
Avro – это линейно-ориентированный (строчный) формат хранения файлов Big Data, активно применяемый в экосистеме Apache Hadoop и широко используемый в качестве платформы сериализации. Как устроен формат Avro для файлов Big Data: структура и принцип работы Avro сохраняет схему в независимом от реализации текстовом формате JSON (JavaScript Object Notation), что облегчает...
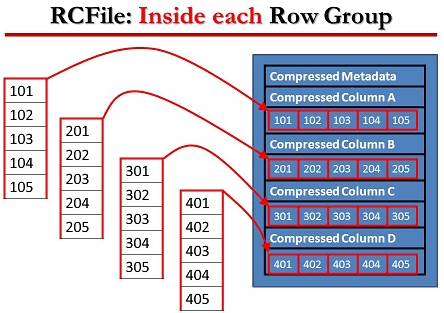
RCFile (Record Columnar File) – гибридный многоколонный формат записей, адаптированный для хранения реляционных таблиц на кластерах и предназначенный для систем Big Data, использующих MapReduce. Этот формат для записи больших данных появился в 2011 году на основании исследований и совместных усилий Facebook, Государственного университета Огайо и Института вычислительной техники Китайской академии...

ORC (Optimized Row Columnar) – это колоночно-ориентированный (столбцовый) формат хранения Big Data в экосистеме Apache Hadoop. Он совместим с большинством сред обработки больших данных в среде Apache Hadoop и похож на другие колоночные форматы файлов: RCFile и Parquet. Формат ORC был разработан в феврале 2013 года корпорацией Hortonworks в сотрудничестве...

Apache Parquet - это бинарный, колоночно-ориентированный формат хранения больших данных, изначально созданный для экосистемы Hadoop, позволяющий использовать преимущества сжатого и эффективного колоночно-ориентированного представления информации. Паркет позволяет задавать схемы сжатия на уровне столбцов и добавлять новые кодировки по мере их появления [1]. Вместе с Apache Avro, Parquet является очень популярным форматом...

Kubernetes (K8s) – это программное обеспечение для автоматизации развёртывания, масштабирования и управления контейнеризированными приложениями. Поддерживает основные технологии контейнеризации (Docker, Rocket) и аппаратную виртуализацию [1]. Зачем нужен Kubernetes Kubernetes необходим для непрерывной интеграции и поставки программного обеспечения (CI/CD, Continuos Integration/ Continuos Delivery), что соответствует DevOps-подходу. Благодаря «упаковке» программного окружения в контейнер,...

Agile – набор методов и практик для гибкого управления проектами в разных прикладных областях, от разработки ПО до реализации маркетинговых стратегий, с целью повышения скорости создания готовых продуктов и минимизации рисков за счет итерационного выполнения, интерактивного взаимодействия членов команды и быстрой реакцией на изменения. История зарождения Agile Изначально термин Agile...

HDInsight - это корпоративный сервис с открытым кодом от Microsoft для облачной платформы Azure, позволяющий работать с кластером Apache Hadoop в облаке в рамках управления и аналитической работы с большими данными (Big Data). Экосистема HDInsight Azure HDInsight – это облачная экосистема компонентов Apache Hadoop на основе платформы данных Hortonworks Data Platform...
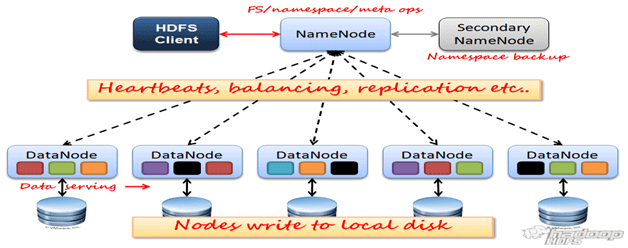
HDFS (Hadoop Distributed File System) — распределенная файловая система Hadoop для хранения файлов больших размеров с возможностью потокового доступа к информации, поблочно распределённой по узлам вычислительного кластера [1], который может состоять из произвольного аппаратного обеспечения [2]. Hadoop Distributed File System, как и любая файловая система – это иерархия каталогов с...

MapR Convergent Data Platform (MapRCDP) — дистрибутив Apache Hadoop с набором программ, библиотек и утилит Apache Software Foundation, а также средств собственной разработки американской компании MapR для больших данных (Big Data) и машинного обучения (Machine Learning) [1]. Существует три версии MapRCDP: Community Edition (M3) - бесплатная версия сообщества; Enterprise Edition...

Cloudera CDH (Cloudera’s Distribution including Apache Hadoop) — дистрибутив Apache Hadoop с набором программ, библиотек и утилит, разработанных компанией Cloudera для больших данных (Big Data) и машинного обучения (Machine Learning), бесплатно распространяемый и коммерчески поддерживаемый для некоторых Linux-систем (Red Hat, CentOS, Ubuntu, SuSE SLES, Debian) [1]. Состав и архитектура Клаудера...

