
Как использовать Greenplum в проектах машинного обучения: знакомимся с расширением PostgresML и модулем pgvector. Возможности и ограничения плагинов, превращающих MPP-СУБД в полноценный MLOps-инструмент. Как превратить Greenplum в векторную базу данных с расширением pgvector Будучи вариацией PostgreSQL с механизмами массово-параллельной загрузки, Greenplum отлично справляется с огромным объемом данных. Однако, к хранилищам...
Пример ETL-процесса в DAG Apache AirFlow: извлечение данных о выполненных заказах из PostgreSQL, преобразование в JSON-документ и загрузка в NoSQL-хранилище Elasticsearch в виде JSON-документа с отправкой уведомления в Telegram. Разработка и запуск кода в Google Colab. Постановка задачи и проектирование конвейера в виде DAG AirFlow О том, как построить простой...

Как выбирать политики распределения и разделения данных в Greenplum, в чем польза динамического сканирования индексов, зачем регулярно использовать операции VACUUM и ANALYZE, из-за чего тормозят SQL-запросы и как это исправить. Эффективное распределение и разделение Будучи основанной на PostgreSQL, Greenplum расширяет возможности этой замечательной СУБД, добавляя операции с массово-параллельной обработкой. Для...
Простой пример объединения нескольких задач, описанных в разных Python-файлах, в единый DAG Apache AirFlow на кейсе выгрузки из реляционной базы PostgreSQL данных о выполненных заказах за последние 100 дней. Разработка и запуск кода в Google Colab. Объединение задач из отдельных Python-файлах в один DAG AirFlow Я уже показывала, как построить...
Какие ошибки и угрозы нарушения безопасности были обнаружены в Apache AirFlow в 2023 году: обзор уязвимостей и способы их устранения. 9 уязвимостей среднего уровня серьезности В текущем году в Apache AirFlow было обнаружено 15 уязвимостей разной степени критичности. К наименее серьезным с маркировкой Medium и оценкой от 4 до 6.9...

Из-за чего приложения Flink работают быстрее Spark: разница в моделях обработки данных, управлении памятью, методах оптимизации, дизайне API и личный опыт использования. Apache Flink vs Spark: сходства и отличия Apache Spark и Flink считаются наиболее популярными фреймворками разработки распределенных приложений в области Big Data. Они достаточно похожи, что мы ранее...
Как включить сжатие данных в Greenplum, какие алгоритмы сжатия поддерживает эта MPP-СУБД и можно ли установить разные параметры сжатия для отдельных столбцов и разделов больших таблиц. Примеры SQL-запросов и рекомендацию по настройке. Как Greenplum сжимает данные: примеры настроек и SQL-запросов Эффективное сжатие данных позволяет Greenplum снижать потребление памяти и повышать...

Почему в Greenplum 7 восстановление данных из резервной копии базы стало медленнее и как разработчики это исправили: причины замедления и способы их устранения. SQL-синтаксис и восстановление из бэкапа Напомним, 7-ой релиз Greenplum имеет много интересных и полезных функций, включая возможность определять партиционированную таблицу без определения дочерних разделов и изменять таблицы...

Сегодня рассмотрим, какие системные метрики Greenplum необходимо отслеживать администратору кластера и дата-инженеру для оценки работоспособности и эффективности этой СУБД, а также с помощью каких инструментов это сделать. Мониторинг средствами Greenplum Прежде всего, стоит отметить, что контролировать Greenplum можно с помощью различных инструментов, включенных в систему или доступных в качестве надстроек....
Сегодня усложним пример из прошлой статьи с простым ETL-конвейером, который добавлял в базу данных интернет-магазина новые записи о клиентах, сгенерированные с помощью библиотеки Faker. Разбираем, как удалить из PostgreSQL данные об успешно доставленных заказах за прошлый месяц, предварительно сохранив их в JSON-файл с многоуровневой структурой. Пишем и запускаем DAG Apache...
Сегодня реализуем простой ETL-конвейер для реляционной СУБД PostgreSQL, запустив Apache AirFlow в интерактивной среде Google Colab. Пример DAG из 3-х задач: получить количество строк в одной из таблиц БД, сгенерировать новые строки и записать их, не нарушив ограничений уникальности первичного ключа. Постановка задачи Возьмем в качестве примера базу данных для...
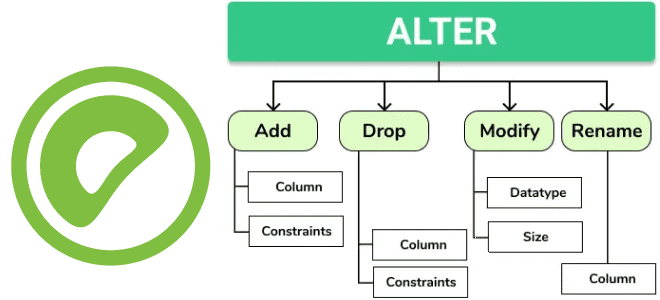
Какие команды изменения таблиц добавлены в 7-ю версию Greenplum и чем они полезны дата-инженеру. Разбираемся с новыми функциями: как добавить столбец, изменить его тип, кодировку хранения и перезаписать несколько таблиц одной командой. Добавление столбца О новых функциях работы с партиционированаными таблицами в Greenplum 7 мы уже писали. В частности, Greenplum...
Чем полезны новые фичи Apache Spark SQL, выпущенные в релизе 3.4. Разбираемся с псевдонимами столбцов и параметризованными SQL-запросами на простых примерах, запуская Spark-приложение в Google Colab. Псевдонимы столбцов Хотя с момента выхода Apache Spark 3.4 в апреле 2023 года, о чем мы писали здесь, прошло почти полгода, возможность ссылаться на...

