
Сегодня мы рассмотрим Apache Hive и Cloudera Impala – аналитические SQL-средства для работы с данными, хранящимися в экосистеме Apache Hadoop и других Big Data хранилищах: HDFS, HBase, Amazon S3. Читайте в нашей статье, что такое Hive и Impala, где они используются и почему они не заменяют, а дополняют друг друга....
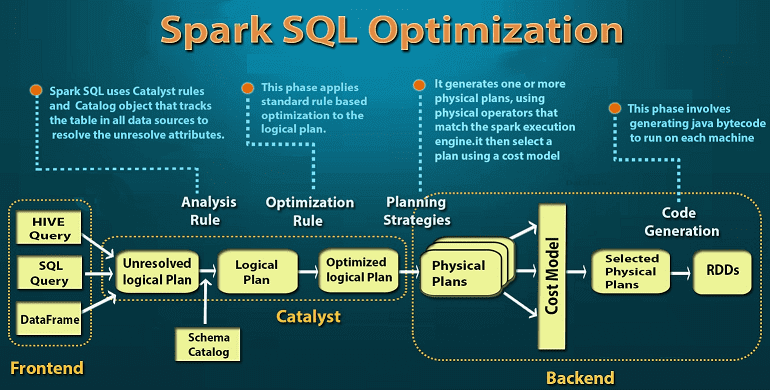
Завершая тему SQL-оптимизации в Big Data на примере Apache Spark, сегодня мы подробнее расскажем, какие действия выполняются на каждом этапе преобразования дерева запросов в исполняемый код. А рассмотрим, за счет чего так эффективна автоматическая кодогенерация в Catalyst. Читайте в нашей статье про планы выполнения запросов, квазиквоты Scala и операции с...
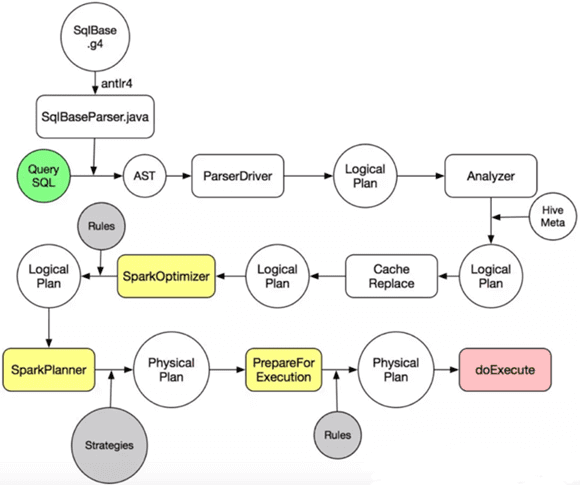
Продолжая разговор про SQL-оптимизацию в Apache Spark, сегодня мы рассмотрим, что такое дерево запросов и как оптимизатор Catalyst преобразует его в исполняемый байт-код при аналитической обработке Big Data в рамках Спарк. Деревья структурированных запросов и правила управления ими в Apache Spark Отметим, что деревья запросов отличаются от алгебраических деревьев операций тем, что...
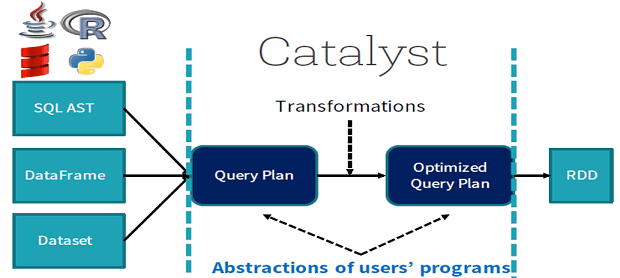
Мы уже немного рассказывали об SQL-оптимизации в Apache Spark. Продолжая эту тему, сегодня рассмотрим подробнее, что такое Catalyst – встроенный оптимизатор структурированных запросов в Spark SQL, а также поговорим про базовые понятия SQL-оптимизации. Читайте в нашей статье о логической и физической оптимизации, плане выполнения запросов и зачем эти концепции нужны...