Hadoop – это свободно распространяемый набор утилит, библиотек и фреймворк для разработки и выполнения распределённых программ, работающих на кластерах из сотен и тысяч узлов. Эта основополагающая технология хранения и обработки больших данных (Big Data) является проектом верхнего уровня фонда Apache Software Foundation. Из чего состоит Hadoop: концептуальная архитектура Изначально проект...
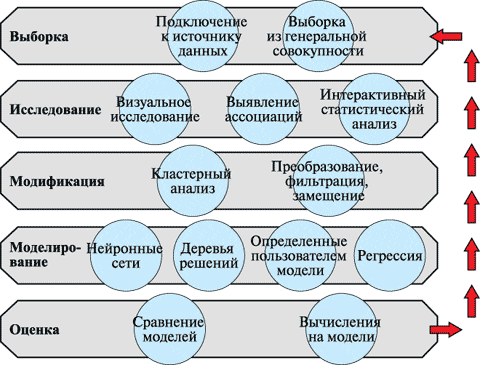
SEMMA (аббревиатура от английских слов Sample, Explore, Modify, Model и Assess) – общая методология и последовательность шагов интеллектуального анализа данных (Data Mining), предложенная американской компанией SAS, одним из крупнейших производителей программного обеспечения для статистики и бизнес-аналитики, для своих продуктов [1]. Зачем нужен стандарт SEMMA В отличие от другого широко используемого...

RFID (от английского Radio Frequency IDentification, радиочастотная идентификация) — способ автоматической идентификации объектов, когда радиосигналы считывают или записывают данные, хранящиеся в RFID-метках (транспондерах) [1]. Как появилась технология RFID: немного истории Предшественники современных RFID-меток появились в середине XX века в рамках разработки технологий передачи и распознавания сигналов в военной сфере [1]:...
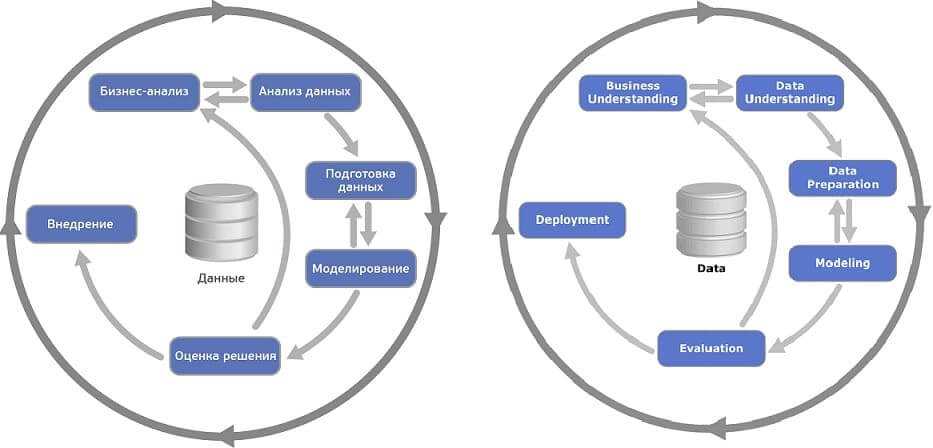
CRISP-DM (от английского Cross-Industry Standard Process for Data Mining) — межотраслевой стандартный процесс исследования данных. Это проверенная в промышленности и наиболее распространённая методология, первая версия которой была представлена в Брюсселе в марте 1999 года, а пошаговая инструкция опубликована в 2000 году [1]. CRISP-DM описывает жизненный цикл исследования данных, состоящий из...
Мультиколлинеарность — корреляция независимых переменных [1], которая затрудняет оценку и анализ общего результата [2]. Когда независимые переменные коррелируют друг с другом, говорят о возникновении мультиколлинеарности. В машинном обучении (Machine Learning) мультиколлинеарность может стать причиной переобучаемости модели, что приведет к неверному результату [3]. Кроме того, избыточные коэффициенты увеличивают сложность модели машинного...

Блокчейн (от английского blockchain, block chain – цепочка блоков) — выстроенная по определённым правилам непрерывная последовательность информационных блоков (связный список). Копии цепочек блоков хранятся на множестве разных, независимых друг от друга, компьютеров [1]. Поэтому данную цифровую цепочку называют технологией распределенного реестра [2]. История появления блокчейна Цифровизация финансовой сферы стала родоначальником термина...

Большие данные (Big Data) – совокупность непрерывно увеличивающихся объемов информации одного контекста, но разных форматов представления, а также методов и средств для эффективной и быстрой обработки [1]. Big Data: какие данные считаются большими Благодаря экспоненциальному росту возможностей вычислительной техники, описанному в законе Мура [2], объем данных не может являться...

Цифровизация Цифровизация – процесс перехода предприятия или целой экономической отрасли на новые модели бизнес-процессов, менеджмента и способов производства, основанных на информационных технологиях [1]. Цифровизация в России и за рубежом: немного истории Впервые термин «цифровизация» появился в последнее 5-летие XX века, когда в 1995-ом году американский информатик Николас Негропонте из...

Machine learning - множество математических, статистических и вычислительных методов для разработки алгоритмов, способных решить задачу не прямым способом, а на основе поиска закономерностей в разнообразных входных данных. Что такое Machine Learning Общий термин «Machine Learning» или «машинное обучение» обозначает множество математических, статистических и вычислительных методов для разработки алгоритмов, способных решить...
Big Data (Большие данные) Big Data - данные большого объема, высокой скорости накопления или изменения и/или разновариантные информационные активы, которые требуют экономически эффективных, инновационных формы обработки данных, которые позволяют получить расширенное понимание информации, способствующее принятию решений и автоматизации процессов. Для каждой организации или компании существует предел объема данных (Volume) которые...