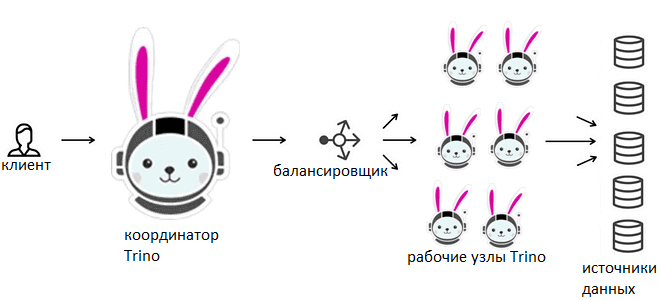
Как ускорить работу Trino при росте нагрузки и сэкономить на кластере при ее сокращении: автомасштабирование рабочих узлов и операций записи, а также настройка групп ресурсов. Масштабирование кластера Классическим способом справиться с растущими вычислительными нагрузками в гомогенной распределенной системе является горизонтальное масштабирование кластера. Это сводится к добавлению новых узлов, которые отвечают...
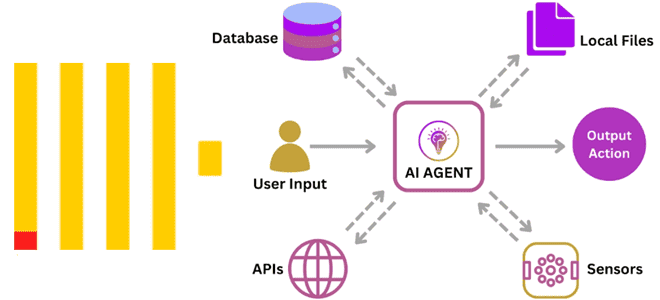
Зачем использовать ClickHouse для аналитики в реальном времени с агентами ИИ и как это сделать: современные вызовы внедрения LLM. Как реализовать ML-систему агентского ИИ с ClickHouse Продолжим разговор про агентский ИИ на основе LLM, когда ML-система не просто реагирует на запросы пользователя, а работает автономно, интеллектуально решая задачи без прямого...

Мы уже писали о том, как Trino работает с удаленными объектными хранилищами и файловыми системами. Сегодня поговорим о том, какие изменения выпущены в февральском релизе 2025 года, почему в Trino удалена поддержка доступа к Azure Storage, Google Cloud Storage, S3 и S3-совместимым файловым системам через Hive и что использовать вместо...

7 февраля 2025 года вышел очередной релиз ClickHouse. Знакомимся с его главными новинками: ускорение параллельного хэш-соединения, индексы MinMax на уровне таблицы, автоинкременты полей и улучшенное объединение таблиц с табличной функцией merge. Улучшение параллельного хэш-соединения в ClickHouse 25.1 В ClickHouse 25.1 добавлено 15 новых функций, 36 улучшений и 77 исправлений ошибок....

Особенности хранения и аналитической обработки JSON-документов в ClickHouse, MongoDB, Elasticsearch, DuckDB и PostgreSQL: объяснение бенчмаркингового теста. JSON в ClickHouse Недавно мы писали про бенчмаркинговое сравнение хранения и обработки JSON-данных в ClickHouse, MongoDB, Elasticsearch, DuckDB и PostgreSQL. В этом тесте, проведенном самими разработчиками ClickHouse, эта СУБД показала максимальную эффективность, которая обоснована...

Почему ClickHouse требует меньше места для хранения JSON-документов и быстрее выполняет аналитические запросы к ним по сравнению с MongoDB, Elasticsearch, DuckDB и PostgreSQL: бенчмаркинговый тест от разработчиков колоночной СУБД. Как Clickhouse делает быстрее агрегации в JSON-данных Хотя бенчмаркинговые тесты от вендоров редко бывают объективными, просматривать их довольно интересно. Недавно мне...
Почему Trino не заменит Flink, Spark и Airflow: границы применимости MPP-движка распределенного выполнения SQL-запросов к реляционным и нереляционным источникам данных. Почему Trino не заменит Flink, Spark и Airflow Хотя Trino отлично подходит для быстрой ad-hoc аналитики, позволяя SQL-запросами в реальном времени обращаться к различным базам данных, включая нереляционные хранилища и...

