
Что такое потоковая аналитика больших данных, какие бывают СУБД потоковой передачи, когда и зачем их использовать, а также что влияет на выбор этих инструментов хранения и аналитической обработки Big Data. Что такое потоковые базы данных и как они работают Мы уже упоминали, что аналитика данных в реальном времени может быть...
Чего не хватает в PL/Python и зачем нужна еще одна библиотека для создания Python-скриптов обработки данных в Greenplum. Возможности API GreenplumPython и сравнение с pandas. Что такое PL/Python и как это работает в Greenplum Мы уже писали, что Greenplum изначально поддерживает Python, предоставляя PL/Python – загружаемый процедурный язык, который позволяет...
В Apache Spark есть 3 структуры данных, каждая из которых имеет собственный API со своими достоинствами и недостатками. Сегодня разберем плюсы и минусы Dataset API, а также рассмотрим особенности JOIN-операций в нем. Почему Dataset API в Apache Spark работает только со Scala и Java Напомним, структура данных Dataset впервые появилась...
Недавно мы писали про резидентную графовую СУБД Memgraph, которая хранит данные в оперативной памяти. Сегодня рассмотрим, как выгрузить граф знаний из Memgraph на диск с помощью библиотеки GQLAlchemy, а также поговорим про персистентность другого популярного NoSQL-хранилища Redis, которое также является резидентным, но относится к семейству key-value. Как сохранить данные из...
Как Greenplum расширяет MVCC-модель PostgreSQL для управления доступом к данным в многопользовательской среде, обеспечивая согласованность и изоляцию транзакций для нескольких сегментов в большом кластере. Преимущества моментальных снимков перед блокировками и их польза для резервного копирования. MVCC и транзакции в Greenplum с PostgreSQL Будучи основанной на PostgreSQL, о чем мы писали здесь,...

23 марта 2023 года вышел очередной релиз Apache Flink. Разбираемся с главными новинками выпуска 1.17.0: полезные фичи, исправленные ошибки и улучшения для дата-инженера и разработчика распределенных приложений. Новинки пакетной обработки В Apache Flink 1.17 внесено множество изменений в области пакетной и потоковой обработки. В частности, добавлен новый пакетный Streaming Warehouse...
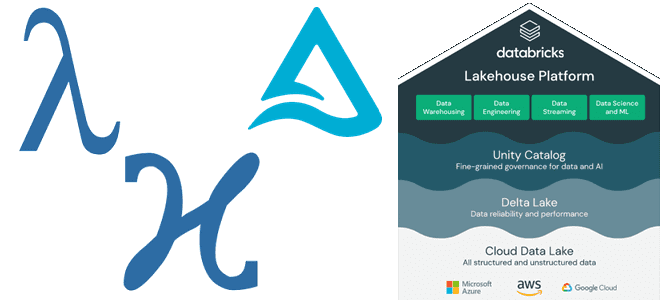
Как Lakehouse объединяет пакетную и потоковую обработку, какие проблемы возникают при реализации этой гибридной архитектуры данных и каким образом они решаются с помощью Delta-подхода и Apache Spark Structured Streaming. Краткая история появления дельта-архитектуры от лямбда- и каппа-моделей Мир больших данных постоянно развивается: появляются новые технологии и архитектурные шаблоны. В частности,...

В рамках продвижения нашего нового курса по графовым алгоритмам в бизнес-приложениях сегодня познакомимся с графовой резидентной СУБД Memgraph и сравним ее с Neo4j, определив достоинства, недостатки и варианты использования в задачах аналитики больших данных. Memgraph vs Neo4j Memgraph — это высокопроизводительная графовая СУБД с открытым исходным кодом, которая хранит и...
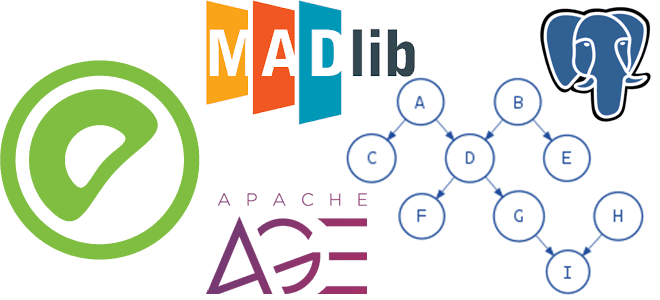
Инструменты графовых алгоритмов для аналитики больших данных в PostgreSQL и Greenplum: обзор расширений и возможностей. Знакомимся с Apache AGE и MADlib. Графовая аналитика в PostgreSQL Реляционные СУБД отлично подходят для хранения данных с четкой структурой практически в любой предметной области и предлагают широкие возможности аналитической обработки таких данных. Но иногда реляционная...
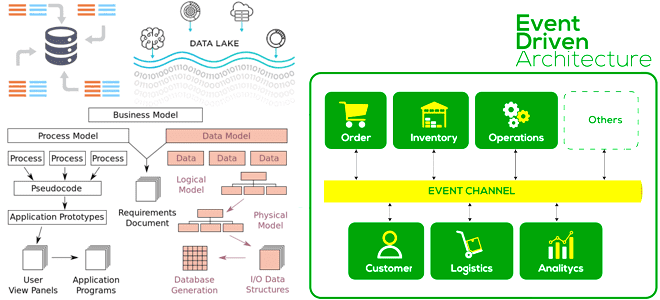
Чем схема, применяемая к данным, при чтении отличается от схемы при записи, почему она вызывает GIGO-проблему в Data Lake, и как применить принципы функциональной дата-инженерии к архитектуре данных, управляемой событиями. Схема при чтении или при записи: главное отличие NoSQL-решений от реляционных СУБД NoSQL-решения и Apache Hadoop реализуют стратегию «схема при...