Что такое спекулятивное выполнение заданий в Apache Flink, какой планировщик его поддерживает, какие конфигурации нужно настроить для его эффективного использования и зачем при этом переопределять поведение генератора разделений потокового источника данных. Что такое спекулятивное выполнение заданий Apache Flink Распределенная природа Apache Flink приводит к тому, что приложения, созданные с помощью...
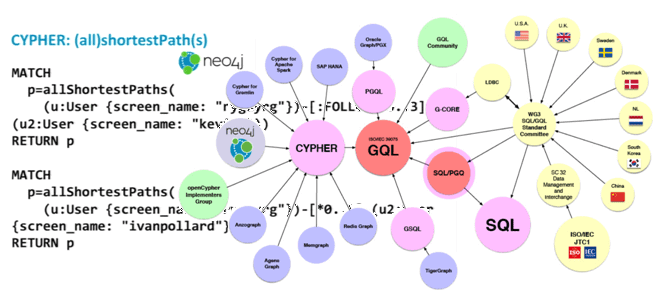
Кто и зачем создает аналог SQL для запросов к графовым базам данных, когда выйдет официальная версия стандарт и при чем здесь Cypher из Neo4j. Что такое GQL и кто его разрабатывает В рамках продвижения нашего курса по графовым алгоритмам в бизнес-приложениях мы часто рассказываем про инструменты хранения и анализа графовых...
Почему запросы Flink SQL перестают работать эффективно при больших объемах несбалансированном распределенных данных и как это исправить с помощью мини-пакетной агрегации. Что такое MiniBatch, как это работает и чем может опасно. Перекос данных по ключу группировки в Apache Flink Flink SQL — это мощный инструмент, объединяющий пакетную и потоковую обработку...

Как расширить возможности MPP-СУБД Greenplum, используя фоновые рабочие процессы и почему это небезопасно. А также рассмотрим, что такое API Greenplum Partner Connector и как это использовать. Фоновые рабочие процессы Обычно фоновыми процессами в СУБД называются системные задания, которые запускаются при запуске базы данных и выполняют различные служебные задачи. К таким рутинным сервисным задачам...
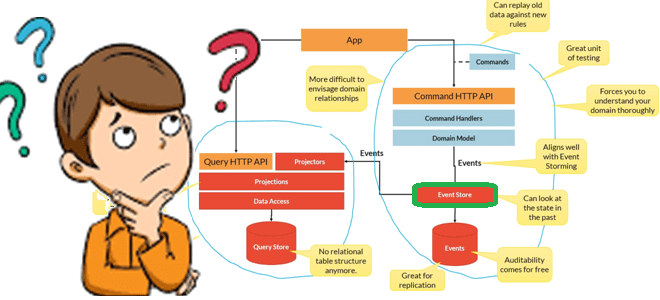
Что представляет собой паттерн проектирования микросервисов под названием источник событий (Event Sourcing) и как его реализовать в реляционных базах данных и NoSQL-системах. Разбираемся с архитектурой данных и архитектурой ПО на практических примерах. Архитектурный шаблон Event Sourcing Многие архитектурные шаблоны рассматривают сущности (entity) как основную концепцию, описывая способы их сохранения и...
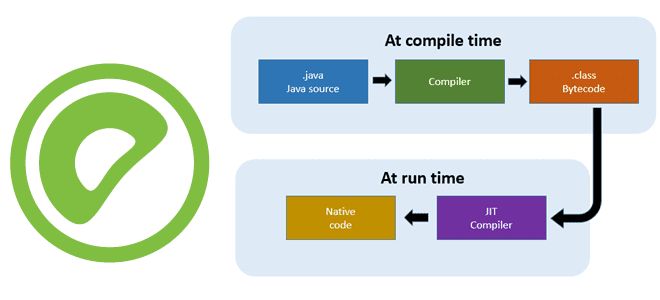
Чтобы SQL-запросы выполнялись быстрее, в Greenplum, как и в PostgreSQL, поддерживается JIT-компиляция. Читайте далее, что это такое и всегда ли эта динамическая генерация машинного кода на лету дает выигрыш в скорости для аналитики больших данных. Что такое JIT-компиляция Технология JIT-компиляции (Just-In-Time) позволяет генерировать машинный код во время выполнения программы. В...

Мы уже писали про механизмы обеспечения высокой доступности в кластере Greenplum. Сегодня рассмотрим, какие инструменты и приемы помогут выявить сбои координатора и сегментов, а также как администратору кластера этой MPP-СУБД восстановить ее работоспособность. Что такое зеркалирование сегментов Greenplum Напомним, кластер Greenplum представляет собой несколько экземпляров популярной объектно-реляционной базы данных (БД)...