровья. Этот параметр помогает отследить негативные последствия изменений. Например, рост конверсии не должен приводить к падению среднего чека.
Правильный выбор метрик обеспечивает защиту от ложных выводов. Вы всегда должны видеть полную картину влияния эксперимента на весь проект. Это минимизирует риски при масштабировании удачных решений на всю аудиторию.
ML Практикум: от теории к промышленному использованию
Код курса
PYML
Ближайшая дата курса
30 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
Математический фундамент метода
В основе процесса лежит математическая статистика и теория вероятностей. Понимание этих основ критично для интерпретации результатов. АБ тестирование оперирует понятиями доверительных интервалов и уровня значимости. Для оценки достоверности результатов используются следующие концепции:
- Статистическая значимость. Этот параметр (p-value) показывает вероятность случайного получения такого результата. Обычно порог значимости устанавливают на уровне 0.05 или 5%.
- Статистическая мощность. Способность теста обнаружить реально существующее различие между вариантами. Стандартным значением в индустрии считается уровень 80%.
- Ошибка первого рода. Ситуация, когда мы ошибочно признаем различие там, где его нет. Это ложноположительный результат эксперимента.
- Ошибка второго рода. Случай, когда мы не замечаем реально существующего эффекта. Обычно это происходит из-за недостаточного размера выборки.
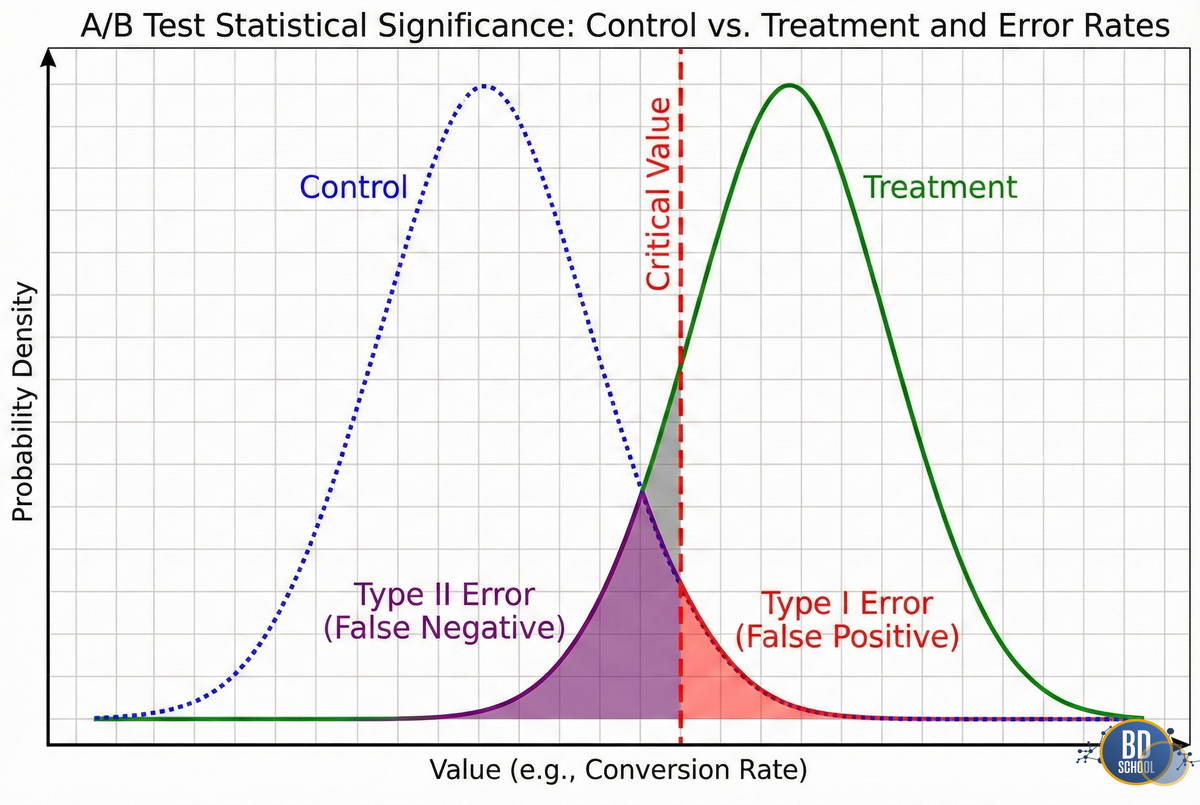
Понимание этих математических аспектов позволяет аналитику избежать поспешных выводов. Вы должны заранее рассчитать необходимый размер выборки для достижения нужной мощности. Без этого АБ тестирование превращается в простое угадывание.
