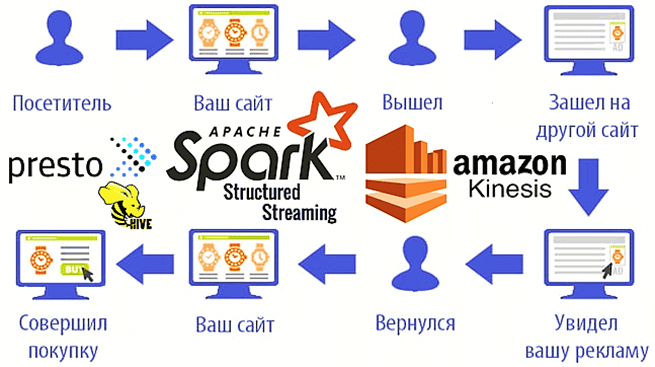
Мы уже рассказывали о возможностях ретаргетинга и использовании Apache Spark Structured Streaming для реализации этого рекламного подхода на примере Outbrain. Такое применение технологий Big Data сегодня считается довольно распространенным. Чтобы понять, как это работает на практике, рассмотрим кейс маркетинговой ИТ-компании MIQ, которая запускает Spark-приложения на платформе Qubole и сервисах Amazon,...

Продолжая разговор про фиксацию заданий Apache Spark при работе с облачными хранилищами больших данных, сегодня подробнее рассмотрим, насколько эффективны commit-протоколы экосистемы Hadoop, предоставляемые по умолчанию, и почему известный разработчик Big Data решений, компания Databricks, разработала собственный алгоритм. Читайте далее про сравнение протоколов фиксации заданий в Spark-приложениях: результаты оценки производительности и...

Сегодня поговорим про особенности транзакций в Apache Spark, что такое фиксация заданий в этом Big Data фреймворке, как она связано с протоколами экосистемы Hadoop и чем это ограничивает переход в облако с локального кластера. Читайте далее, как найти компромисс между безопасностью и высокой производительностью, а также чем облачные хранилища отличаются...

В этой статье рассмотрим, что такое Apache Spark Structured Streaming и Spark Streaming, чем они отличаются и что общего между этими 2-мя способами обработки потоковых данных в самом популярном фреймворке аналитики больших данных. Читайте далее, как микро-пакетная передача приближается к режиму реального времени и при чем здесь структуры данных для...

Вчера мы говорили про реализацию exactly once семантики доставки сообщений в Apache Spark Structured Streaming. Сегодня рассмотрим, что не так с размером компактных файлов для хранения контрольных точек потоковой передачи, какие параметры конфигурации Spark SQL отвечают за такое логирование и как ускорить микро-пакетную обработку больших данных и чтение результатов выполнения...

Недавно мы рассматривали оптимизацию SQL-запросов и выполнение JOIN-операций в Apache Spark. Сегодня поговорим, что обеспечивает строго однократную семантику доставку сообщений (exactly once) в этом Big Data фреймворке и как на это влияют особенности микро-пакетной обработки больших данных с помощью заданий Spark Structured Streaming. Особенности exactly once доставки сообщений в Apache...
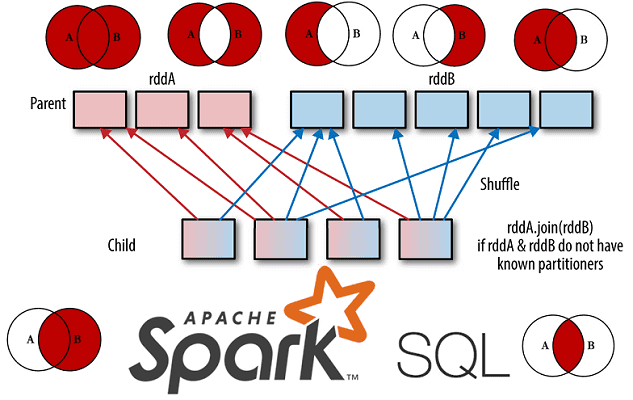
Развивая наши новые курсы по Apache Spark, сегодня мы рассмотрим Join-операции в SQL-модуле этого популярного фреймворка для аналитики больших данных. Читайте далее, чем отличаются разные Join-соединения друг от друга, как они реализуются в Spark SQL, какие существуют механизмы для их выполнения и от чего зависит выбор того или иного способа...
Сегодня поговорим про особенности построения конвейеров машинного обучения в Apache Spark. Читайте далее, как Spark MLLib реализует идеи MLOps, что такое трансформеры и оценщики, из чего еще состоит Machine Learning pipeline, как он работает с кодом на Scala, Java, Python и R, а также каковы условия практического использования методов fit(),...
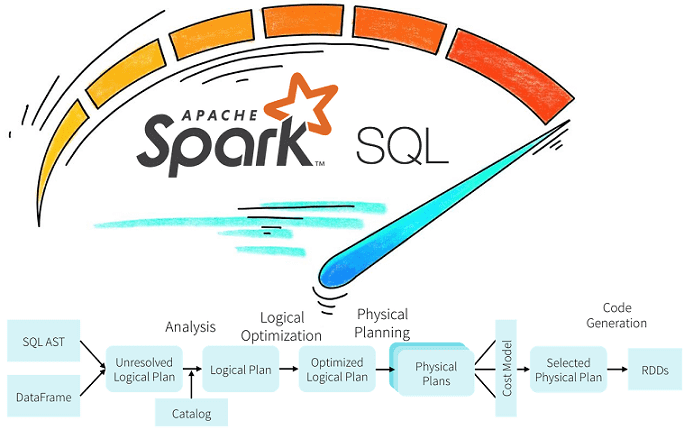
Продолжая разбирать практические особенности аналитики больших данных с Apache Spark, сегодня рассмотрим возможности оптимизации SQL-запросов в этом Big Data фреймворке с помощью механизмов предикатного и проекционного сжатия. Читайте далее про реализацию Predicate Pushdown и Projection Pushdown в Apache Spark 3, а также их связь с форматами Parquet и AVRO. Механизмы...
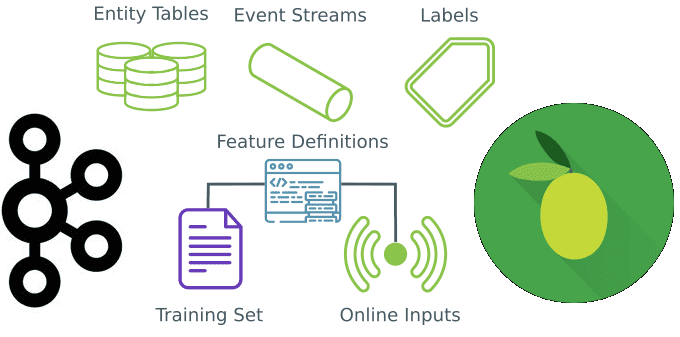
Вчера мы говорили про промышленный Machine Learning в больших данных и рассматривали проблемы микросервисной архитектуры в системах машинного обучения. Продолжая разбирать, как Feature Store повышает эффективность MLOps-процессов, сокращая цикл разработки согласно Agile-идеям, сегодня мы приготовили для вас краткий обзор хранилища признаков StreamSQL. Читайте далее, что такое StreamSQL, как оно устроено,...
Сегодня рассмотрим, когда микросервисные архитектуры не подходят для систем машинного обучения и какие технологии Big Data следует использовать в этом случае. В этой статье мы расскажем, что такое Feature Store, как это хранилище признаков для моделей Machine Learning повышает эффективность MLOps-процессов и сокращает цикл разработки ML-систем, а также при чем...