Как устроен механизм отказоустойчивого выполнения в Trino, чем политика повтора QUERY отличается от TASK, зачем настраивать диспетчер обмена на внешнее S3-совместимое хранилище и задавать коэффициент задержки перед повторными попытками выполнить SQL-запрос. 2 политики отказоустойчивого выполнения в Trino Будучи движком online-обработки больших объемов данных с помощью распределенных SQL-запросов, Trino должен иметь...
Для продвижения нашего нового курса для дата-инженеров Школа Больших Данных проводит очередной бесплатный митап для аналитиков, архитекторов, инженеров данных, разработчиков, DataOps- инженеров и тех, кто интересуется современными технологиями обработки данных. Trino – это распределенный SQL-движок с массово-параллельной архитектурой и открытым исходным кодом, предназначенный для работы с большими объемами данных в разных...
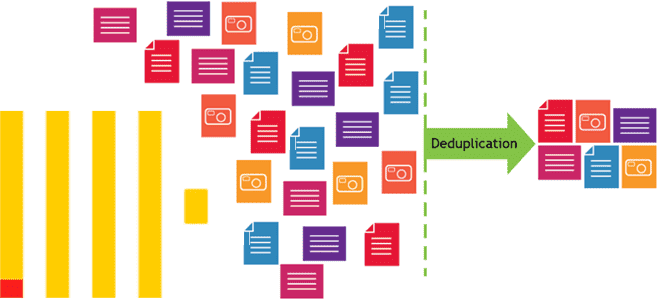
Почему в хранилище и витрину данных могут попасть дубли, чем это чревато и какие встроенные механизмы дедупликации есть в ClickHouse. Примеры OPTIMIZE-запросов и работы с движком ReplacingMergeTree. Причины дублирования данных и их последствия Дублирование данных в хранилищах и в витринах – довольно частая проблема в дата-инженерии. Это приводит к росту...
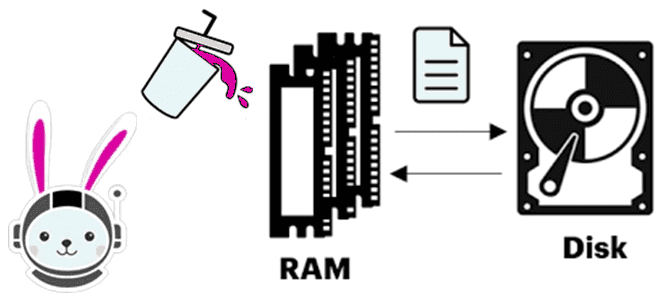
Что происходит, когда Trino не хватает памяти для выполнения SQL-запроса, как выполняется сброс промежуточных результатов на диск и почему механизм spill-to-disk не избавляет от OOM-ошибок. Spill-to-disk: сброс промежуточных результатов на диск в Trino Продолжая вчерашний разговор про нехватку памяти (OOM, Out Of Memory) в Trino, сегодня рассмотрим, как работает spill-механизм...