Как организовать эффективное планирование заданий Apache Spark в микросервисной архитектуре, управляемой событиями, с помощью паттернов Idempotent Consumer и Transactional Outbox. Проблемы оркестрации Spark-заданий shell-скриптами и переход к EDA-архитектуре При большом количестве приложений Apache Spark, которые взаимодействуют друг с другом как самостоятельные микросервисы, растет сложность управления ими. В частности, shell-скрипты позволяют...

Что общего у Neo4j с TigerGraph и чем они отличаются: разбираемся с популярными графовыми СУБД и их возможностями для аналитики больших данных в рамках продвижения нашего нового курса по графовым алгоритмам в бизнес-приложениях. Сравнение Neo4j с TigerGraph Подробно об архитектуре, принципах работы, функциональных возможностях и вариантах использования TigerGraph мы писали...

Сегодня познакомимся с расширением PostGIS, которое позволяет PostgreSQL и Greenplum обрабатывать пространственные данные в геолокационных и логистических задачах. Как оно устроено и каковы ограничения его практического использования в MPP-СУБД. Что такое PostGIS и как это работает Как и PostgreSQL, Greenplum поддерживает геометрические типы данных, с помощью которых можно строить статичные...

Недавно мы писали про использование AirFlow для оркестрации dbt-конвейеров. Сегодня познакомимся с адаптером dbt-flink, который позволяет запускать SQL-конвейеры в проекте dbt на Apache Flink. Зачем нужен адаптер dbt к Apache Flink и как он работает В аналитике данных огромную роль играет эффективный, стабильный и надежный ETL-процесс, реализовать который можно с...

Зачем биотехнологической платформе Polly от Elucidata понадобился API SQL-запросов в облачном сервисе Elasticsearch и как дата-инженеры реализовали его, развернув Delta Lake с AWS Atnena и S3. Что не так с SQL-запросами в облачном Elasticsearch на AWS Ежедневно биотехнологическая платформа Polly от Elucidata обрабатывает гигабайты биомолекулярных данных для биологов по всему...

Чтобы сделать наши курсы для дата-инженеров и разработчиков распределенных приложений еще более полезными, сегодня мы расскажем про новый бесплатный сервис от маркетплейса Joom для поиска проблем с производительностью Spark-заданий. Разбираемся, как он работает и чем полезен дата-инженеру. 4 главных проблемы Spark-приложений, их последствия и трудности обнаружения Если количество Spark-приложений невелико,...

Что такое dbt, чем полезен этот инструмент для анализа и инженерии данных, зачем переносить в него бизнес-логику обработки данных и представлять эти задачи в DAG-конвейере Apache AirFlow. Python и SQL для анализа данных и дата-инженерии: versus или вместе? Распил крупных монолитных систем на множество автономных взаимодействующих друг с другом приложений...

Сегодня в рамках продвижения нашего нового курса по графовым алгоритмам в бизнес-приложениях, решим классическую задачу логистики в графовой базе данных Neo4j без использования методов ее специальной библиотеки Graph Data Science, а средствами Cypher-запросов. Постановка задачи: критерии оценки для поиска кратчайшего пути Поиск кратчайшего пути – это классическая задача на графах,...
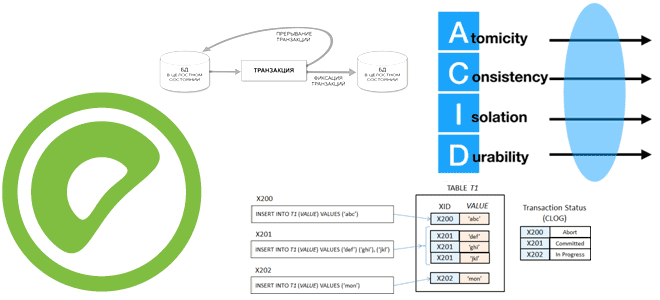
Недавно мы писали про трудности реализации ACID-требований к транзакциям в распределенных базах данных и способах их решения. Сегодня рассмотрим, как это работает в Greenplum с Arenadata DB: уровни изоляции, идентификаторы транзакций, моментальные снимки и MVCC-модель управления параллелизмом. Как GP и Arenadata DB реализуют распределенные транзакции Будучи основанной на PostgreSQL, Greenplum...
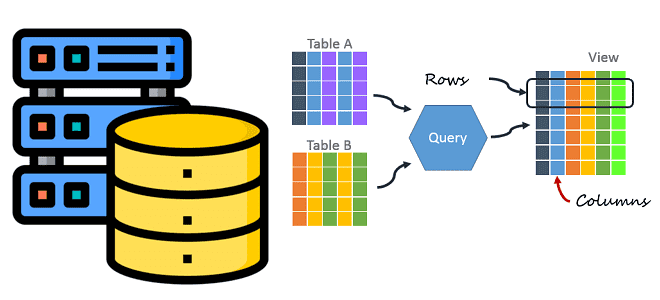
Как данные хранятся на диске при разной ориентации хранилища в СУБД: чем отличаются колоночные базы от строковых с точки зрения практического использования в дата-инженерии. Сравнительная таблица с примерами и выводами. Как данные хранятся на диске и при чем здесь ориентация СУБД Способы хранения данных в СУБД можно разделить на 2...