Продолжая рассказывать про курсы Apache Spark для разработчиков на практических примерах, сегодня рассмотрим, как кэширование данных позволяет оптимизировать распределенные вычисления в этом Big Data фреймворке. Читайте далее, как ускорить выполнение запросов в Spark SQL, чем отличаются функции cache() и persist(), из чего состоит план запроса и каковы альтернативы кэшированию данных...

Интерактивная аналитика больших данных - одно из самых востребованных и коммерциализированных приложений для технологий Big Data. В этой статье мы рассмотрим, как крупный британский ритейлер запустил цифровую трансформацию своей ИТ-архитектуры, уходя от традиционного DWH с пакетной обработкой к событийно-стриминговой облачной платформе на базе Apache Kafka и Snowflake. Зачем модному ритейлеру...

Поскольку курсы по Apache Spark нужны не только разработчикам распределенных приложений, но и аналитикам больших данных с дата-инженерами, сегодня мы рассмотрим, какие средства этого фреймворка позволяют выполнять очистку данных и повышать их качество. Читайте далее, что такое Cleanframes в Spark SQL, чем полезна эта библиотека и каковы ее ограничения. Apache...

В этой статье разберем, что такое прикладная аналитика больших данных на примере практического использования Apache Kafka и Druid в Netflix для обработки и визуализации метрик пользовательского поведения. Читайте далее, зачем самой популярной стриминговой компании отслеживать показатели клиентских устройств и как это реализуется с помощью Apache Druid, Kafka и других технологий...

Недавно мы рассказывали про систему онлайн-аналитики Big Data на базе Apache Kafka, Spark Streaming и Druid для площадки рекламных ссылок Outbrain, а затем на этом же кейсе рассматривали, зачем нужен Graceful shutdown в потоковой обработке больших данных. Сегодня в рамках этого примера разберем, как снизить нагрузку при потоковой передаче множества...

Сегодня поговорим про особенности перехода с локального Hadoop-кластера в облачное SaaS-решение от Google – платформу Dataproc. Читайте далее, какие 5 шагов нужно сделать, чтобы быстро развернуть и эффективно использовать облачную инфраструктуру для запуска заданий Apache Hadoop и Spark в системах хранения и обработки больших данных (Big Data). Шаги переноса Data...

В этой статье рассмотрим архитектуру и принципы работы системы хранения, аналитической обработки и визуализации больших данных на базе компонентов Hadoop, таких как Apache Spark, Hive, Tez, Ranger и Knox, развернутых в облачном Google-сервисе Dataproc. Читайте далее, как подключить к этим Big Data фреймворкам BI-инструменты Tableau и Looker, а также что обеспечивает...

Сегодня рассмотрим, как можно фильтровать потоки больших данных в Apache NiFi через типовой механизм SQL-запросов. Читайте далее, чем эта ETL-платформа стриминговой маршрутизации Big Data отличается от других систем, которые используют язык структурированных запросов вне СУБД, какие процессоры позволяют работать с потоковыми файлами (FlowFile) как с таблицами базы данных и при...

Сегодня поговорим про сохранение состояний при потоковой обработке больших данных с помощью Apache Spark и рассмотрим особенности Structured Streaming в новой версии этого популярного Big Data фреймворка. Читайте далее про Stateless и Stateful приложений в реальном времени, управление состояниями, связь DStream с RDD и UI в Spark Structured Streaming. Состояния в...