Почему в кластере Trino может возникнуть OOM-ошибка и как справиться с нехваткой памяти, оптимизировав SQL-запросы и настроив конфигурации: примеры и рекомендации. Причины OOM-ошибок в кластере Trino и как их устранить Для Trino, как и для многих JVM-приложений, характерны проблемы с управлением памятью, включая возникновение OOM-ошибок (Out Of Memory). Это связано...
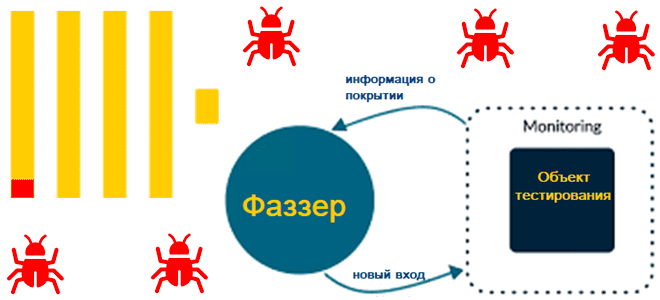
Что такое фаззинг-тестирование, зачем нужен новый фаззер для ClickHouse, и как BuzzHouse выявляет сложные проблемы и потенциальные уязвимости самой популярной колоночной СУБД, Что такое фаззинг-тестирование баз данных Поскольку база данных тоже программный продукт, перед выпуском в релиз она тестируется. Используемых при этом методов тестирования довольно много, и одним из них...

Что такое Apache Doris, как его использовать для построения хранилища данных и чем это отличается от ClickHouse. Сценарии применения и критерии выбора основы DWH. Что такое Apache Doris Недавно мы рассматривали, почему ClickHouse подходит для реализации хранилища данных на основе эталонной архитектуры Medallion благодаря поддержке более 70 форматов файлов, материализованным...
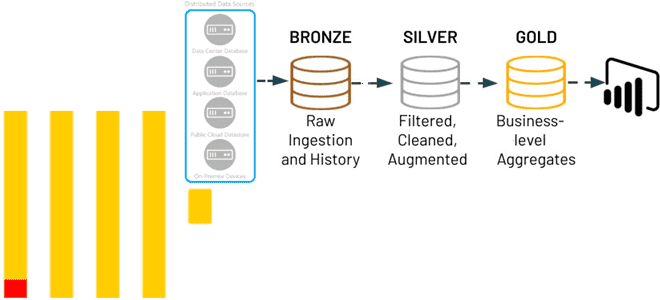
Почему ClickHouse подходит для архитектуры данных Medallion и как реализовать это слоистое хранилище средствами колоночной СУБД без сторонних инструментов: лучшие практики и примеры использования. 3 слоя архитектуры данных Medallion Слоистая архитектура, предложенная компанией Databricks, сегодня считается классикой для построения озер и хранилищ данных. Она предполагает реализацию 3-х уровней (слоев): Бронза,...
Где и как задавать настройки безопасного доступа клиента к кластеру Trino, каким образом обеспечить безопасность внутри кластера и защитить доступ к внешним источникам данных: примеры конфигураций. Как настроить безопасную работу кластера Trino По умолчанию в Trino не включены функции обеспечения безопасности. Однако, это можно настроить для различных частей архитектуры фреймворка:...

Как расширение Citus повышает производительность PostgreSQL, организуя распределенный кластер с помощью шардирования и почему этого недостаточно для эффективных OLAP-запросов как в Greenplum. Что такое Citus для PostgreSQL Поскольку Greenplum представляет собой массив отдельных баз данных PostgreSQL 12, работающих вместе для представления единого образа базы данных, у тех, кто знакомится с...
Зачем создавать разные проекции таблиц в базе данных и как это работает в Clickhouse: практический пример с агрегатным запросом. Возможности и ограничения механизма проекций в колоночной аналитической СУБД. Что такое проекции и как они реализованы в ClickHouse Поскольку основное назначение ClickHouse – аналитика больших объемов данных в реальном времени, это...
Зачем Trino использует внешние таблицы при запросах к данным в объектных хранилищам и удаленных файловых системах, чем они отличаются от внутренних и как повысить производительность таких SQL-запросов с помощью кэширования. Доступ из Trino к данным в объектных хранилищах Помимо реляционных и нереляционных баз данных, Trino позволяет делать распределенные запросы и...

Что общего между Trino и dbt, чем они отличаются и в каких случаях выбирать тот или иной инструмент для инженерии и анализа данных. Краткий ликбез для начинающего дата-инженера и аналитика. Сходства и отличия Trino и dbt Trino и dbt (Data Build Tool) — это два популярных инструмента с открытым исходным...