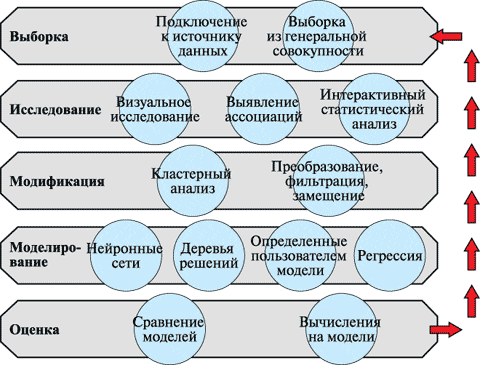
SEMMA (аббревиатура от английских слов Sample, Explore, Modify, Model и Assess) – общая методология и последовательность шагов интеллектуального анализа данных (Data Mining), предложенная американской компанией SAS, одним из крупнейших производителей программного обеспечения для статистики и бизнес-аналитики, для своих продуктов [1]. Зачем нужен стандарт SEMMA В отличие от другого широко используемого...
Data Mining - процесс поиска в сырых необработанных данных интересных, неизвестных, нетривиальных взаимосвязей и полезных знаний, позволяющих интерпретировать и применять результаты для принятия решений в любых сферах человеческой деятельности. Представляет собой совокупность методов визуализации, классификации, моделирования и прогнозирования, основанные на применении деревьев решений, искусственных нейронных сетей, генетических алгоритмов, эволюционного программирования, ассоциативной памяти, нечёткой логики. Дополнительно о...
Case Based Reasoning (CBR) - метод решения проблем рассуждением по аналогии, путем предположения на основе подобных случаев (прецедентов). Это способ решения проблем на основе уже известных решений, который широко применяется во всех областях деятельности. Например, в бизнес-анализе такое сопоставление с эталоном, целенаправленный поиск и внедрение лучших практик со стороны называется...
Прогнозирование направлено на определение тенденций динамики конкретного объекта или события на основе исторических данных, т.е. анализа его состояния в прошлом и настоящем. Таким образом, решение задачи прогнозирования требует некоторой обучающей выборки данных.
Искусственная классификация - разделение объектов по внешнему признаку для придания множеству исследуемых предметов (процессов, явлений) нужного порядка. Вообще в Data Mining, Data Science и машинном обучении (Machine Learning) в частности, искусственная классификация используется в рамках подготовки данных к моделированию, на этапе формирования датасета. Например, Data Scientist может заниматься искусственной классификацией...
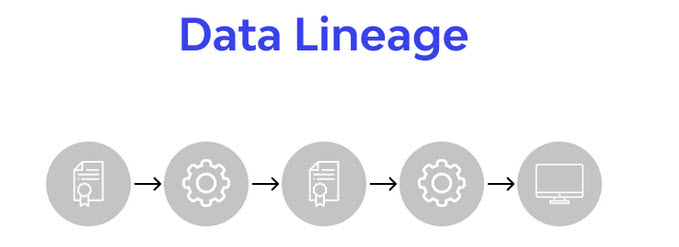
Data Lineage (линейность данных) — это процесс отслеживания, визуализации и понимания пути данных от их источника до конечного потребителя. Он включает в себя все точки остановки и трансформации на этом пути, отвечая на ключевые вопросы: откуда пришли данные, что с ними произошло и куда они направляются. Если представить все данные...
Точность распознавания - это отношение объектов, правильно классифицированных в процессе обучения, к общему количеству объектов набора данных, которые принимали участие в обучении. Точность распознавания может оцениваться с помощью матрицы ошибок (confusion matrix), о которой мы рассказываем здесь на примере оценки эффективности прогнозирования спроса с помощью Machine Learning.
Классификация - системное распределение изучаемых предметов, явлений, процессов по родам, видам, типам, по каким-либо существенным признакам для удобства их исследования; группировка исходных понятий и расположение их в определенном порядке, отражающем степень этого сходства.
Машинное обучение (Machine Learning) — класс методов искусственного интеллекта, изучающий методы построения алгоритмов, способных обучаться
Естественная классификация - разделение (или, наоборот, группировка) предметов и явлений по существенным признакам, характеризующим их внутреннюю общность. В отличие от искусственной классификации, которая сосредоточена на внешних признаках, естественная больше ориентируется на внутреннее содержание исследуемого предмета. В частности, группировка предмета со схожими по сути (овощи, посуда, техника) - это естественная классификация....
отношение объектов, неправильно классифицированных в процессе обучения, к общему количеству объектов набора данных, которые принимали участие в обучении