Механизм проведения эксперимента
Процесс реализации теста требует строгой последовательности действий. Любое нарушение логики на этапе запуска обесценивает полученные данные. Прозрачность и чистота эксперимента — ваши главные приоритеты. Алгоритм проведения стандартного теста включает следующие шаги:
- Рандомизация. Пользователи должны попадать в группы А и Б случайным образом. Это гарантирует отсутствие систематических искажений в данных.
- АА тестирование. Перед основным тестом стоит сравнить две одинаковые группы. Если результаты совпадают, значит система сплитования работает корректно.
- Фиксация длительности. Тест должен длиться минимум один полный цикл потребления. Обычно это календарная неделя для учета фактора выходных дней.
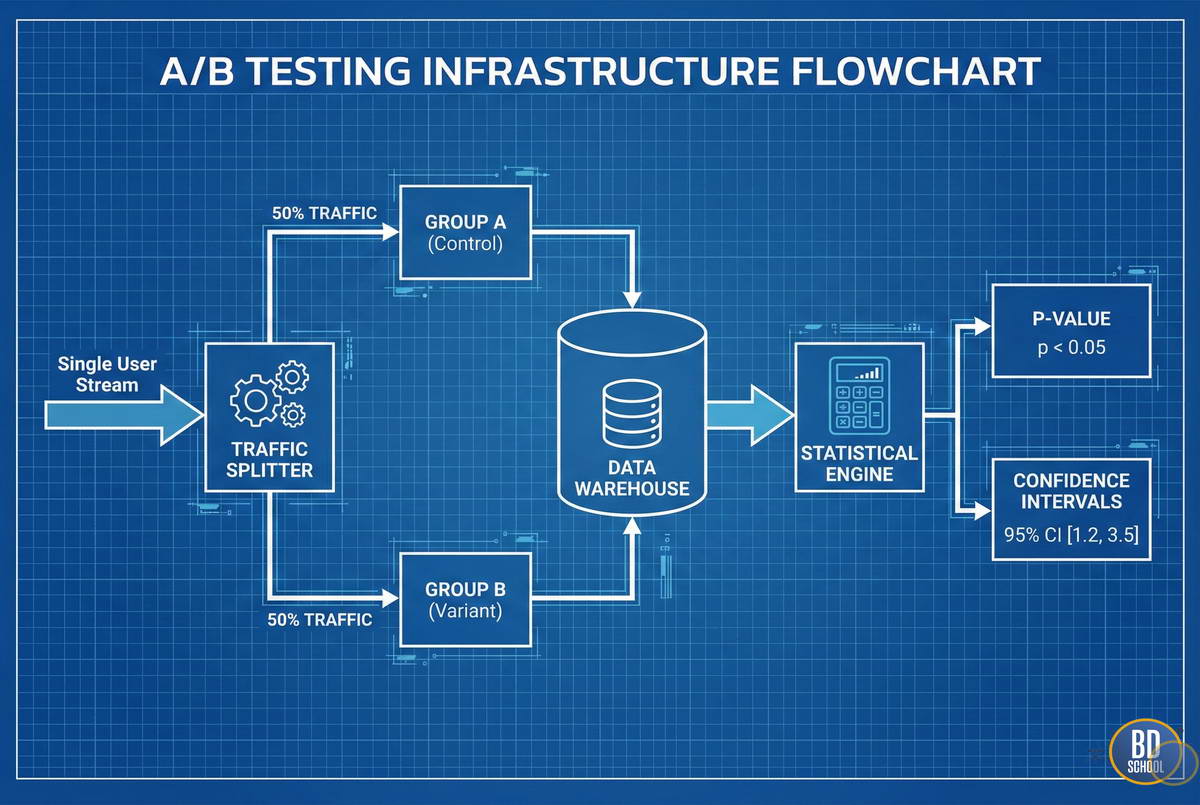
Соблюдение этого механизма гарантирует, что на результат влияют именно ваши изменения. Вы исключаете влияние внешних факторов, таких как праздники или рекламные кампании. Данный подход делает АБ тестирование надежным инструментом для Big Data проектов.
