
Scikit-learn (sklearn) - это библиотека для языка Python, предназначенная для машинного обучения, предоставляющая единый интерфейс для алгоритмов классификации, регрессии, кластеризации, снижения размерности и оценки моделей на основе данных. Библиотека, которая превращает сложную математику машинного обучения в понятные Python-команды. Если NumPy и Pandas - это "кирпичи" и "цемент" для...
Segmentation image – технология, связанная с компьютерным зрением (computer vision) и обработкой изображений, заключающаяся в обнаружении объектов определенных классов на цифровых изображениях и видео. Причем, обнаружение объектов заключается в определении класса (раскраска) каждого пикселя на цифровом изображении или на каждом кадре видеопотока. Пример кода вы можете посмотреть на GitHub MachineLearningIsEasy...
Object detection – технология, связанная с компьютерным зрением (computer vision) и обработкой изображений, заключающаяся в обнаружении объектов определенных классов на цифровых изображениях и видео. Причем, обнаружение объектов заключается в определении границ объекта на цифровом изображении или видео. В качестве примера мы можем использовать открытую программную библиотеку для машинного обучения TensorFlow, разработанную...
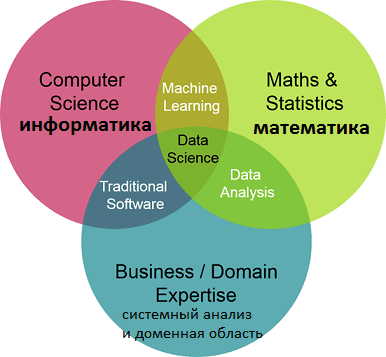
Data Science – это наука о данных, объединяющая разные области знаний: информатику, математику и системный анализ. Сюда входят методы обработки больших данных (Big Data), интеллектуального анализа данных (Data Mining), статистические методы, методы искусственного интеллекта, в т.ч машинное обучение (Machine Learning). DS включает методы проектирования и разработки баз данных и прикладного...
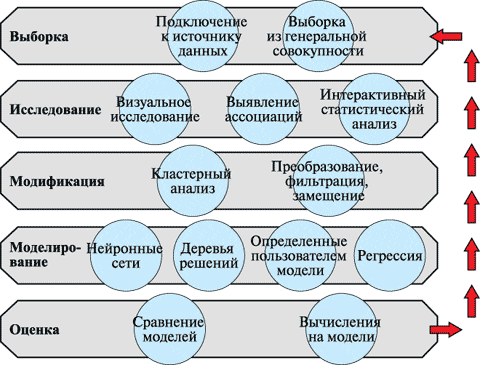
SEMMA (аббревиатура от английских слов Sample, Explore, Modify, Model и Assess) – общая методология и последовательность шагов интеллектуального анализа данных (Data Mining), предложенная американской компанией SAS, одним из крупнейших производителей программного обеспечения для статистики и бизнес-аналитики, для своих продуктов [1]. Зачем нужен стандарт SEMMA В отличие от другого широко используемого...
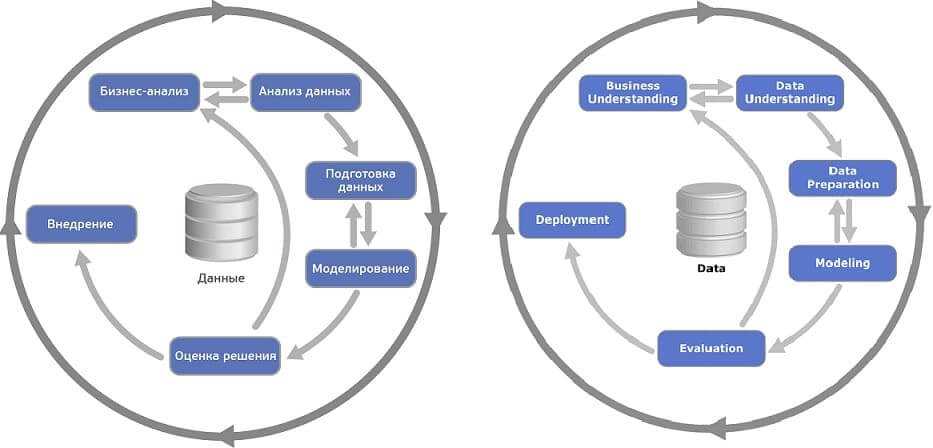
CRISP-DM (от английского Cross-Industry Standard Process for Data Mining) — межотраслевой стандартный процесс исследования данных. Это проверенная в промышленности и наиболее распространённая методология, первая версия которой была представлена в Брюсселе в марте 1999 года, а пошаговая инструкция опубликована в 2000 году [1]. CRISP-DM описывает жизненный цикл исследования данных, состоящий из...
Мультиколлинеарность — корреляция независимых переменных [1], которая затрудняет оценку и анализ общего результата [2]. Когда независимые переменные коррелируют друг с другом, говорят о возникновении мультиколлинеарности. В машинном обучении (Machine Learning) мультиколлинеарность может стать причиной переобучаемости модели, что приведет к неверному результату [3]. Кроме того, избыточные коэффициенты увеличивают сложность модели машинного...

Machine learning - множество математических, статистических и вычислительных методов для разработки алгоритмов, способных решить задачу не прямым способом, а на основе поиска закономерностей в разнообразных входных данных. Что такое Machine Learning Общий термин «Machine Learning» или «машинное обучение» обозначает множество математических, статистических и вычислительных методов для разработки алгоритмов, способных решить...
Data Mining - процесс поиска в сырых необработанных данных интересных, неизвестных, нетривиальных взаимосвязей и полезных знаний, позволяющих интерпретировать и применять результаты для принятия решений в любых сферах человеческой деятельности. Представляет собой совокупность методов визуализации, классификации, моделирования и прогнозирования, основанные на применении деревьев решений, искусственных нейронных сетей, генетических алгоритмов, эволюционного программирования, ассоциативной памяти, нечёткой логики. Дополнительно о...
Case Based Reasoning (CBR) - метод решения проблем рассуждением по аналогии, путем предположения на основе подобных случаев (прецедентов). Это способ решения проблем на основе уже известных решений, который широко применяется во всех областях деятельности. Например, в бизнес-анализе такое сопоставление с эталоном, целенаправленный поиск и внедрение лучших практик со стороны называется...
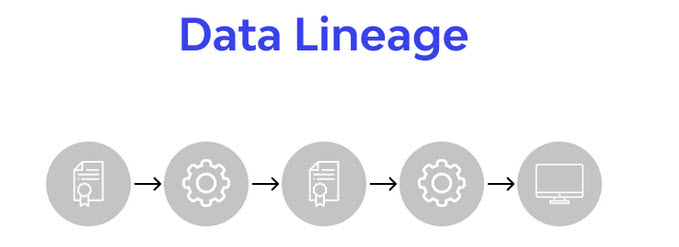
Data Lineage (линейность данных) — это процесс отслеживания, визуализации и понимания пути данных от их источника до конечного потребителя. Он включает в себя все точки остановки и трансформации на этом пути, отвечая на ключевые вопросы: откуда пришли данные, что с ними произошло и куда они направляются. Если представить все данные...
Машинное обучение (Machine Learning) — класс методов искусственного интеллекта, изучающий методы построения алгоритмов, способных обучаться