Завершая сравнение структур данных Apache Spark, сегодня мы рассмотрим, в каких случаях разработчику Big Data стоит выбирать датафрейм (DataFrame), датасет (DataSet) или RDD и почему. Также мы приведем практический примеры и сценарии использования (use cases) этих программных абстракций, важных при разработке систем и сервисов по интерактивной аналитике больших данных с...
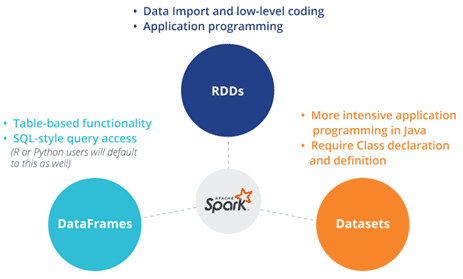
Продолжая говорить о сходствах и отличиях структур данных Apache Spark, сегодня мы рассмотрим, чем похожи датафрейм (DataFrame), датасет (DataSet) и RDD с позиции разработчика Big Data. Читайте в нашей статье, как обеспечивается оптимизация кода, безопасность типов при компиляции и прочие аспекты, важные при разработке распределенных программ и интерактивной аналитике больших...
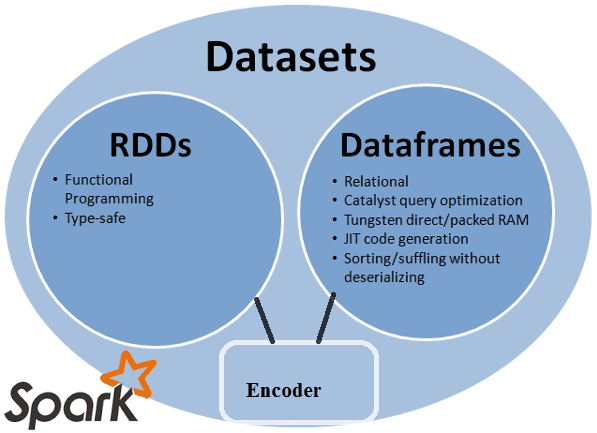
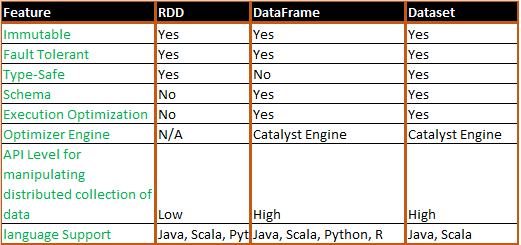
В прошлый раз мы рассмотрели понятия датафрейм (DataFrame), датасет (DataSet) и RDD в контексте интерактивной аналитики больших данных (Big Data) с помощью Spark SQL. Сегодня поговорим подробнее, чем отличаются эти структуры данных, сравнив их по разным характеристикам: от времени возникновения до специфики вычислений. Критерии сравнения структур данных Apache Spark Прежде...
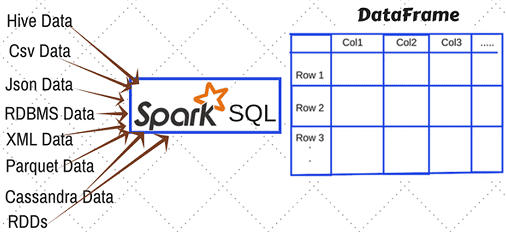
Этой статьей мы открываем цикл публикаций по аналитике больших данных (Big Data) с помощью SQL-инструментов: Apache Impala, Spark SQL, KSQL, Drill, Phoenix и других средств работы с реляционными базами данных и нереляционными хранилищами информации. Начнем со Spark SQL: сегодня мы рассмотрим, какие структуры данных можно анализировать с его помощью и...
KSQL - это движок SQL с открытым исходным кодом для Apache Kafka. Он обеспечивает простой, но мощный интерактивный SQL интерфейс для потоковой обработки на Kafka, без необходимости писать код на языке программирования, таком как Java или Python. SELECT * FROM payments-kafka-stream WHERE fraud_probability > 0.8 ...