Практическая реализация на Python метода АБ тестирования
Для анализа результатов эксперимента аналитики чаще всего используют язык Python. Он обладает мощными библиотеками для статистических расчетов и визуализации данных. Вам не нужно писать сложные формулы вручную.
Ниже приведен пример базового анализа данных теста с использованием библиотеки scipy:
import numpy as np
from scipy import stats
# Данные конверсии для группы А и группы Б
clicks_a = 450
views_a = 10000
clicks_b = 510
views_b = 10000
# Пропорции конверсии
rate_a = clicks_a / views_a
rate_b = clicks_b / views_b
# Проверка гипотезы о равенстве долей (z-test)
z_stat, p_val = stats.proportions_ztest([clicks_a, clicks_b], [views_a, views_b])
print(f"Конверсия А: {rate_a:.4f}")
print(f"Конверсия Б: {rate_b:.4f}")
print(f"P-value: {p_val:.4f}")
if p_val < 0.05:
print("Результат статистически значим")
else:
print("Различия случайны")
Этот код позволяет быстро оценить разницу между вариантами интерфейса. Автоматизация расчетов снижает риск человеческой ошибки при анализе данных. Вы можете легко интегрировать такие скрипты в свои регулярные отчеты.
Ловушки и парадоксы экспериментатора
Даже опытные специалисты совершают ошибки при интерпретации данных. Существуют классические ловушки, которые могут полностью исказить выводы исследования. АБ тестирование требует критического отношения к любым аномалиям. Чаще всего аналитики сталкиваются со следующими проблемами:
Проблема подглядывания. Остановка теста сразу после достижения p-value < 0.05 недопустима. Вероятность ошибки первого рода при таком подходе резко возрастает.
Парадокс Симпсона. Эффект, когда общие данные показывают одну тенденцию, а подгруппы — противоположную. Всегда проверяйте результаты в разных сегментах аудитории.
Эффект новизны. Пользователи могут кликать на новую кнопку просто из любопытства. Со временем этот интерес угасает, и метрики возвращаются к норме.
Изучение этих ловушек помогает сохранять объективность в любой ситуации. Всегда дожидайтесь завершения запланированного срока эксперимента. Это единственный способ получить действительно надежное подтверждение вашей гипотезы.
Продвинутые техники в Big Data при использовании АБ тестирования
В условиях работы с огромными массивами данных классические методы могут быть медленными. Современное АБ тестирование использует сложные алгоритмы для ускорения получения результатов. Это особенно актуально для высоконагруженных систем. К продвинутым методам оптимизации экспериментов относятся:
- Стратификация. Предварительное разделение аудитории на похожие сегменты перед тестом. Этот метод снижает дисперсию метрик и ускоряет тест.
- Бакетное тестирование. Группировка пользователей в «корзины» перед проведением статистических тестов. Это значительно снижает вычислительную нагрузку при обработке миллиардов событий.
- Многорукие бандиты. Алгоритмы машинного обучения, которые перераспределяют трафик в реальном времени. Они направляют больше пользователей на более успешный вариант.
Эти техники позволяют проводить сотни экспериментов одновременно без потери качества. В мире Big Data скорость проверки гипотез является важным конкурентным преимуществом. Применение таких методов выделяет профессионального аналитика на фоне новичков.
Разработка и внедрение ML-решений
Код курса
MLOPS
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
Заключение
АБ тестирование остается золотым стандартом проверки продуктовых гипотез в 2026 году. Оно дает возможность объективно оценивать любые изменения и минимизировать риски. Правильное применение статистических методов гарантирует точность ваших выводов. Постоянное проведение экспериментов формирует культуру принятия решений на основе данных. Это путь к созданию по-настоящему качественных и востребованных продуктов.
Референсные ссылки:
- [A/B Testing in the Era of AI: New Methods for 2025] (https://hbr.org/2025/01/ab-testing-ai-integration)
- [Statistical Power and Sample Size calculation in Big Data] (https://towardsdatascience.com/ab-testing-power-analysis-2025)
- [The Simpson’s Paradox in Modern Product Analytics] (https://amplitude.com/blog/simpsons-paradox-analytics-2024)
- [Multi-Armed Bandits vs Traditional A/B Testing] (https://stats.stackexchange.com/questions/2025/bandits-vs-ab)