 776
776 
Содержание
Cloudera CDH (Cloudera’s Distribution including Apache Hadoop) — дистрибутив Apache Hadoop с набором программ, библиотек и утилит, разработанных компанией Cloudera для больших данных (Big Data) и машинного обучения (Machine Learning), бесплатно распространяемый и коммерчески поддерживаемый для некоторых Linux-систем (Red Hat, CentOS, Ubuntu, SuSE SLES, Debian) [1].
Состав и архитектура Клаудера CDH
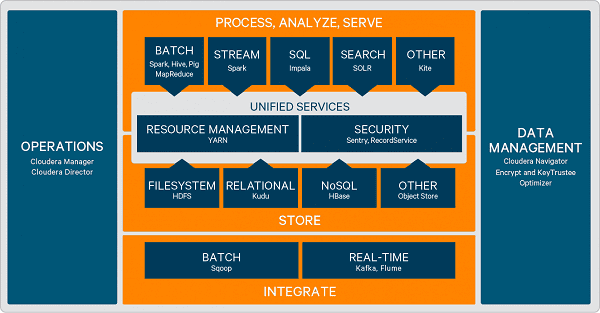
Помимо классического Hadoop от Apache Software Foundation, состоящего из 4-х основных модулей (HDFS, MapReduce, Yarn и Hadoop Common), CDH также содержит дополнительные решения Apache для работы с большими данными и машинным обучением:
- инструменты для управления потоками данных (Flume, Sqoop);
- фреймворки распределённой и потоковой обработки, а также брокеры сообщений (Spark, Kafka)
- СУБД для Big Data аналитики (HBase, Hive, Impala);
- высокоуровневый процедурный язык для выполнения запросов к большим слабоструктурированным наборам данных (Pig);
- координаторы и планировщики задач (Zookeeper, Oozie);
- средства Machine Learning (Mahout);
- набор библиотек для запуска облачных сервисов (Whirr).
Cloudera Enterprise Manager: чем CDH отличается от других дистрибутивов Apache Hadoop
Уникальным отличием CDH от других дистрибутивов Big Data инфраструктуры на основе Apache Hadoop является Cloudera Manager — собственная специализированная подсистема управления кластером. Она включает сценарии развёртывания Hadoop-инфраструктуры и средства Apache Maven, что позволяет автоматизировать создание и модификацию локальных и облачных Hadoop-сред, отслеживать и анализировать эффективность выполнения заданий, настраивать оповещения о наступлении событий, связанных с эксплуатацией инфраструктуры распределённой обработки данных [1].
Существует бесплатная версия Cloudera Manager, которая ограничена 50-ю узлами и не поддерживает мониторинг производительности, управление версиями конфигурации, сетевой протокол аутентификации Kerberos. Коммерческая версия Cloudera считается достаточно дорогой за счет высокой стоимости технического сопровождения (примерно $4 тысяч в год за узел кластера) [1], поэтому позволить ее себе могут только очень крупные компании.
Платный вариант CDH называется Enterprise и включает Cloudera Manager — инструмент для развертывания, мониторинга и управления кластером, а также Cloudera Support – профессиональная поддержка от компании-разработчика по вопросам CDH и Cloudera Manager [2].

Помимо техподдержки, CDH Enterprise 4.0 включает следующие полезные компоненты [3]:
- Мастер настройки и управления многими кластерами из одной консоли;
- цветовые теплокарты, которые показывают степень исправности кластеров Hadoop;
- поддержка хранения баз метаданных в Oracle 11g, MySQL или PostgreSQL.
История появления и развития
CDH является продуктом американской компании Cloudera, поэтому далее мы приведем основные вехи ее становления [1]:
2008 – год основания компании, приход основателей проекта Hadoop – Дуга Каттинга и Майкла Кафарелла;
2009 – оказание услуг технических консультаций по Hadoop;
2010 – разработка и поставка тиражируемого корпоративного программного обеспечения;
2012 – выпуск CDH4 с 3-мя новыми продуктами – Impala (SQL-решение для Big Data), Hue (браузерный интерфейс управления Hadoop-кластером) и Search (полнотекстовый и фасетный поиск в средах HDFS и HBase);
2014 – приобретение фирмы-разработчика технологии шифрования данных Gazzang;
2017 – поглощение нью-йоркской фирмы-разработчикы алгоритмов машинного обучения Fast Forward Labs;
2018 – выпуск CDH6 c поддержкой помехоустойчивого кодирования для HDFS, существенно снижающей физические размеры кластеров;
2019 – слияние с фирмой-конкурентом Hortonworks, которая реализовывала свой коммерческий дистрибутив Hadoop.

Как установить, настроить, обслуживать и успешно использовать Cloudera Hadoop для больших данных и машинного обучения узнайте на наших компьютерных курсах обучения различных категорий пользователей, от «чайников» до профессионалов – клаудера хадуп для инженеров, администраторов и аналитиков Big Data и Machine Learning в Москве:
Источники
- https://ru.wikipedia.org/wiki/Cloudera
- https://m.habr.com/ru/post/151062/
- http://www.tadviser.ru/index.php/Продукт:Cloudera_Enterprise